
Data tagging is the process of adding descriptive labels or ‘tags’ to raw data, providing the context that machine learning models need to make sense of the world. This critical step transforms chaotic, unstructured information into intelligent fuel for AI systems, and it directly shapes how accurate and reliable those systems become. Without precise data tagging, even the most sophisticated algorithms operate on guesswork.
Why Data Tagging Is Your AI's Secret Weapon
Imagine handing a new chef a pantry full of unlabeled jars and asking them to cook a five-star meal. They might guess what is inside, but the final dish would be a complete gamble. Raw, untagged data presents an AI system with the exact same problem: a mountain of information with zero context, making it impossible for an algorithm to learn anything useful.
Data tagging acts as the master organizer for that pantry. It systematically attaches meaningful metadata to every piece of data, whether an image, a sentence, or a single point in a 3D scan. This foundational process translates human expertise into a machine-readable format, creating the high-quality training datasets that every successful AI is built upon.
The Foundation of AI Accuracy
Ultimately, the performance of any AI model is a direct reflection of the data it was trained on. The old saying holds true: garbage in, garbage out. High-quality, meticulously tagged data is not just a "nice to have"; it is the single most important factor in building AI you can trust.
These tags provide the "ground truth" the model learns from. If you are training an AI to spot different types of vehicles in traffic footage, the data tagging process involves drawing bounding boxes around cars, trucks, and buses and tagging them with the correct label. Every correct tag reinforces the model’s understanding of what a "car" or "bus" looks like.
Precise data tagging is not just a preliminary step; it is an ongoing commitment to quality that determines the absolute ceiling of your AI's potential. Investing in high-accuracy data from day one saves significant time and resources on expensive model retraining down the line.
The cumulative effect of this precision is massive. A model trained on a dataset with 99%+ accuracy will perform its job reliably in the real world, whether that is identifying cancerous cells in a medical scan or spotting defective products on a production line. Conversely, a model trained with sloppy, inconsistent tags will inherit every one of those flaws, leading to poor decisions and, ultimately, a failed project.
From Raw Information to Actionable Intelligence
Data tagging does more than apply labels to objects; it builds a rich, contextual map that allows AI to perform incredibly complex tasks. It is the engine that turns raw, meaningless information into genuinely actionable intelligence. For any business serious about innovation, this transformation is crucial.
Consider the measurable impact:
- Improved Model Performance: Well-tagged data leads to higher accuracy, smarter predictions, and far fewer false positives or negatives.
- Reduced Bias: A thoughtful data tagging strategy is your best defense against bias. It ensures training data is diverse and representative, which helps you avoid building unfair or discriminatory AI systems.
- Enhanced Scalability: Creating a clear and consistent tagging framework from the start means your AI projects can grow efficiently without a decline in quality as datasets expand.
Ultimately, data tagging is the essential bridge between a pile of raw data and a high-performing AI system. It provides the structure, context, and quality that machines need to learn, adapt, and create real business value. Without it, your AI is just a powerful engine with an empty fuel tank.
Building Your Data Tagging Blueprint
You would never build a house without a detailed blueprint, and the same logic applies to data tagging. A successful project is the direct result of a carefully designed plan. Without one, you invite inconsistency, costly rework, and low-quality data that will cripple your AI model before it even gets started.
This process begins by establishing your tagging taxonomy. Think of this as the official rulebook for your project. It is a document that defines every single tag, what it means, and exactly when and how it should be applied. A solid taxonomy removes guesswork, ensuring every annotator makes consistent decisions, whether they are sitting next to you or on the other side of the world.
The diagram below shows how raw, messy information is transformed into structured, AI-ready data, with tagging serving as the critical middle step.
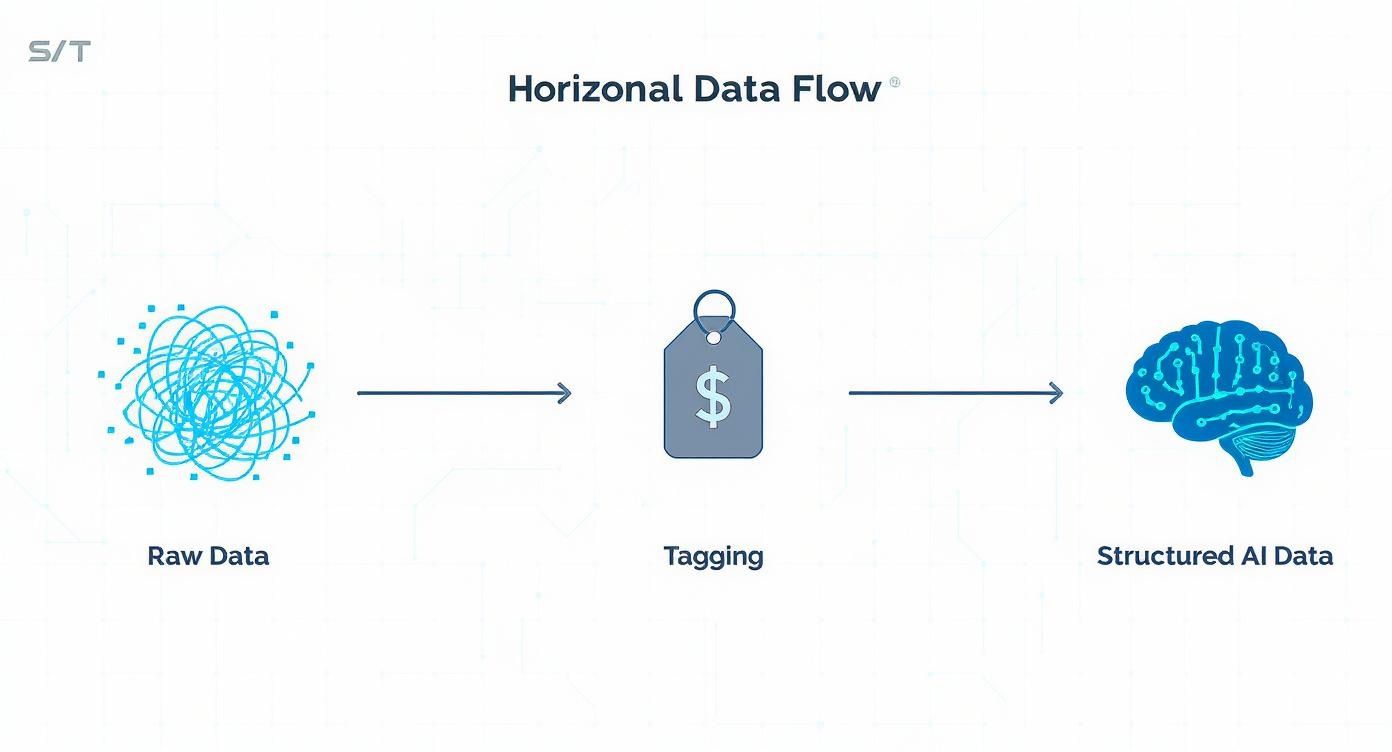
As you can see, tagging is the bridge that turns chaotic inputs into the organized, coherent datasets that intelligent algorithms depend on.
Designing a Clear Tagging Taxonomy
Your taxonomy is the single source of truth for your entire annotation team. Imagine an e-commerce company trying to build a recommendation engine. If the taxonomy is weak, one annotator might tag a shirt as "blue," another as "navy," and a third as "royal blue." This sends mixed signals and confuses the AI.
A well-defined taxonomy stops this chaos before it starts by providing crystal-clear guidelines:
- Color: Use a specific hex code or a predefined list (e.g., #000080 for Navy Blue). No more guesswork.
- Style: Create mutually exclusive categories like "V-Neck," "Crewneck," or "Polo."
- Material: Specify exact terms like "100% Cotton" or "Cotton/Poly Blend," and define rules for percentages.
This level of precision ensures every product is categorized the same way, every time. The result is a clean, reliable dataset. Without it, your data quality suffers, and your AI model’s performance will nosedive.
A robust taxonomy is more than just a list of labels; it is a communication tool that aligns your entire data operation. It ensures every tag applied contributes to a unified, high-quality dataset, making your AI smarter and more reliable with every piece of information it processes.
Selecting the Right Tagging Tools
Once your taxonomy is locked in, it is time to pick the right tools for the job. The market is full of platforms, and the best choice often comes down to balancing precision, speed, and budget.
Manual platforms give you granular control, making them perfect for complex tasks that need human judgment, like detecting subtle sarcasm in customer reviews. On the other end of the spectrum, automated tagging tools use algorithms to apply tags at lightning speed but can sometimes miss the mark on accuracy.
Many teams find the sweet spot with semi-automated or "human-in-the-loop" systems that combine the best of both worlds. For a closer look, our guide on the best data labeling tools can help you evaluate which platform is right for your project.
The Irreplaceable Human Element
Ultimately, technology is only one part of the puzzle. The quality of your tagged data depends on the skill of your human annotators. A state-of-the-art tool in the hands of an untrained team will still produce poor-quality data.
This is why investing in skilled annotators with domain expertise and a rigorous quality assurance (QA) process is completely non-negotiable.
A well-trained team understands the nuances of the taxonomy and can make consistent calls on ambiguous data points. This human expertise is then amplified by a strong QA process, where work is reviewed and validated to catch errors before they can contaminate your dataset. Achieving high accuracy at scale is not just about having more people; it is about having the right people working within a proven quality framework.
How Data Tagging Drives Real-World Innovation

It is easy to talk about data tagging in the abstract, but its true power comes to life when you see it in action. In the real world, this meticulous work is the invisible engine powering some of our most impressive technological leaps. It is what turns raw, meaningless information into tangible, game-changing outcomes that are already part of our daily lives.
The sheer impact of this work is fueling incredible growth. The global data labeling market, currently valued at around USD 3.77 billion, is expected to skyrocket to USD 17.10 billion by 2030. This is not just hype; it is a direct response to the massive demand for high-quality training data in critical sectors like healthcare, e-commerce, and autonomous systems. You can find more on these market drivers in various industry intelligence reports.
Let’s step away from the theory and look at how data tagging is making a real difference in these high-stakes fields.
Revolutionizing Healthcare With Precision Diagnostics
In medicine, accuracy is not just a performance metric; it is a matter of life and death. Data tagging is at the heart of AI-driven healthcare, giving machines the ability to spot diseases with a level of detail that complements human expertise. Without it, building reliable diagnostic tools would be impossible.
Consider analyzing an MRI scan. An expert radiologist might see subtle variations that signal a tumor. To teach an AI to do the same, each of those variations must be painstakingly tagged. Annotators use methods like semantic segmentation to trace the exact pixels of abnormal tissue, tagging them as "malignant," "benign," or "inflammation."
This detailed data tagging creates a massive, high-quality dataset that teaches the AI to recognize these patterns on its own. The results are profound:
- Earlier Detection: AI models trained on precisely tagged data can spot signs of disease far earlier than the human eye, dramatically improving patient outcomes.
- Reduced Workload: These tools can prescreen thousands of images, freeing up radiologists to focus their skills on the most complex and critical cases.
- Greater Accuracy: By learning from a huge library of expert-tagged examples, AI helps reduce the rate of false positives and negatives.
Enabling Safer Autonomous Vehicles
For a self-driving car, the world is a constant flood of sensor data from cameras, LiDAR, and radar. To navigate a busy street safely, its AI must understand everything happening around it in an instant. This is where data tagging becomes a mission-critical safety function.
Every single object a car might encounter, from a pedestrian to a pothole, must be identified, classified, and tracked. Human annotators apply layers of tags to the raw sensor data:
- Bounding Boxes: Drawing rectangles around and tagging pedestrians, cyclists, and other cars.
- Polygonal Segmentation: Tracing the exact shape of lane markings, crosswalks, and curbs.
- Semantic Segmentation: Classifying every pixel in a scene as "road," "sidewalk," "sky," or "building."
The safety of an autonomous vehicle is a direct function of the quality of its training data. Every correctly tagged traffic light, pedestrian, and road sign builds a more reliable and trustworthy AI that can make split-second decisions to prevent accidents.
This incredibly detailed tagging teaches the car’s AI to perceive and react to its environment with superhuman speed. Without this foundational work, a self-driving car would be completely blind. The precision of this data tagging is what determines whether the system can operate safely in our chaotic, unpredictable world.
Powering Personalized E-commerce Experiences
In the fiercely competitive world of online retail, personalization is the name of the game. Those recommendation engines that seem to read your mind? They are powered by incredibly detailed product tagging that goes way beyond simple labels like "shirt" or "pants."
A smart e-commerce platform uses a deep, complex taxonomy to tag products with dozens of attributes. A single sweater, for example, might be tagged with its material ("cashmere blend"), neckline ("crewneck"), fit ("slim"), style ("preppy"), and even the occasion it is suited for ("business casual"). This rich metadata is the fuel for the store's recommendation algorithms.
When a customer buys that "slim fit, cashmere blend, crewneck" sweater, the AI learns their preferences. It can then surface other products with similar tags, creating a highly personalized shopping experience that keeps customers engaged and drives more sales. In this way, meticulous data tagging turns a static product catalog into a dynamic, intelligent sales tool that anticipates what a customer wants before they even know it.
The table below summarizes how these industries and others are putting data tagging to work.
Data Tagging Applications by Industry
| Industry | Use Case Example | Business Impact |
|---|---|---|
| Healthcare | Annotating MRIs and X-rays to detect tumors and fractures. | Faster diagnostics, reduced radiologist workload, and improved patient outcomes. |
| Automotive | Labeling LiDAR and camera data to identify pedestrians, vehicles, and lane markings for autonomous vehicles. | Enhanced safety systems, accelerated development of self-driving technology, and fewer accidents. |
| E-commerce & Retail | Tagging product images with detailed attributes (style, material, fit) to power recommendation engines. | Increased customer engagement, higher conversion rates, and improved inventory management. |
| Agriculture | Segmenting satellite imagery to monitor crop health, identify weeds, and optimize irrigation. | Higher crop yields, reduced resource waste, and more sustainable farming practices. |
| Geospatial | Classifying LiDAR point clouds to create 3D maps for urban planning and disaster management. | More accurate infrastructure planning, better emergency response, and improved environmental monitoring. |
From saving lives to making our roads safer and shopping easier, the applications are as diverse as the data itself. Each use case demonstrates that high-quality tagging is not just a technical step; it is the foundation for real-world value.
Achieving Gold Standard Quality in Your Data
When it comes to training an AI, there is no such thing as "good enough" data. Garbage in, garbage out is not just a saying; it is a reality. Low-quality inputs will always produce a low-quality model, wasting time, money, and leading to results you cannot trust. This is why a rigorous quality assurance (QA) framework is not just a nice-to-have; it is the most critical part of any data tagging project. It is what turns a decent dataset into a gold-standard one.
The entire process hinges on one thing: measurable quality. While everyone wants accuracy, you need to dig deeper into the key metrics that define a truly high-quality dataset. Without clear benchmarks, you are flying blind, hoping your tagged data is good enough to build a powerful AI system.

This demand for precision is a huge driver of market growth. The AI data labeling market is expanding fast because enterprises need highly accurate and scalable ways to tag all kinds of data. You can explore a full analysis of this trend in Technavio's market report.
Defining Key Quality Metrics
To build a QA process that actually works, you have to know what you are measuring. The best quality frameworks move past vague goals and zero in on specific, quantifiable metrics that give you a clear picture of your data’s health.
-
Accuracy: This one is the most straightforward. It measures the percentage of tags that are correct when checked against a "ground truth" or an expert-verified answer. An accuracy of 99% means that 99 out of every 100 tags are correct. Simple as that.
-
Precision and Recall: These two metrics give you a much more nuanced view of performance, especially for classification tasks. Precision measures how relevant your results are (of all the items tagged as "cat," how many were actually cats?). Recall, on the other hand, measures how many of the total relevant items were found (of all the cats in the dataset, how many did we successfully tag?).
These are not just numbers on a dashboard; they are direct indicators of how reliable your final AI model will be.
The Role of Inter-Annotator Agreement
So, how do you make sure everyone is on the same page when multiple people are tagging your data? The answer is Inter-Annotator Agreement (IAA). This metric measures how consistent different human annotators are when they tag the same piece of data. A high IAA score tells you your tagging guidelines are crystal clear and your team is applying them consistently.
IAA is the industry benchmark for reliability. It proves that your data quality is not dependent on one person’s opinion but is the result of a standardized, repeatable process that produces consistent outcomes across the entire team.
If your IAA score is low, that is a major red flag. It means your guidelines are probably ambiguous or your annotators need more training. Catching this early is essential to prevent widespread inconsistencies from poisoning your entire dataset. For practical tips, our guide on creating clear annotation guidelines is a fantastic place to start.
Implementing a Multi-Layered QA Workflow
A single quality check is never enough. The most effective data tagging operations use a multi-layered QA workflow that builds quality into every single step. This approach is designed to catch errors early, minimize expensive rework, and ensure the final dataset is as close to perfect as possible.
A typical multi-layered workflow includes:
- Automated Validation: This is your first line of defense. Automated scripts run checks for basic mistakes like incorrect formatting, missing tags, or values that fall outside a predefined range.
- Peer Review: Here, one annotator’s work is reviewed by a colleague. This process is great for catching subjective errors and interpretation issues that an automated check would completely miss.
- Expert or Consensus Review: For the most critical or ambiguous data points, a final review is done by a domain expert or through a consensus model where multiple senior annotators must agree on the final tag.
This layered approach ensures that by the time data gets the final stamp of approval, it has been rigorously vetted for both objective correctness and subjective consistency. It creates a foundation for your AI that you can actually trust.
Choosing the Right Data Tagging Partner
Picking a third-party partner for your data tagging is a huge decision. It is one that directly impacts how well your AI model performs, how reliable it is, and whether it succeeds at all. The right partner becomes a true extension of your team, bringing industry knowledge and operational discipline. The wrong one can introduce critical errors, blow up your timelines, and sink the entire project.
Making a smart choice means looking past a simple price tag. You need to evaluate potential partners on a much deeper, more strategic level. The goal is to find a team whose process, expertise, and dedication to quality line up perfectly with what your project needs. This ensures the data you get back is not just tagged; it is tagged correctly, consistently, and securely.
Verifying Domain Expertise and Scalability
First things first: does the potential partner actually understand your industry? Generic data tagging experience will not cut it when you are dealing with nuanced data like medical scans or complex financial reports. A partner with proven domain expertise will understand the subtle context of your data, leading to far more accurate and useful tags from day one.
When you are vetting a vendor, ask to see case studies or examples of projects similar to yours. This is your proof that they have a real track record in your specific field. Beyond that initial expertise, you have to look at their ability to scale. Your data needs are almost guaranteed to grow, and your partner must have the infrastructure and trained workforce to handle more volume without letting quality slip.
A key question to ask is how they maintain 99%+ accuracy as a project balloons from thousands of data points to millions. A mature partner will have a clear, documented process for training new annotators to meet that demand while sticking to strict quality standards.
Confirming Security and Compliance Protocols
Handing over sensitive data is all about trust, but that trust needs to be backed by serious security protocols. Your data tagging partner must show an ironclad commitment to protecting your data. This is non-negotiable, especially if you are in a regulated industry.
Look for these key indicators of a secure operation:
- Certifications: Check for credentials like ISO 27001, which confirms they follow international standards for information security.
- Compliance: Make sure they are fully compliant with relevant regulations like GDPR for personal data or HIPAA for protected health information.
- Confidentiality: A willingness to sign a comprehensive Non-Disclosure Agreement (NDA) is the absolute baseline for any serious discussion.
These measures ensure your proprietary information is locked down through the entire process, from the initial transfer to the final delivery.
A partner’s approach to security is a direct reflection of their professionalism. Robust compliance and certifications are not just checkboxes; they are proof of an operational discipline that extends to every aspect of their work, including data quality.
The Pilot Project and Service Level Agreements
Talk is cheap. Real-world performance is what actually matters. The single best way to put a potential partner to the test is to start with a small, paid pilot project. This trial run gives you priceless insight into their real workflow, their communication style, and most importantly, the quality of their output. A pilot lets you see how they handle your actual data before you sign a long-term contract.
Once you are confident in their abilities, the last step is to lock in a clear Service Level Agreement (SLA). An SLA is the formal document that lays out specific, measurable expectations for the partnership. It should clearly define key performance indicators (KPIs) like:
- Accuracy Rates: The minimum acceptable percentage of correctly tagged data.
- Turnaround Times: Agreed-upon deadlines for delivering batches of work.
- Communication Protocols: How and when you will get progress updates.
An SLA builds a transparent and accountable relationship, making sure both sides are on the same page about what success looks like. Prudent Partners’ comprehensive data annotation services are built on this foundation of transparency and measurable quality, ensuring we deliver results that meet your exact specifications.
Your Data Tagging Questions Answered
Getting into data tagging brings up a lot of questions, especially when you are kicking off a project or trying to scale up. Clear, straight answers are what you need to make smart decisions that actually help your business. Here are a few of the most common questions we hear from teams diving into the world of data tagging.
What Is the Difference Between Data Tagging and Data Labeling?
You will often hear "data tagging" and "data labeling" used like they are the same thing, but there is a key difference in the level of detail. Getting this right is crucial for scoping out your AI training data project.
Think of it like organizing your digital photos.
Data labeling is like putting a simple title on a whole folder, like "Vacation Photos." It is a broad category that gives you the general idea of what is inside.
Data tagging, however, is like going into that folder and adding specific keywords to each photo. A single picture might get tags like "beach," "sunset," "Spain," "family," and "2023." Tagging adds that rich, multi-layered context AI models need to understand nuance and specific details.
Should We Handle Data Tagging In-House or Outsource It?
Deciding between building an in-house team or working with a specialized partner is a big strategic choice. There is no single right answer; it really depends on your project’s size, complexity, and the resources you have on hand.
An in-house team can work great for smaller, well-defined projects, especially if you already have people with the right skills and time. This route gives you direct control and is often a good fit for initial experiments or projects with highly sensitive data that cannot leave your walls.
But for larger projects or those needing deep expertise, like annotating complex medical scans or legal contracts, outsourcing is usually the smarter, more scalable option. A professional partner gives you immediate access to a trained workforce, proven quality processes, and the ability to scale up or down as needed. This frees up your core team to focus on building great products, not managing a complex data pipeline.
How Is My Data Kept Secure with an External Partner?
Data security is non-negotiable. It should be at the top of your list when you are evaluating any external partner. A reputable data tagging provider will have strict, internationally recognized security protocols and will be completely transparent about them.
Security is not just a feature; it is a fundamental aspect of a professional data services operation. Look for a partner whose entire workflow is built on a foundation of security, from data transfer and storage to access controls and employee training.
A partner you can trust will show their commitment to security in a few key ways:
- Certifications: They should hold certifications like ISO/IEC 27001, the global standard for information security management.
- Regulatory Compliance: They need to follow industry-specific rules like GDPR for personal data or HIPAA for health information.
- Confidentiality Agreements: A solid Non-Disclosure Agreement (NDA) is standard practice to legally protect your data and intellectual property.
- Secure Infrastructure: This means using encrypted data transfers, enforcing strict role-based access, and maintaining secure digital and physical environments.
These measures are there to give you complete peace of mind, ensuring your valuable data is protected every step of the way.
What Is the ROI of Investing in High-Quality Data Tagging?
Investing in high-quality data tagging pays for itself many times over. It might feel like an upfront cost, but quality data is the foundation of any successful AI. Cutting corners here will always cost you more in the long run.
The most obvious return is a more accurate and reliable AI model. This leads directly to better business outcomes, whether that is happier customers from a smarter recommendation engine or more efficient operations from an automated process.
Good data also drastically cuts down the time and money spent debugging and retraining flawed models. Some industry reports show data scientists can spend up to 80% of their time just cleaning and preparing data. By starting with a clean, accurately tagged dataset, you slash that rework, get to market faster, and let your technical teams focus on innovation.
Ultimately, great data tagging is an investment that prevents the huge downstream costs of trying to fix an AI built on a shaky foundation. It ensures your model works as expected and delivers real business value.
Ready to build your AI on a foundation of trust and accuracy? Prudent Partners provides high-quality, secure, and scalable data tagging solutions designed to meet your specific project needs. Connect with our experts today to start with a tailored pilot and see how precision data can accelerate your success.