
Data for training is the curated curriculum an AI model uses to learn how to think, predict, and act. It is a collection of high-quality, labeled examples like images, text, or sounds that give the machine the context it needs to recognize patterns and make smart decisions. The success of any AI model hinges directly on the quality and relevance of this data.
Understanding the Foundation of AI Success
Think of building a powerful AI model like training a brilliant apprentice. This apprentice does not learn from abstract theories; they learn from hands-on, high-quality examples. That is exactly what data for training is: a carefully organized library of information, contextualized by human experts. Without this foundational knowledge, an AI model is just an empty algorithm, unable to produce anything meaningful.
The process is far more strategic than just dumping raw information into a folder. It is about ensuring every single piece of data contributes to the model's education. For instance, an AI designed to spot manufacturing defects needs thousands of images where experts have meticulously outlined every scratch, dent, and flaw. Those labels are the "answer key" that teaches the model the difference between a perfect product and a faulty one.
Why Quality Trumps Quantity
In the world of AI, more is not always better. A smaller, perfectly labeled dataset will almost always build a more reliable model than a massive, messy, or poorly annotated one. Why? Because inconsistent or wrong labels confuse the AI, teaching it the wrong patterns and leading to expensive mistakes down the line. A data-first strategy puts accuracy and relevance at the forefront from day one.
This commitment to quality pays off in several key ways:
- Higher Model Accuracy: Clean, consistent data leads directly to more precise predictions and fewer errors.
- Faster Development Cycles: High-quality data cuts down the time spent debugging and retraining models that are not performing.
- Increased Reliability and Trust: A well-trained model behaves predictably, building confidence among users and stakeholders.
- Measurable Business Impact: Reliable AI drives real-world results, from better operational efficiency to improved customer experiences.
A model trained on a million low-quality examples will almost always underperform one trained on ten thousand high-fidelity, expert-annotated examples. The initial investment in quality data pays dividends by preventing the 'garbage in, garbage out' trap.
At the end of the day, the performance of any AI system is a direct reflection of the data for training it was built on. A strategic approach to data is not just a good idea, it is non-negotiable for any organization serious about building AI that actually works. To dig deeper into this first critical stage, you can explore our detailed guide on the meaning of data curation and its role in building a solid foundation. This is the step that separates unreliable AI projects from those that achieve real, scalable success.
The Core Types of AI Training Data
Think of an AI model like a specialized apprentice. Just as a chef needs to learn from different ingredients to create different dishes, an AI needs the right kind of data for training to master a specific skill. You would not teach a sommelier by having them read spreadsheets, and you would not train a fraud detection algorithm on photos of cats.
The data you choose is the model's only connection to the real world. It is how it learns to "see," "hear," or "read." An autonomous vehicle needs to see the road, so it learns from visual data. A chatbot needs to understand conversations, so it learns from text. Getting this first step right is everything.
This simple flow shows how everything in AI starts with good data. Quality inputs lead to a well-trained model, which is the only way to achieve a real business impact.
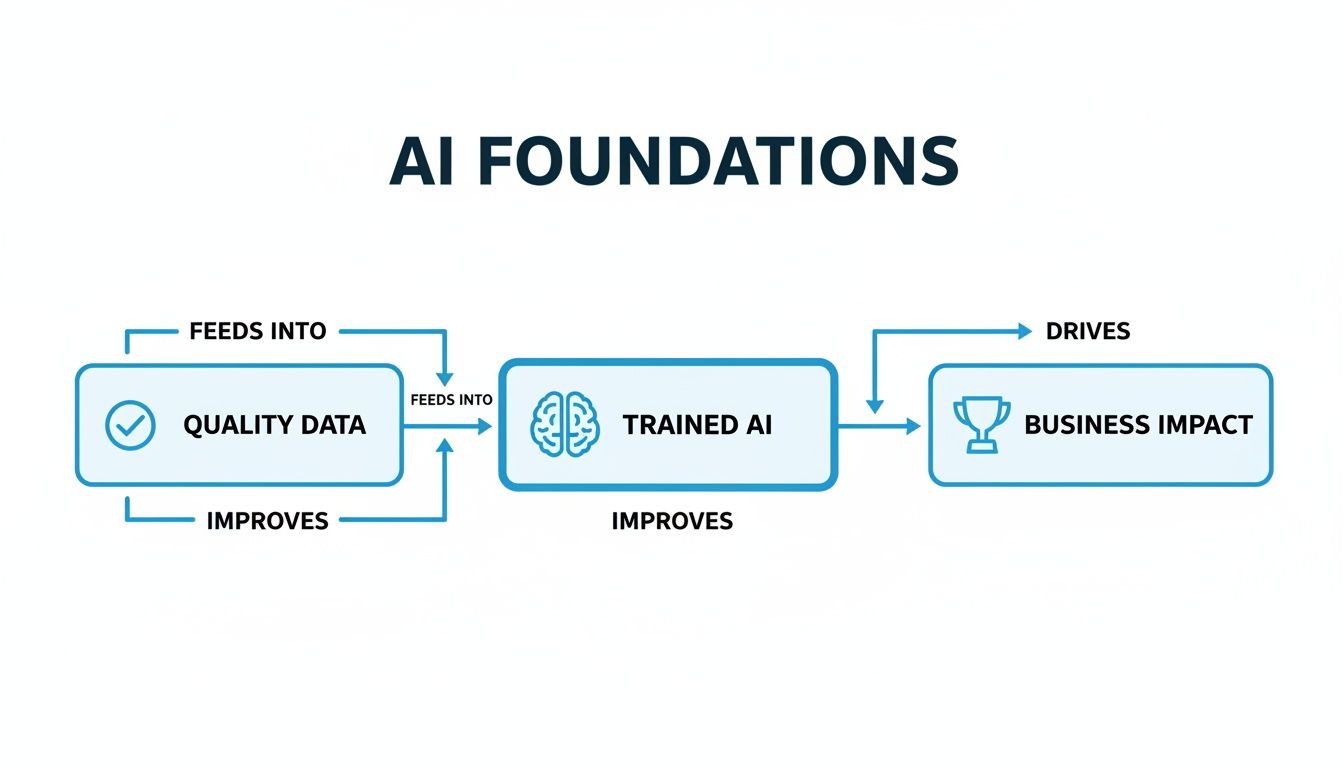
Without a solid foundation of high-quality, relevant data, the entire AI initiative is built on shaky ground. Let's break down the most common types of data used to train today's models.
Image and Video Data
For any AI that needs to understand the visual world, image and video data are the essential ingredients. This is the domain of computer vision, where models learn to recognize objects, people, and activities with stunning accuracy.
- Image Data: These are the still photographs and individual frames that teach models to perform tasks like object detection, classification, and segmentation. A healthcare AI, for example, might be trained on thousands of labeled medical scans to spot anomalies a human eye might miss. An e-commerce site could use annotated product photos to let shoppers search with a picture instead of words.
- Video Data: As a sequence of images, video adds the critical dimension of time and motion. It is indispensable for training models to understand actions and behaviors, like an AI monitoring a factory floor for safety violations or another analyzing traffic flows for a smart city project.
Annotating this data can mean drawing simple bounding boxes around objects, tracing their exact outlines with polygons (semantic segmentation), or classifying an entire scene. The more detailed the annotation, the smarter the model.
Text and Audio Data
Language and sound are how humans communicate, so it is no surprise that text and audio data are vital for building models that can interact with us. These datasets are the foundation of Natural Language Processing (NLP), conversational AI, and voice recognition systems.
Text data is the lifeblood of any model that needs to understand or generate human language. We are talking about everything from customer reviews and social media posts to legal contracts and support tickets. A bank might train a model on labeled emails to spot the subtle language of a phishing attempt, while a customer service bot learns to detect frustration in chat logs to escalate an issue to a human agent.
Likewise, audio data gives machines the ability to interpret spoken words and other sounds. An AI assistant like Alexa or Siri is trained on enormous datasets of spoken phrases to learn the difference between a command and background noise. In an industrial setting, an AI might listen to the hum of a machine to predict a potential failure before it happens.
Specialized Sensor Data Like LiDAR
AI can also perceive the world in ways humans cannot, thanks to specialized sensors. LiDAR (Light Detection and Ranging) is a perfect example. It uses laser pulses to build incredibly detailed 3D maps of an environment, providing a level of depth and precision that a standard camera simply cannot capture.
LiDAR data provides a level of spatial precision that standard cameras cannot match. For an autonomous vehicle or a warehouse robot, this data is not just helpful; it is essential for safe and accurate navigation in complex, dynamic spaces.
This type of data is critical wherever a deep understanding of physical space is non-negotiable. In robotics, LiDAR helps automated systems map their surroundings to avoid obstacles. In the geospatial industry, it is used to create hyper-accurate topographical maps for urban planners. Every single point in a LiDAR scan represents a precise location in 3D space, providing rich, structured data for training the most sophisticated perception models.
To bring it all together, here is a quick summary of the common data types and where you will see them in action.
Common Training Data Types and Their AI Applications
| Data Type | Annotation Method Examples | Common Use Case |
|---|---|---|
| Image | Bounding Boxes, Polygons, Keypoints, Segmentation | Object detection in retail, medical image analysis, facial recognition |
| Video | Object Tracking, Activity Recognition, Temporal Annotation | Autonomous driving, public safety monitoring, sports analytics |
| Text | Named Entity Recognition (NER), Sentiment Analysis, Text Classification | Chatbots, spam filtering, financial fraud detection, legal document review |
| Audio | Transcription, Speaker Diarization, Sound Event Detection | Voice assistants (Siri, Alexa), call center analytics, predictive maintenance |
| LiDAR | 3D Cuboids, Point Cloud Segmentation | Autonomous vehicles, robotics, augmented reality (AR), urban planning |
Understanding these fundamental data types is the first step, but it is just the beginning. The real challenge, and where the value is created, lies in how you source, label, and manage this data to build a truly effective AI system.
How to Source and Prepare Your Data Pipeline
Getting the right data for training is the first, and arguably most important, hurdle in any AI project. Before a single image can be labeled or a single line of text fed to a model, you need a solid, reliable data pipeline. That whole process starts with sourcing: figuring out where to get the raw material your model will learn from.
The path you take here will directly shape your project's budget, timeline, and the ultimate quality of your AI. Each sourcing strategy has its own trade-offs, so it is critical to pick the one that actually matches your goals.
Exploring Your Data Sourcing Options
There are really three main ways to get the raw data you need to fuel your AI. The best choice comes down to things like how specific your data needs to be, what resources you have on hand, and how much control you want over the final dataset.
- Public Datasets: Open-source hubs like Kaggle or Google Dataset Search are packed with free data. This is a great starting point for general-purpose models or early-stage research, but these datasets rarely have the niche specificity needed to solve unique business problems.
- Proprietary Data Generation: Creating your own data from scratch gives you total control over its content and quality. This is the go-to option for projects that need highly specialized or confidential information, like training a model on your company’s internal customer service chats or unique manufacturing sensor readings. Just be warned: this route can be slow and very expensive.
- Partnering with a Data Provider: Specialized data service providers can find or create custom datasets built to your exact specs. This approach often strikes the best balance between speed, quality, and cost, giving you access to high-quality, relevant data without the headache of generating it all yourself.
Choosing the right sourcing strategy is a critical first step. For many businesses, a hybrid approach works best, supplementing proprietary data with targeted datasets acquired from a specialized partner to fill specific gaps.
Once you have your raw data, the job is far from done. The next step, data preparation, is where the real foundation is laid for everything that follows. If you want to go deeper, our guide on what is data sourcing breaks down these strategies in much more detail.
The Importance of Data Preparation
Think of raw data like uncut stone. It is full of potential, but it needs to be cleaned, shaped, and polished before you can build anything valuable with it. That is what data preparation does. It turns messy, inconsistent information into a clean, standardized foundation that is ready for annotation.
Skip this step, and even the world’s best annotators will struggle to produce high-quality labels. The whole process involves a few key actions that prevent problems down the line and make sure your model learns from the right information.
Key Data Preparation Steps
- Data Cleaning: This is all about finding and fixing errors, inconsistencies, or inaccuracies. For example, a dataset of customer addresses might be full of typos, missing zip codes, or different formatting that all needs to be corrected.
- Removing Duplicates: Identical or nearly identical data points can throw off a model’s training, causing it to give too much weight to certain examples. Deduplication ensures that every piece of data adds unique value.
- Normalization and Standardization: This step makes sure all your data follows a consistent format. For instance, you might resize all images to a standard resolution or convert all date entries to a single format (like YYYY-MM-DD).
Ignoring data preparation is one of the most common ways AI projects fail. It leads to a classic "garbage in, garbage out" situation, where errors in the raw data create a confused model and unreliable results. By investing time upfront to build a clean, consistent dataset, you set the entire project up for success.
The Critical Role of Data Annotation
If raw data is the crude oil of AI, then data annotation is the refining process that turns it into high-octane fuel. This is the hands-on, human-driven stage where raw information becomes intelligent data for training. It is all about adding labels, tags, and context to your data, which is how you teach a model what to look for and how to make sense of the world. Far from simple tagging, this is the art of embedding deep domain knowledge directly into your dataset.
This is the process that allows a machine learning model to start making connections. For an algorithm to learn how to spot cybersecurity threats, a human expert first has to label examples of malicious code, suspicious network activity, and phishing emails. Without those labels, the raw data is just noise. High-quality annotation provides the ground truth, the "answer key" from which the model learns to generalize and make predictions on new data it has never seen before.

From Simple Tags to Complex Insights
The complexity of the annotation has to match the complexity of the AI task. Some projects might just need basic classification, but others demand a level of expert interpretation that directly shapes what the final model can do.
Think about the difference between these two scenarios:
- E-commerce Product Tagging: An annotator applies a simple label like "red shoes" to a product image. This is a straightforward classification task.
- Medical Imaging Analysis: A radiologist annotates a prenatal ultrasound, not just identifying an organ but meticulously outlining a potential anomaly’s precise shape, size, and texture. This granular detail, known as semantic segmentation, requires years of medical expertise.
In that second example, the annotator is not just labeling; they are translating their medical training into a format the AI can understand. The quality of their work is what determines whether the AI tool can one day help clinicians make critical diagnoses.
Best Practices for High-Accuracy Annotation
Achieving precision and consistency in data annotation does not happen by accident. It requires a structured approach built on proven best practices. Any flaws introduced here are notoriously difficult to fix later on and can tank a model's performance, leading to a lot of wasted time and money.
To make sure your annotation process is both solid and scalable, focus on these core pillars:
- Develop Crystal Clear Guidelines: Create a detailed instruction document that includes visual examples of both correct and incorrect labels. This "rulebook" is your single most important tool for cutting down on ambiguity and ensuring every annotator works from the same playbook.
- Invest in Annotator Training: Even domain experts need to be trained on the specific project guidelines and tools. A dedicated onboarding process gets everyone aligned before a single piece of data is labeled.
- Select the Right Annotation Tools: The software you use should be a good match for your data type and the complexity of the annotation. A tool built for drawing bounding boxes on images will not work well for transcribing audio or labeling 3D LiDAR point clouds.
- Implement Quality Assurance Cycles: No annotation process is perfect on the first try. A multi-layered review, where senior annotators or QA specialists check a sample of the work, is essential for catching errors and providing feedback.
The ultimate goal of a data annotation workflow is to achieve high Inter-Annotator Agreement (IAA). This metric measures the level of consistency among multiple annotators, giving you a quantitative way to assess how clear your guidelines are and how reliable your labels are.
The Measurable Impact of Expert Annotation
The precision you invest in during annotation pays off in measurable business outcomes. In one project focused on identifying unsafe ad content, researchers found that models trained on a small set of high-fidelity, expert-labeled data performed significantly better. In fact, models trained on fewer than 500 expert-annotated examples outperformed models that were trained on 100,000 crowdsourced labels.
This proves a critical principle: a smaller, expertly curated dataset is often far more powerful than a massive, noisy one. High-quality annotation reduces the amount of data you need, shortens training times, and produces a more accurate and reliable AI model. To get a more complete picture of this foundational process, you can learn more about what data labeling entails in our detailed guide.
Ultimately, expert-led annotation is the bridge that connects raw data to a high-performing AI system you can actually trust to deliver results.
Validating Data with a Rigorous QA Process
Great AI is not just built on clever algorithms, it is built on trust. And that trust starts with a rock-solid quality assurance (QA) process for your data. After your data is annotated, it needs to be validated. Think of this as the final inspection on an assembly line, ensuring every piece of data for training is accurate, consistent, and ready to create a reliable model.
Without this step, you are walking straight into the classic "garbage in, garbage out" trap. Inconsistent or flat-out wrong labels will teach your model all the wrong lessons, leading to unpredictable, flawed results. A multi-layered QA process is your best defense, systematically catching errors and refining your dataset until it is truly world-class.

Key Metrics for Measuring Data Quality
Effective QA moves beyond gut feelings and relies on hard numbers. These metrics give you a clear, objective picture of your data’s integrity and help you zero in on what needs fixing. If you are managing an annotation project, these are the numbers you need to know.
Here are the core metrics every AI team should live by:
- Accuracy: This one is as straightforward as it gets. It is simply the percentage of labels that are correct. If 990 out of 1,000 images are labeled right, your accuracy is 99%.
- Precision and Recall: These give you a much deeper insight, especially when dealing with imbalanced datasets. Precision tells you how many of your positive predictions were actually correct. Recall tells you how many of the actual positives you managed to find. For a medical AI trying to spot a rare disease, high recall is everything, you cannot afford to miss a case.
- Inter-Annotator Agreement (IAA): This is a powerful one. IAA measures how consistently multiple human annotators label the exact same data. A high IAA score is a great sign that your instructions are crystal clear and everyone understands the task.
Inter-Annotator Agreement is not just a quality score; it is a direct measure of how consistently your human experts interpret complex information. A low IAA is often the first sign that annotation guidelines are ambiguous, leading to subjective and unreliable labels.
The Power of Inter-Annotator Agreement
Of all the metrics, IAA might be the most insightful. It is like an early warning system for your entire data pipeline. When you see a low IAA score, it does not just mean your annotators are making random mistakes, it often points to a fundamental problem with how the task is defined.
Imagine two expert radiologists disagreeing on the precise boundary of a tumor in an MRI scan. The issue might not be their skill, but the ambiguity in the image itself. The goal is to get everyone on the same page. To achieve a high IAA, often measured with statistics like Cohen's Kappa, you have to refine your instructions until every annotator shares a single, unified understanding. In specialized fields, a Cohen’s Kappa score above .80 is considered the gold standard, showing near-perfect alignment between experts.
Implementing a Multi-Layered Review Cycle
A single pass of annotation is almost never enough to guarantee quality. The best QA processes use a multi-layered review cycle where annotations are checked, corrected, and refined over and over again. This creates a powerful feedback loop that improves both the dataset and the skills of your annotation team.
A typical workflow looks something like this:
- Initial Annotation: The first team of annotators gets to work, applying labels based on the project guidelines.
- Peer Review: A sample of the annotated data is passed to another annotator for a second look. This is great for catching obvious errors and inconsistencies right away.
- Expert or Consensus Review: For the really tricky stuff, a senior annotator or a domain expert steps in. On high-stakes projects, you might even use a consensus approach where several experts must agree on the final label before it is approved.
- Feedback and Retraining: All the insights from the review process are fed back into the system. Guidelines are updated, and annotators get additional training, creating a cycle of continuous improvement.
This structured, iterative process is the only way to ensure your final dataset is clean, consistent, and ready to build an AI model you can actually depend on. It transforms QA from a simple box-ticking exercise into a strategic system for building trust into every single piece of your data for training.
Why a Strategic Data Partner Is Your Competitive Advantage
Let’s be honest: building a world-class data pipeline is a full-time job. Your data science team is brilliant at creating models, but the grueling work of sourcing, preparing, and annotating high-quality data for training can pull them away from their core mission and grind your AI roadmap to a halt. This is where bringing in a specialized data services provider becomes one of the smartest moves you can make.
It is not just about saving money on operations, either. A true partnership gives you a massive competitive edge by instantly providing resources that would otherwise take years and a small fortune to build yourself.
Get Immediate Access to Domain Experts
A great data partner brings a team of trained, vetted domain experts to your project from day one. Need radiologists to annotate complex medical scans? Or cybersecurity analysts to pinpoint network threats? You can tap into a specialized workforce immediately, skipping the long and expensive headache of recruiting and training.
This kind of instant expertise is a game-changer for projects where nuance and context are everything. It guarantees your data is not just labeled, it is intelligently annotated with the precision needed to build a model that actually performs in the real world.
Scale to Millions Without Sacrificing Quality
One of the toughest hurdles in AI development is scaling your data operations without quality falling off a cliff. As your data needs explode from thousands to millions of examples, keeping things consistent and accurate gets exponentially harder. A dedicated partner is built for exactly this challenge.
With established workflows, multi-layered QA processes, and hundreds of trained analysts, a partner can churn through huge volumes of data while hitting accuracy targets of 99% or higher. This lets your team think bigger and move faster, knowing the data foundation beneath them is rock-solid.
Partnering with a data specialist de-risks your AI initiatives. It turns the unpredictable, time-sucking task of data preparation into a predictable, managed service. This frees up your best people to focus on what they do best: innovation and deployment.
Lock Down Compliance and Security
Handling sensitive data is a serious responsibility. A certified data partner gives you the confidence that your information is protected by international standards, right out of the box.
For example, an ISO 27001 certification is not just a piece of paper; it proves a systematic, battle-tested approach to managing information security risks. By working with a certified provider, you inherit a secure infrastructure and proven protocols, ensuring your sensitive data for training is handled with the highest level of care.
How to Evaluate a Potential Data Partner
Choosing the right partner is everything. You need a provider who has been there, done that, and is completely transparent about how they work.
Use this checklist to cut through the noise:
- Proven Track Record: Can they show you case studies or examples in your specific industry?
- Transparent Processes: Do they have a clear explanation for their QA methodology and how they measure accuracy? No black boxes.
- Security Certifications: Do they hold key certifications like ISO 27001 to protect your data? This is non-negotiable for sensitive information.
- Scalable Workforce: Can they handle your projected data volume without breaking a sweat or compromising on quality?
- Commitment to Accuracy: Do they have clear metrics and a system for delivering high-fidelity labels, every single time?
Ultimately, a strategic partnership gets you to market faster. It lets the experts handle the data pipeline so your team can focus on building the models that drive real business value.
Frequently Asked Questions
When you are building an AI model, a lot of questions pop up around training data. It is a foundational piece of the puzzle, so it is natural to want to get it right. Here are some straightforward answers to the questions we hear most often.
How Much Training Data Do I Actually Need?
There is no simple, one-size-fits-all answer here. The amount of data for training you need is tied directly to how complex your project is. For a simple model, say, one that just has to tell the difference between a "cat" and a "dog," a few thousand labeled images might do the trick.
But if you are building something more sophisticated, like an AI for medical diagnostics that needs to spot tiny anomalies in MRI scans, you could be looking at tens of thousands of images, each one meticulously annotated by a medical expert. The best approach? Do not pull a huge number out of thin air. Start with a smaller, focused pilot dataset, see how your model performs, and scale up from there based on real-world results.
Data Augmentation Versus Sourcing More Data
This is a common fork in the road. Data augmentation is a clever trick where you artificially grow your dataset by creating slightly modified versions of the data you already have, think rotating an image or changing the pitch of an audio clip. It is a great, cost-effective way to make your model a bit more robust.
But here is the catch: augmentation cannot teach your model anything truly new. Sourcing more data means getting fresh, unique examples from the real world. If your self-driving car has only been trained on daytime footage, no amount of image tweaking will prepare it for driving at night. For that, you have to go out and collect actual nighttime data. Augmentation is a helpful tool, but it is no substitute for filling genuine gaps in your dataset.
How Do You Ensure Data Privacy and Security?
When you are dealing with sensitive information, security is not just a feature; it is a requirement. Protecting data during the annotation process comes down to a mix of strict protocols, secure infrastructure, and official certifications that prove you are doing it right. For example, an ISO 27001 certification is not just a badge, it shows a company has a systematic, audited process for managing information security risks.
At Prudent Partners, every project is handled under strict NDAs, and all work is done in secure, access-controlled facilities. We know that your proprietary or sensitive data for training is your competitive edge, and we treat it with the confidentiality it deserves. It is all about building a foundation of trust so you can focus on innovation.
Ready to build your AI on a foundation of trust and precision? Prudent Partners provides high-accuracy data services with the security, scalability, and expertise you need to succeed. Connect with our experts today for a customized solution.