
Data annotation is the process of labeling or tagging data like images, text, audio, and video to make it understandable for machine learning models. It is the critical step that teaches an AI to recognize patterns, identify objects, and make accurate predictions. Without high quality labeled data, even the most powerful algorithms are useless.
Why Data Annotation Is Essential for AI Success

Imagine trying to teach a toddler what a “car” is using only blurry, unlabeled photos. It is impossible. They need clear examples and context. Someone has to point and say, "This is a car," "that's a wheel," and "that's a window." Data annotation does exactly this for artificial intelligence, providing the structured context machine learning (ML) models need to learn.
Raw data is essentially meaningless to an algorithm. An AI model for a self driving car does not inherently know a cluster of pixels is a pedestrian or a stop sign. It has to be trained on thousands of images where humans have painstakingly drawn boxes around pedestrians and labeled them correctly. This labeled dataset becomes the "ground truth", the textbook from which the AI studies.
The Foundation of Accurate AI Models
The quality of that textbook directly dictates how well the AI performs. If the labels are wrong, inconsistent, or incomplete, the model learns the wrong lessons. This leads to flawed predictions and unreliable results, a classic case of "garbage in, garbage out." High quality data annotation is the only way to prevent this.
Professional data annotation services provide the expertise and infrastructure to build these crucial datasets with precision and at scale. They bridge the gap between raw information and intelligent AI by focusing on key areas:
- Accuracy: Making sure every label correctly identifies an object or attribute based on strict project guidelines.
- Consistency: Applying the same rules across the entire dataset, even with multiple annotators working on it.
- Scalability: Managing massive volumes of data and delivering labeled datasets on schedule.
In essence, data annotation is not just a setup task; it is the fundamental process of translating human knowledge into a language machines can understand and learn from.
Turning Raw Data into Business Value
For any organization, the impact is direct and measurable. A retail company using AI to categorize its online catalog needs precise text and image annotation to ensure products show up in the right search results. In healthcare, radiologists rely on AI trained with expertly annotated medical images to help spot diseases earlier and more accurately.
Every one of these applications depends entirely on the quality of the initial data annotation. Working with a skilled service provider ensures this foundational work is done right, setting the stage for a reliable, high performing AI system that delivers real business value. It transforms what would be a costly and time consuming internal chore into a streamlined, expert led process.
Exploring the Core Types of Data Annotation
Data annotation is not a one size fits all job. Think of it less like a single task and more like a specialized toolkit, where every tool is designed for a specific purpose. Choosing the right data annotation service means picking the right tool to transform your raw data into a high value asset that your machine learning model can actually learn from.
The whole point is to turn unstructured information into a language that algorithms understand. For a self driving car to work, its AI needs to know the difference between a pedestrian, a stop sign, and another vehicle. Each of those distinctions is made possible by a specific type of annotation, which creates the "ground truth" the model uses to train.
Let’s break down the main categories of annotation that are powering today’s AI systems.
Image and Video Annotation
Visual data is easily one of the most common types that needs annotation, forming the bedrock of nearly all computer vision applications. Whether you're building an autonomous vehicle or a retail analytics platform, the goal is the same: teach an AI to "see" and interpret the world just like a human would. Prudent Partners offers a wide range of expert image and video annotation services designed to handle these complex needs.
The methods we use can vary a lot, depending on how much detail a project requires:
- Bounding Boxes: This is the go to technique for many projects. It is as simple as drawing a rectangle around an object of interest. For an e-commerce site, you might use bounding boxes to identify and tag every product in a lifestyle photo, training a model to help with automated inventory.
- Polygon Segmentation: When you are dealing with objects that have irregular shapes, a simple box just will not cut it. Polygon annotation means tracing the exact outline of an object, point by point. This level of precision is non negotiable in medical imaging, where an AI has to identify the precise border of a tumor in a CT scan.
- Semantic Segmentation: This is a much more advanced method where we assign a class label to every single pixel in an image. Imagine an aerial photo used for urban planning, every pixel could be classified as 'building,' 'road,' 'tree,' or 'water,' creating a highly detailed, color coded map for the AI to analyze.
- Keypoint Annotation: This technique involves marking specific points of interest on an object, usually to understand its shape or posture. It is a favorite for tracking human movement in sports analytics or identifying facial landmarks for emotion recognition software.
To give you a clearer picture, here is a quick summary of the most common annotation types and where they are used most often.
Common Data Annotation Types and Their Applications
| Annotation Type | Data Format | Primary Use Case Example | Key Industries |
|---|---|---|---|
| Bounding Boxes | Image/Video | Detecting products on a shelf for retail inventory. | Retail, E-commerce, Manufacturing |
| Polygon Segmentation | Image/Video | Outlining tumors or organs in medical scans. | Healthcare, Autonomous Vehicles, Agriculture |
| Semantic Segmentation | Image/Video | Classifying every pixel in a satellite image as land, water, or forest. | Geospatial, Autonomous Vehicles, Medical Imaging |
| Keypoint Annotation | Image/Video | Tracking body posture and joint movements for sports analytics. | Sports, Augmented Reality, Automotive |
| Named Entity Recognition | Text | Identifying names, dates, and locations in legal documents. | Finance, Legal, Healthcare |
| Sentiment Analysis | Text | Classifying customer reviews as positive, negative, or neutral. | Retail, Marketing, Customer Service |
| Audio Transcription | Audio | Converting customer support calls into searchable text. | Customer Service, Healthcare, Technology |
| Speaker Diarization | Audio | Identifying who is speaking and when in a recorded meeting. | Corporate, Legal, Media |
As you can see, the right technique depends entirely on the problem you are trying to solve. Each one provides a different level of detail and context for your AI model.
Text Annotation
Images are just one piece of the puzzle. Text data holds a massive amount of value, especially for understanding human language. Text annotation services get textual data ready for Natural Language Processing (NLP) models, allowing them to figure out intent, context, and even emotion. It is what lets a customer service chatbot know whether you're happy or frustrated.
Here are the key types of text annotation:
- Named Entity Recognition (NER): This involves spotting and categorizing key pieces of information in a block of text, like names, organizations, locations, or dates. Financial firms use NER all the time to pull crucial details from loan applications and analyst reports automatically.
- Sentiment Analysis: Here, annotators label text with sentiments like ‘positive,’ ‘negative,’ or ‘neutral.’ Brands use this to make sense of thousands of customer reviews and social media mentions in minutes, getting a real time pulse on public opinion.
- Text Classification: This is all about assigning a predefined category to a piece of text. A news organization, for example, could use it to automatically sort articles into buckets like 'Sports,' 'Politics,' or 'Technology.'
By applying these precise labeling techniques, organizations can unlock the powerful insights hidden within their unstructured text data, transforming customer feedback and internal documents into actionable intelligence.
Audio Annotation
From voice assistants to call center analytics, audio annotation is the critical step for training models that can understand and respond to human speech. The most fundamental task here is audio transcription, simply converting spoken words into written text.
But it usually goes much deeper than that. Take speaker diarization, which involves identifying and labeling who is speaking and when. This is incredibly useful for analyzing meeting recordings or multi person customer service calls. Annotators can also tag non speech sounds like a 'dog barking' or 'glass breaking' for home security systems or even identify emotional tones in a speaker's voice to build more advanced conversational AI. These granular labels provide the rich, contextual data that sophisticated audio models need to work effectively.
The Data Annotation Workflow From Start to Finish
Turning raw, unstructured data into a high quality, AI ready dataset is not a simple flip of a switch. It takes a methodical, disciplined process designed from the ground up to guarantee accuracy, consistency, and scale. The best data annotation services do not just label things, they follow a battle tested workflow that transforms data from a messy starting point into a polished, valuable asset for your machine learning models.
This workflow is about much more than just drawing boxes on images. It is built on clear communication, tough quality checks, and constant feedback loops that sharpen the output at every single step. Understanding this process gives you a clear window into what to expect when you bring on a professional annotation partner.
This simple visual breaks down the core journey of data, from its raw state all the way to its final job powering an AI model.
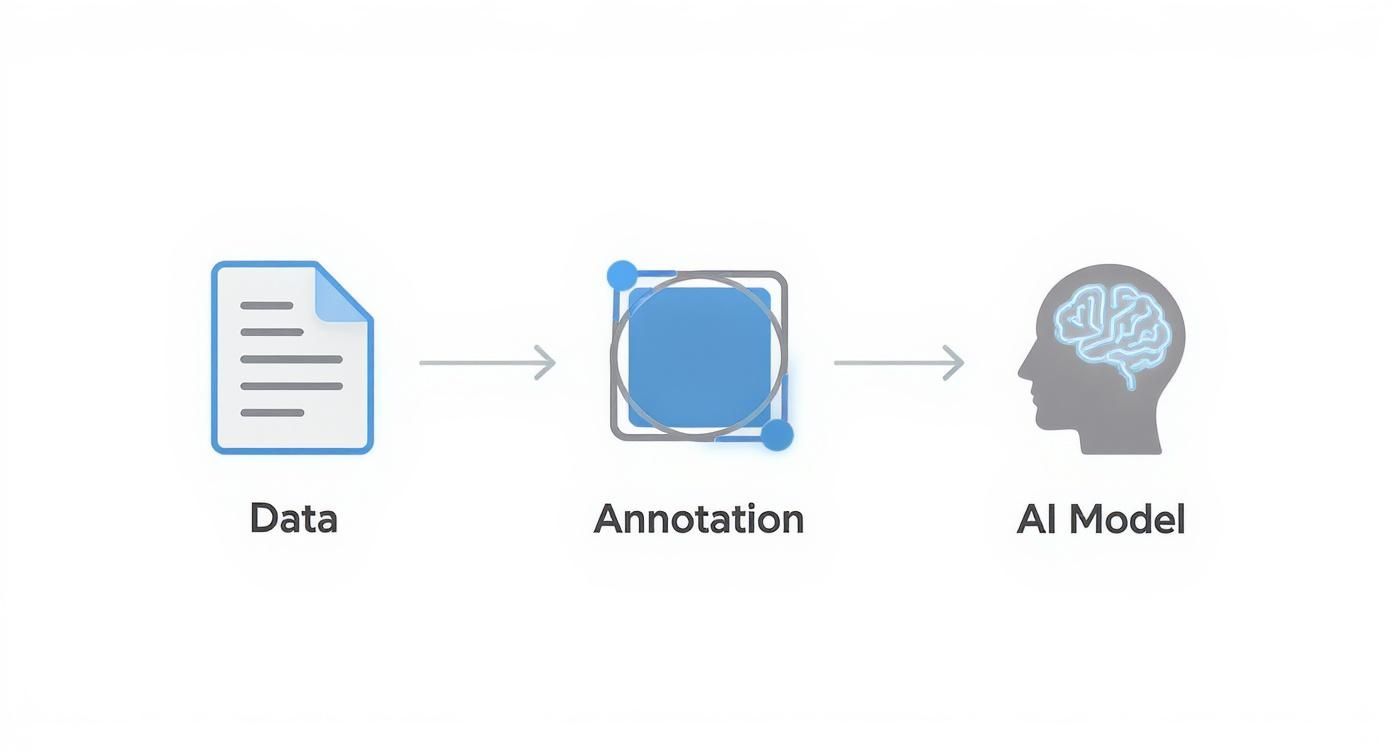
As you can see, it is a direct pipeline. Raw data goes in, annotation adds the critical intelligence, and a trained AI model comes out the other side.
Defining Project Guidelines
The entire operation kicks off with the most important step: defining the project guidelines. Think of this as the constitution for your project, the single source of truth that dictates every decision an annotator makes. It is packed with detailed instructions, examples of tricky edge cases, and clear rules to make sure every label is applied the exact same way across thousands, or even millions, of data points.
A well written guideline document leaves no room for guessing. For an e-commerce project, it might show exactly how to label a handbag that's partially hidden behind a mannequin. For a medical imaging task, it would define the precise anatomical boundaries for a tumor.
This initial setup phase is a deep collaboration. It is where your team and the annotation partner get on the same page about every objective and detail.
The Annotation and Review Cycle
Once the guidelines are locked in, the real annotation work begins. This is where the human-in-the-loop (HITL) model proves its worth. While automated tools can give you a head start, you absolutely need skilled human annotators to handle nuance, context, and complex scenarios that would completely stump a machine.
The workflow breaks down into a few key stages:
- Initial Annotation: Trained annotators get to work, applying labels to the raw data based on the guidelines. They use specialized software for tasks like drawing bounding boxes, creating precise polygons, or transcribing audio.
- Quality Assurance (QA) Review: A separate team of senior reviewers steps in to examine a sample of the annotated data. They are looking for accuracy, consistency, and perfect adherence to the guidelines, flagging any errors for correction.
- Feedback and Iteration: The QA team does not just fix mistakes, they provide direct feedback to the original annotators, explaining what went wrong and clarifying the rules. This feedback loop is what makes annotators better and ensures quality stays high over the long haul.
- Client Review and Final Approval: You get the final say. A batch of completed data is sent to your internal team for review. This is your chance to validate the quality and provide any last minute feedback, which helps make the guidelines even stronger for the next batch.
This cycle of human expertise layered with multiple reviews is the engine that produces high accuracy data. It elevates a simple labeling task into a disciplined, industrial strength quality assurance process.
Leveraging the Right Tools
The speed and accuracy of this whole workflow hinge on the tools being used. It is no surprise that the global data annotation tools market, valued at USD 1.02 billion in 2023, is projected to hit USD 5.33 billion by 2030. You can discover more insights about these market trends on Grand View Research.
These platforms are far more than just fancy drawing programs. They come loaded with features designed to speed up the workflow and boost quality, including:
- AI-Assisted Labeling: Pre-trained models can take a first pass at labeling, leaving human annotators to simply verify and adjust the suggestions.
- Performance Analytics: Managers can track annotator speed, accuracy, and consistency in real time to spot who needs more training.
- Collaborative Workspaces: Teams can ask questions, discuss tricky examples, and get clarification on guidelines right inside the platform.
By combining a structured workflow, a strong human-in-the-loop model, and advanced tools, professional data annotation services build a reliable and scalable data pipeline that fuels winning AI projects.
Ensuring Data Quality and Security in Annotation

In artificial intelligence, two truths are absolute: garbage in, garbage out, and a single data breach can be catastrophic. The success of any AI model is tied directly to the integrity and security of its training data. This makes choosing a data annotation service a high stakes decision that demands intense scrutiny of both quality assurance (QA) practices and security protocols.
High quality data is not just about getting the labels right; it's about consistency, reliability, and sticking to the nuances of your project guidelines. In the same way, real security is more than a firewall. It is a complete system of compliance, access controls, and secure data handling that protects your most sensitive information at every step.
Advanced Quality Assurance Methods
The best data annotation services don't just label data, they validate it through a multi layered quality assurance process. This system is built to catch errors, enforce consistency, and produce datasets that meet the highest standards. A partner’s commitment to QA is a direct reflection of their commitment to your AI model's performance. As we have covered before, data quality offers a true competitive edge in AI.
Here are the key QA methods to look for:
- Inter-Annotator Agreement (IAA): This metric measures how consistently different annotators label the same piece of data. High IAA scores tell you the project guidelines are clear and the team is on the same page, which is essential for building a uniform dataset.
- Gold Sets: A "gold set" is a small sample of data that's already been perfectly labeled. This set is used to test and benchmark annotator accuracy over time, acting as a reliable quality control standard.
- Consensus and Review: In this setup, several annotators label the same data. Any disagreements are automatically flagged for a senior annotator or project manager to resolve. This collaborative approach helps clear up ambiguities and refine the guidelines for tricky edge cases.
A rigorous QA framework is the only way to build trust in your training data. It ensures that the "ground truth" you are feeding your AI model is reliable, accurate, and ready for production.
Uncompromising Security and Compliance Protocols
As data becomes more valuable, it also becomes a bigger target. The global market for data annotation services is exploding, valued at USD 1.89 billion in 2024 and projected to hit USD 10.07 billion by 2032. You can read the full research on this market expansion from Verified Market Research. With that kind of growth comes a massive responsibility to protect the data being handled.
A partner you can trust must prove their deep commitment to security through established protocols and compliance with international standards. This is non negotiable, especially if you're working with personal, medical, or financial information.
Essential Security Measures for Data Protection
When you're vetting potential partners, you need to see concrete proof of their security posture. This means certifications, documented policies, and a clear understanding of the regulations that matter to your industry.
Here are the key security elements to verify:
- Regulatory Compliance: The provider must adhere to crucial regulations like GDPR (for protecting EU residents' data) and HIPAA (for safeguarding U.S. health information). Compliance is a baseline requirement, not a bonus feature.
- Secure Data Handling: Your data must be encrypted both in transit (while being transferred) and at rest (while stored). Ask them to specify their encryption methods and data storage policies.
- Strict Access Controls: Not everyone on the team needs access to all of your data. A secure provider uses role-based access control (RBAC) to ensure individuals can only see the information necessary for their specific task.
- Confidentiality Agreements: Every single person handling your data, from the annotators to the project managers, must be under a strict non-disclosure agreement (NDA). This legally binds them to confidentiality.
By prioritizing both meticulous QA and uncompromising security, you can build a partnership that delivers accurate data and protects your organization from serious risk. This dual focus is the hallmark of a top tier data annotation service.
How to Choose the Right Data Annotation Partner
Picking the right provider for your data annotation is one of the most important calls you will make for your entire AI initiative. This is not just about comparing price sheets; it is about finding a real partner who gets your goals, protects your data, and delivers the rock solid quality your models need to perform. The wrong choice can send you spiraling into costly rework, blown timelines, and models that just do not work.
To get this right, you need a framework that looks at a provider from every angle. A true partner invests time upfront to understand exactly what you need and has the proven systems to deliver accurate, secure, and scalable results. Think of them as an extension of your team, not just a vendor ticking boxes.
Evaluating Domain Expertise and Experience
Your first filter should always be domain expertise. A provider that has already navigated projects in your industry, whether it is healthcare, e-commerce, or autonomous vehicles, will already speak your language. They'll understand the unique challenges and subtle nuances of your data, and that knowledge translates directly into better annotations.
For example, you can't have just anyone annotating medical images; you need a team with a background in anatomy to spot subtle abnormalities. In the same way, a provider labeling financial documents has to understand industry specific jargon to perform accurate named entity recognition.
When you choose a partner with relevant experience, you slash the learning curve and the time spent explaining foundational concepts. They can start adding real value from day one.
Scrutinizing Quality Assurance Processes
A provider’s quality assurance (QA) framework is the backbone of their service. Don't fall for vague promises of "high quality." You need to see a documented, multi layered process that guarantees both accuracy and consistency. Ask potential partners to walk you through their specific QA methodologies and the metrics they track.
Here are a few key questions to dig into:
- How do you measure Inter-Annotator Agreement (IAA)? This tells you how consistently their team is applying your guidelines.
- Do you use gold sets for benchmarking? This shows they are committed to ongoing accuracy checks, not just a one and done setup.
- What does your review and feedback process look like? A strong partner has a tight loop for catching errors, making corrections, and retraining annotators.
A transparent QA system is a huge green flag. It signals a mature, reliable service and shows they are confident they can meet, and exceed, your quality standards.
Confirming Scalability and Flexibility
As your AI project grows, your data needs will explode. The partner you choose has to be able to scale their operations right alongside you, without letting quality or speed slip. Ask them about their team size, how they handle sudden spikes in data volume, and what their operational model looks for hitting tight deadlines.
A provider with a large, well trained workforce and efficient project management systems can adapt as you move from a small pilot project to a massive production deployment. This flexibility is what separates a short term vendor from a long term partner. For a more detailed breakdown of what to look for, our guide on how to evaluate data annotation companies before outsourcing offers an actionable checklist.
Understanding Pricing Models and Transparency
Finally, you need to get a handle on the different pricing models to find one that fits your budget and project. While costs will always vary based on complexity and volume, the most important thing is transparency. A trustworthy partner will give you a clear, detailed quote with no hidden fees or surprises down the road.
The most common pricing structures you will see are:
- Per Label/Annotation: You pay for each individual label created. This is great for projects where the number of objects per image or document varies a lot.
- Per Unit: Costs are calculated per image, document, or minute of audio. This works well when the workload for each item is fairly consistent.
- Per Hour: You are billed based on the time annotators spend working on your project. This is perfect for complex or exploratory tasks where the scope isn't fully locked down.
Always, always ask for a pilot project or a free trial. It's the single best way to evaluate their quality, communication, and overall workflow before you sign a long term contract. It lets you see for yourself if you have truly found a partner who will help your AI initiative succeed.
The Business Impact of Professional Data Annotation
Investing in professional data annotation is not just a technical task on a checklist; it's a strategic move that delivers a clear and measurable return. The line between precisely labeled data and real world business outcomes is direct and powerful. Think of high quality annotation as a catalyst, it speeds up model development, supercharges AI accuracy, and ultimately helps you build far better customer experiences.
This foundational work drives efficiency and carves out a serious competitive advantage. For an e-commerce platform, it means turning accurately tagged product images into a recommendation engine that actually increases the average order value. A logistics company can slash fuel costs and optimize delivery routes by training its AI on perfectly mapped geospatial data. In both scenarios, the upfront investment in quality data pays for itself many times over through smarter operations.
Accelerate Development and Boost Accuracy
Bad data is the single biggest bottleneck in the AI development lifecycle. When a model underperforms, data science teams can waste weeks troubleshooting, only to trace the problem back to inconsistent or just plain wrong labels. Professional data annotation services cut through that mess from day one. They deliver clean, reliable datasets that let your team focus on what they do best: refining models, not cleaning up data.
This immediately translates to a faster time to market for your AI initiatives. It also means your AI systems actually work as intended out in the real world.
- Higher Model Confidence: With accurate ground truth data, your models make predictions with greater certainty, slashing the risk of expensive errors.
- Fewer Edge Case Failures: Expert annotators are trained to handle tricky, ambiguous scenarios. This ensures your model is robust and does not stumble when it encounters unexpected inputs.
Drive Revenue and Enhance Customer Experience
At the end of the day, the goal of any AI system is to create business value. Professional annotation gets you there by powering applications that improve the customer journey and open up new revenue streams. Imagine a chatbot that truly understands what a customer wants because it was trained on expertly annotated conversational text. That leads to happier customers and lower support costs.
The demand for this work is exploding. The global data annotation outsourcing market is on track to hit USD 1.2 billion in 2025 and is projected to skyrocket to USD 11.5 billion by 2034. You can discover more insights about these market trends from USD Analytics.
This growth is not just a number, it is a clear signal that businesses recognize the immense competitive edge that high quality data provides. Outsourcing this critical function is quickly becoming the standard. When you partner with an expert provider, you ensure your AI initiatives are built on a rock solid foundation, ready to deliver real, tangible business impact.
Common Questions About Data Annotation Services
Diving into data annotation can bring up a lot of practical questions, especially around budgeting and timelines. Getting straight answers is key to setting the right expectations and making sure your AI project starts on solid ground. Here are some of the most common questions we hear.
What Factors Determine Project Cost?
There's no single price tag for data annotation, it's not a one size fits all service. The final cost really boils down to a few key variables, and the biggest one is complexity. For instance, drawing simple bounding boxes around cars in a street scene is a world apart from performing pixel perfect polygon segmentation on a medical scan. The latter requires deep domain expertise and is naturally more expensive.
Other major factors include:
- Data Volume: More data is not always just more of the same. While larger projects often come with volume discounts, a massive dataset needing hundreds of annotators also means more project management overhead.
- Quality Requirements: Hitting 99%+ accuracy is not an accident. It requires multiple layers of quality assurance, including reviews by subject matter experts, which costs more than a project aiming for a 90% baseline.
- Turnaround Time: Need it yesterday? Tight deadlines that demand 24/7 work or pulling in extra resources will always come at a premium.
A good partner will be completely transparent about these factors. They should be able to give you a clear quote that ties every dollar back to the complexity, scale, and quality your project demands.
How Long Does an Annotation Project Take?
Just like cost, project timelines can vary wildly. It all depends on the same core factors. A small pilot project to classify a few thousand images might take just a week to turn around.
On the other hand, think about a large scale video annotation project for an autonomous vehicle. We're talking millions of frames, complex object tracking, and intense QA. That kind of effort can easily stretch over several months.
Your provider's own capacity and efficiency play a huge role here, too. A seasoned service with a large, trained workforce and streamlined tools will process data much faster than a smaller or less experienced team. Don't forget the initial setup phase, creating crystal clear guidelines is critical to avoiding delays and costly rework down the line.
Should I Use an In-House Tool or a Managed Service?
This is the classic "build vs. buy" debate. Going the in house route with a labeling tool gives you total control, but it also means your team is on the hook for everything: managing the workforce, training them, and running all the quality checks. For a small, non critical R&D project where a couple of data scientists can handle the work, this might be fine.
But when you need scale, accuracy, and efficiency, a managed data annotation service is the way to go. A dedicated provider takes care of the entire pipeline, from recruiting and training annotators to managing complex workflows and guaranteeing quality. This frees up your highly skilled (and expensive) data scientists to focus on what they do best: building and refining your models. That's a much better use of their time and your budget.
Ready to build a reliable, high quality data pipeline for your AI initiatives? Prudent Partners provides expert data annotation services with a proven track record of delivering 99%+ accuracy. We combine a dedicated team of skilled analysts, a robust multi layer QA process, and transparent project management to turn your raw data into a dependable asset. Connect with us today for a customized solution and see the difference precision makes.