
Artificial intelligence data annotation is the human-driven process of labeling raw data like images, text, or audio so that machine learning models can understand it. Consider teaching a toddler the concept of a "cat." You do not provide a dictionary definition; you point to a real cat and say the word. This practical labeling is exactly what data annotation does for AI.
Without this critical first step, even the most advanced AI is like a brilliant mind trapped in a dark room, completely unable to process or make sense of the world around it. High-quality, accurately labeled data is the foundational element that transforms a theoretical algorithm into a high-impact business solution.
What Exactly Is AI Data Annotation
At its core, AI data annotation is the process of adding descriptive tags or labels to datasets. This structured information creates the "ground truth" that machine learning algorithms require to learn effectively. For instance, an AI model designed for a self-driving car does not inherently know what a pedestrian looks like. It learns this by analyzing thousands of images where human experts have meticulously drawn boxes around pedestrians and labeled them correctly.
This essential work transforms unstructured data, which computers cannot process on their own, into a structured format that models can use to identify patterns, make predictions, and drive intelligent actions.
The Foundation of Reliable AI
The quality of any AI model is a direct reflection of the quality of its training data. The old saying "garbage in, garbage out" is the absolute rule in machine learning. Inaccurate or inconsistent labels will teach a model the wrong patterns, leading to flawed predictions and unreliable performance in real-world applications. This is why precision and consistency are paramount.
High-quality data annotation ensures models are built on a solid foundation of accurate information. This leads directly to measurable business outcomes:
- Improved Model Accuracy: Well-labeled data helps models make more precise predictions, whether that means identifying manufacturing defects on an assembly line or flagging fraudulent financial transactions with greater certainty.
- Enhanced Reliability: Consistent annotations build trust in AI systems, ensuring they perform dependably when deployed for critical tasks like medical diagnostics or autonomous navigation.
- Faster Development Cycles: Starting with clean, correctly labeled data reduces the need for expensive and time-consuming model retraining, accelerating the path from development to deployment.
Data annotation is not just a technical step; it is the critical translation layer between raw information and machine understanding. Every label, tag, and boundary box provides the contextual clues an algorithm needs to recognize patterns and make intelligent decisions.
Why Human Insight Matters
While some parts of the annotation process can be automated, complex and nuanced tasks still demand human intelligence. An algorithm might struggle to differentiate between a shadow and a pothole on a road, but a human annotator can apply real-world context and judgment to make the correct distinction.
This human-in-the-loop approach is essential for handling ambiguity, nuance, and the edge cases that automated systems almost always miss. It ensures the data reflects the complexity of the real world.
Ultimately, artificial intelligence data annotation is the bridge connecting human knowledge to machine intelligence. By providing clean, accurate, and context-rich labels, we empower AI systems to perceive, understand, and interact with the world in a meaningful way. This careful process, managed by expert teams like those at Prudent Partners, is what turns promising AI concepts into impactful and scalable business solutions.
Exploring Core Data Annotation Techniques

Effective artificial intelligence data annotation requires selecting the right technique for the specific task. This is similar to a sculptor choosing a specific chisel for a particular type of stone; the annotation method must match the dataset and the AI model's objective. A one-size-fits-all approach is inefficient and often leads to poor model performance.
The context and complexity of your data will always dictate the best path forward. Whether you are teaching an AI to identify products on an e-commerce site or to spot anomalies in life-saving medical scans, each goal demands a unique labeling strategy. Making the right choice is the first step toward building a reliable, high-performing AI system.
Image and Video Annotation
Visual data is the lifeblood of countless AI applications, from autonomous vehicles to retail analytics, making image and video annotation some of the most common tasks in the field. These techniques transform raw pixels into structured data that computer vision models can interpret.
Here is a look at the most popular methods:
Bounding Boxes: This is the foundational technique for object detection. Annotators draw simple rectangles around objects of interest, like cars in traffic footage or products on a shelf. It is a straightforward and efficient way to teach a model where objects are located in an image.
Semantic Segmentation: For a much deeper, pixel-level understanding, semantic segmentation classifies every single pixel in an image. In an autonomous driving project, this means the model learns the difference between the road, sidewalks, buildings, and sky, creating a detailed environmental map. In healthcare, it is used to precisely outline tumors in MRI scans for diagnostic support.
Keypoint Annotation (Pose Estimation): This method involves marking specific points of interest on an object, often to understand its shape, posture, or orientation. A practical example is annotating the joints on an athlete's body to help AI models analyze performance or assess ergonomic safety for workers in a factory setting.
Video annotation extends these techniques over time, tracking objects and actions across multiple frames. This adds a crucial temporal element, allowing models to understand movement and behavior, which is essential for applications like activity recognition in security feeds or gesture analysis in interactive systems.
Text and Audio Annotation
AI must understand more than just visual information. Text and audio annotation provide the necessary structure for models to interpret human language and sound, powering everything from sophisticated chatbots to voice-activated assistants.
Named Entity Recognition (NER) is a cornerstone of text annotation. It involves identifying and categorizing key information in text, such as names of people, organizations, locations, or dates. A financial services firm might use NER to automatically extract company names from news articles to track market sentiment and inform investment strategies.
Another key technique is sentiment analysis, which involves labeling text as positive, negative, or neutral. This is incredibly valuable for any business seeking to understand customer feedback from reviews, social media posts, or support tickets. For a deeper dive, you can explore the various types of annotation in our detailed guide.
Audio annotation often begins with transcription (converting speech into text) but can extend to sound event detection, where specific sounds like breaking glass or a siren are tagged within an audio file for security or environmental monitoring applications.
Advanced and Specialized Annotation
As AI ventures into more complex domains, specialized annotation techniques have become non-negotiable. These methods handle data that goes beyond simple images or text, enabling groundbreaking work in fields like autonomous systems, augmented reality, and geospatial intelligence.
LiDAR Point Cloud Annotation: This technique is absolutely critical for autonomous vehicles and robotics. Annotators label 3D point cloud data from LiDAR sensors, identifying pedestrians, other cars, and infrastructure with three-dimensional accuracy. It is what gives these systems the depth perception they need to navigate complex environments safely.
To provide a clearer picture of how these techniques map to real-world problems, here is a quick summary.
Common Data Annotation Techniques and Use Cases
This table breaks down some of the most common annotation methods, the kind of data they're used for, and where you'll see them in action.
| Annotation Technique | Data Type | Primary Use Case Example |
|---|---|---|
| Bounding Boxes | Image/Video | E-commerce product detection on retail websites. |
| Semantic Segmentation | Image/Video | Precisely outlining organs in medical MRI or CT scans. |
| Keypoint Annotation | Image/Video | Tracking human posture for fitness and sports analytics apps. |
| Named Entity Recognition (NER) | Text | Extracting company names and locations from financial reports. |
| Sentiment Analysis | Text | Classifying customer reviews as positive, negative, or neutral. |
| Audio Transcription | Audio | Converting customer service calls into text for analysis. |
| LiDAR Point Cloud Annotation | 3D Sensor Data | Identifying pedestrians and vehicles for self-driving cars. |
From basic boxes to complex 3D clouds, the right technique always depends on the model's end goal and the specific requirements of the application.
Market data tells a similar story about this blend of complexity and technique. While image data is expected to make up 42% of the AI annotation market in 2025, video annotation is the fastest-growing segment. Meanwhile, manual annotation still holds a massive market share of around 41%, because nuanced tasks simply demand human judgment. That said, AI-assisted annotation is expanding rapidly, with forecasts showing it can cut project costs by up to 40% and improve efficiency by 60–70%.
Ultimately, success in artificial intelligence data annotation comes from finding the right balance between human precision and automated speed. Every project is different, and a winning strategy aligns the right techniques with the right tools to achieve accuracy and scalability targets.
The Role of Quality Assurance in Data Annotation
In the world of AI, there is a simple, unavoidable truth: garbage in, garbage out. An artificial intelligence model is only as reliable as the data it was trained on. This makes quality assurance (QA) far more than just a final check; it is the most critical stage in the entire data annotation process.
Without a solid QA framework, even small labeling mistakes can accumulate, creating a domino effect of flawed models, expensive retraining, and AI that cannot be trusted in real-world scenarios. A robust QA strategy is not just about catching errors; it is about building a system that guarantees consistency and accuracy at scale, creating a foundation of trust from day one.
Implementing Multi-Layer Review Systems
So, how do you actually guarantee high-quality data? The most effective approach is a multi-layer review process. Think of it as a series of checks and balances, ensuring no single label is accepted without independent verification. At Prudent Partners, we have perfected a maker-checker-auditor workflow that achieves exactly this.
This system creates a clear chain of accountability and expertise:
- Maker: The first annotator applies labels to the data, strictly following the project guidelines. Their job is to complete the initial annotation correctly.
- Checker: A second, more experienced annotator reviews the maker’s work. They validate every label against the guidelines, correct any mistakes, and provide direct feedback to help the maker improve over time.
- Auditor: A senior quality analyst performs a final spot-check on the corrected data. The auditor is the last line of defense, confirming the labels meet the highest standards and ensuring consistency across the entire dataset.
This structured workflow is designed to systematically filter out inaccuracies, ensuring the final dataset is clean, reliable, and ready for model training.
Demystifying Key Quality Metrics
To maintain objectivity, data science teams rely on specific, quantifiable metrics. These scores remove the guesswork from quality control and provide everyone with a clear benchmark for success. In computer vision, two of the most important metrics are Intersection over Union (IoU) and consensus scores.
IoU is a core metric for object detection. It measures how much a predicted bounding box (from the model) overlaps with the ground-truth bounding box (from the human annotator). A higher IoU score signifies a more precise and accurate label.
Consensus scores, on the other hand, are used when multiple annotators label the same piece of data. The score measures the degree of agreement among them. A high consensus score is a positive indicator that your annotation guidelines are clear and being interpreted consistently. If the scores are low, it is a red flag that your guidelines may be ambiguous and require refinement. A formal data annotation assessment can help you identify these gaps early in the process.
The Measurable Impact of Rigorous QA
When you invest in a comprehensive QA process from the start, the returns are significant. It directly prevents the need for costly model retraining, a common problem that can easily derail project timelines and inflate budgets.
Even more importantly, it builds deep confidence in your AI’s outputs. This ensures the final application is dependable enough for critical business operations. Ultimately, QA is not just about fixing mistakes. It is about building a scalable process that produces consistently high-quality data, allowing your AI models to learn correctly, perform accurately, and deliver real, tangible value. This commitment is what separates a proof-of-concept from a successful, production-ready AI solution.
How to Build an Efficient Data Annotation Workflow
A successful artificial intelligence data annotation project is never an accident. It is the direct result of a structured, repeatable, and scalable workflow. For any data science leader, designing this process is just as important as building the model itself. A well-defined workflow serves as your roadmap, ensuring every step from data ingestion to final delivery is handled with precision.
This structured approach helps to avoid common pitfalls like inconsistent labeling, missed deadlines, and escalating costs. It creates a system that can scale smoothly from a few thousand data points to millions without ever sacrificing the quality your AI models depend on. The key is to establish clear steps, assign responsibilities, and build in feedback channels right from the start.
Defining Project Scope and Guidelines
First, you must define the project’s scope with absolute clarity. This means documenting exactly what needs to be labeled, the specific attributes for each label, and most importantly, how to handle ambiguous or edge-case scenarios. Vague instructions are the leading cause of inconsistent annotations and wasted effort.
To prevent this, teams must create comprehensive and unambiguous annotation guidelines. Think of these guidelines as the project's constitution, the single source of truth that every annotator must follow. These documents should be filled with visual examples of correct and incorrect labels, detailed definitions, and clear decision trees for challenging situations. You can learn more about crafting these critical documents in our dedicated resource on effective annotation guidelines.
Selecting the Right Tools and Running a Pilot
With clear guidelines in hand, the next step is to select the right annotation platform. The market for these tools is expanding rapidly, a clear sign of their importance in modern AI operations. In fact, the data annotation tools market, valued at over USD 6.98 billion in 2025, is expected to soar to nearly USD 44.68 billion by 2035. This growth highlights the demand for robust platforms that can track productivity, quality, and timelines, especially with distributed teams.
Before committing to a full-scale project, it is essential to run a pilot. A pilot project, using a small but representative sample of your dataset, is the best way to pressure-test your entire workflow. It allows you to:
- Validate Your Guidelines: Observe how annotators interpret your instructions in practice and identify any areas of confusion.
- Assess Tool Performance: Ensure the chosen platform is efficient and well-suited for your specific annotation task.
- Establish Baselines: Measure initial accuracy rates and annotation speed to set realistic expectations for the main project.
This pilot phase delivers invaluable insights, allowing you to fine-tune your guidelines and processes before scaling up. It is a small initial investment that saves significant time and resources down the road.
Establishing Feedback Loops and Quality Control
An effective workflow is not static; it improves over time. Continuous improvement is driven by tight feedback loops between your annotators and quality assurance (QA) teams. When a QA checker identifies an error, that feedback must be communicated back to the original annotator quickly. This helps them learn and avoid repeating the same mistake, which drives up overall quality.
This diagram illustrates a standard multi-layer QA process, moving from the initial labeling (Maker) to verification (Checker) and a final validation step (Auditor).
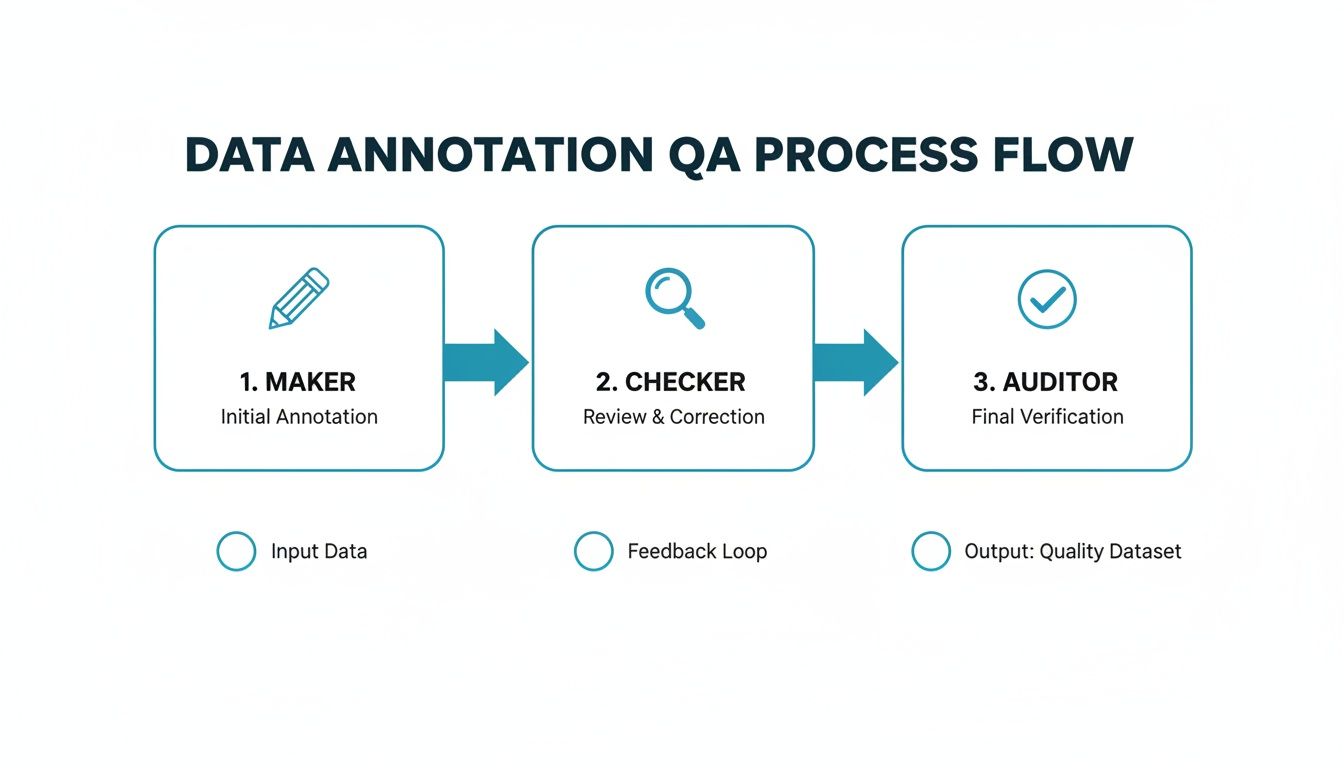
The maker-checker-auditor model creates a system of checks and balances, ensuring errors are caught and corrected at multiple stages. This structured review is fundamental to delivering datasets that meet the 99%+ accuracy targets required for building truly reliable AI systems.
By carefully planning each stage from scope definition to final QA, you can build a resilient and efficient artificial intelligence data annotation workflow that delivers high-quality training data, consistently and at scale.
Choosing the Right Data Annotation Partner
Selecting an artificial intelligence data annotation partner is a significant decision, extending far beyond a simple price comparison. The right vendor becomes an extension of your team, delivering the high-quality data your model needs to succeed while ensuring your intellectual property remains secure. The wrong partner can lead to poor data quality, missed deadlines, and costly rework.
Making the right choice requires a structured evaluation. You are looking for a true partner, not just a label provider. They need to understand your objectives, adapt to challenges, and possess the operational capacity to scale with your needs.
Evaluating Potential Partners on Core Competencies
When vetting vendors, focus on three key areas: their domain expertise, their quality assurance processes, and their security infrastructure. Each of these pillars supports the success and safety of your project.
First, look for proven domain expertise. You would not ask a general practitioner to perform brain surgery, and the same principle applies here. A partner annotating medical images must understand clinical details. A team labeling LiDAR data for autonomous cars needs deep experience with 3D point clouds. Ask for case studies that are directly relevant to your industry. A vendor who already speaks your language will onboard faster, produce higher-quality labels, and require less supervision.
Next, you must demand transparent quality assurance processes. Any potential partner should be able to walk you through their QA workflow without hesitation. Do they use a multi-layer review system, such as a maker-checker-auditor model? What specific metrics do they use to measure accuracy, like Intersection over Union (IoU) or consensus scores? If they are hesitant to share these details, it is a major red flag.
The Importance of Security and Confidentiality
Security is not just a feature; it is the foundation of a trusted partnership, especially when dealing with proprietary or sensitive data. A reputable partner must have verifiable security certifications that prove their commitment to protecting your information.
Here is what to look for:
- ISO/IEC 27001: This is the global gold standard for information security management. It confirms the provider has a formal system for managing and reducing risks to your data.
- Comprehensive NDAs: Ensure their non-disclosure agreements are ironclad and legally binding, protecting your intellectual property from the very first conversation.
- Secure Infrastructure: Ask how they handle your data. What are their transfer protocols? Are their work environments access-controlled?
A partner’s security posture is a direct reflection of their professionalism. Certifications like ISO 27001 are not just for show; they are proof of a systematic commitment to protecting the data that gives your business its competitive edge.
Why a Pilot Project is Non-Negotiable
You can read all the brochures and sit through countless sales pitches, but nothing beats seeing a team in action. Before you consider signing a long-term contract, you must insist on a pilot project. This trial run, using a small but representative sample of your data, is the single best way to evaluate a partner's true capabilities.
A pilot project reveals things a proposal never can:
- Communication and Responsiveness: How quickly do they respond? Is their feedback helpful and clear?
- Workflow Efficiency: Do they adhere to the plan and timeline? How smoothly do they collaborate with your team?
- Quality of Deliverables: When the annotated data is returned, does it meet your accuracy standards?
This initial test provides concrete proof of their capabilities. It allows you to move forward with a partner like Prudent Partners, confident that they can deliver the quality and reliability your AI initiatives demand. For more insights on security, the Cloud Security Alliance (CSA) is an excellent resource for any organization handling sensitive data.
The Future of AI Data Annotation
The work of AI data annotation is no longer a behind-the-scenes task. It has evolved from a simple operational step to a central driver of innovation for any business serious about building reliable AI systems.
The future is not just about labeling more data faster. It is about handling increasingly complex data with surgical precision, ironclad security, and real strategic insight. As AI models become embedded in critical business functions, the demand for expert annotation is exploding, creating a market that is growing at a breakneck pace. Preparing for the AI of tomorrow means implementing a forward-looking data strategy today.
Explosive Market Growth and Strategic Impact
The data annotation market’s remarkable expansion reflects its growing importance. The global market is estimated to reach approximately USD 2.3–2.4 billion in 2025, with projections soaring past USD 12 billion by 2032.
That implies a compound annual growth rate somewhere between 26% and 33%. With global data volume expected to reach 175 zettabytes by 2025, the slice of AI budgets dedicated to high-accuracy labeling has become one of the fastest-growing components of the entire AI stack. For data science leaders, this means annotation capacity and quality are no longer just operational concerns; they are essential for maintaining a competitive edge. Discover more insights about the data annotation market in Vietnam and its global impact.
Data annotation is no longer just about creating training datasets. It is a continuous cycle of data curation and quality management that directly shapes an AI model's real-world performance, reliability, and trustworthiness.
Emerging Frontiers in Annotation
The future of annotation is being shaped by the needs of next-generation AI. One of the most significant trends is the rise of Reinforcement Learning from Human Feedback (RLHF). This is the critical technique used to train and fine-tune large language models and other generative AI systems.
In RLHF, human annotators rank, score, and rewrite model outputs to align them with desired behaviors, tones, and factual accuracy. It is a sophisticated process that demands deep contextual understanding, not just simple labeling.
At the same time, the demand for highly specialized annotation is growing in complex fields:
- Medical AI: Annotating medical images like MRIs or pathology slides requires certified domain experts who can identify subtle diagnostic markers with clinical precision.
- Autonomous Systems: Labeling 3D LiDAR point clouds and sensor fusion data for self-driving cars demands meticulous accuracy where public safety is paramount.
As these advanced applications become mainstream, the need for partners who can deliver secure, scalable, and specialized annotation services will only grow. Building a robust data strategy with a trusted partner like Prudent Partners ensures your AI initiatives are built on a foundation of quality, ready to meet the challenges of tomorrow.
Frequently Asked Questions About Data Annotation
Diving into artificial intelligence data annotation always brings up a few practical questions, especially for those planning their first major AI project. Let's address some of the most common ones to provide clarity and help you build a smarter data strategy.
How Much Does Data Annotation Typically Cost?
There is no single price tag for data annotation, as the cost depends heavily on project requirements. The most significant factor is task complexity. Drawing simple bounding boxes around cars is fundamentally different from performing pixel-perfect semantic segmentation on a high-resolution medical scan.
Other key cost drivers include the required accuracy level, the total volume of data to be labeled, and whether your project demands specialized domain knowledge. Pricing models also vary; you might see rates calculated per hour, per task, or as part of a managed service package. The most effective way to determine the cost for your specific needs is to run a small pilot project. A good partner will always provide a customized quote tailored to your budget and quality targets.
What Is the Difference Between In-House and Outsourced Annotation?
This is a classic "build versus buy" decision. Building an in-house team gives you complete control, but it represents a major investment. You will need to recruit and train specialized staff, license the appropriate software, and manage the entire operational workflow.
On the other hand, outsourcing to a dedicated provider like Prudent Partners provides immediate access to a trained workforce, battle-tested QA processes, and an infrastructure built to scale. This approach frees up your core team to focus on their primary strength, which is building models, rather than getting bogged down in annotation logistics. A popular and effective hybrid model involves using an external team managed by an in-house project lead who provides oversight and ensures alignment with business goals.
How Do You Ensure Data Security When Outsourcing?
Data security should be a top priority when working with an external partner. Any reputable annotation vendor will have a multi-layered security strategy to protect your sensitive information.
The bedrock of a secure partnership rests on internationally recognized certifications like ISO/IEC 27001 for information security, ironclad Non-Disclosure Agreements (NDAs), and secure data transfer protocols.
Beyond these fundamentals, top-tier providers operate from access-controlled facilities to eliminate any risk of a data leak. Always thoroughly investigate a potential partner's security credentials and data handling policies before signing any agreements. It is the only way to ensure your intellectual property is protected at every stage of the process.
Ready to build your AI on a foundation of quality and trust? Prudent Partners delivers high-accuracy data annotation with the security and scalability your projects demand. Contact us today to discuss your needs and start a pilot project.