
At its core, to annotate a text means to add explanatory notes, labels, or metadata to raw text. This process transforms unstructured language into a structured, machine-readable format that artificial intelligence can understand. For businesses, this is the foundational step in unlocking actionable insights from vast amounts of text data, from customer feedback to internal documents.
From Highlighting Books to Training AI
The simple act of marking up a document is a familiar concept. Whether underlining important sentences in a contract or jotting notes in the margins of a novel, you were performing a basic form of text annotation. The goal was personal comprehension, to make the text more useful for you.
When it comes to Artificial Intelligence, the principle remains, but the scale and purpose are vastly different. Answering "what does it mean to annotate a text" in an AI context means systematically labeling language to teach a machine. Instead of highlighting for one person’s understanding, you are creating a definitive "ground truth" for an algorithm to learn from, enabling measurable improvements in business processes.
Bridging Human and Machine Understanding
This process is the crucial first step in nearly every Natural Language Processing (NLP) initiative. Human language is packed with nuance, context, and ambiguity that computers cannot grasp on their own. Annotation bridges this gap by providing clear, consistent labels that translate complex language into structured data.
For example, a machine learning model doesn’t intuitively know that "Apple" can be a fruit or a tech company. Through annotation, human experts tag each instance of the word with the correct label (e.g., Fruit or Organization), teaching the model to recognize the difference based on its surrounding context. As you can see in this sample annotation of an article, the process requires precision and clear guidelines to be effective and deliver scalable results.
This structured data becomes the training material for AI systems, enabling them to perform sophisticated tasks like:
- Powering intelligent chatbots that understand user requests with high accuracy.
- Analyzing customer feedback to quantify sentiment and identify trends.
- Extracting critical information from thousands of documents automatically, reducing manual effort.
How AI Annotation Differs From Personal Notes
We have all highlighted a textbook or scribbled notes in the margins of a report. That is annotation in its most familiar form. But when we discuss annotating text for artificial intelligence, we are talking about a far more rigorous and objective discipline.
Personal note-taking is for you alone. It is subjective, informal, and designed to help you remember or question something. No one else needs to understand your unique system of highlights and cryptic notes.
Annotating for an AI model is the exact opposite. The goal is to create an objective, perfectly consistent dataset that an algorithm can learn from. This is not about personal interpretation; it is about building a reliable "ground truth" a definitive source of facts the machine can trust. Every label must be precise, unambiguous, and applied the same way across thousands or even millions of examples to ensure data quality and model performance.
Purpose, Process, and Precision
The core difference boils down to intent and impact. Your personal notes are for your own recall. AI annotations are for training a scalable algorithm that can drive business outcomes.
This distinction forces a level of rigor that personal note-taking does not require. AI annotation demands strict guidelines, multi-layered quality control, and often several annotators labeling the same data to ensure everyone interprets the rules identically. This measurement is called inter-annotator agreement, and achieving a high score is non-negotiable for building a quality dataset that delivers measurable impact.
The table below breaks down these fundamental differences.
Comparing Annotation for Humans vs. Machines
While both involve adding context to text, the purpose and process are worlds apart. Here is a direct comparison of annotating for personal study versus labeling data for a machine learning model.
| Aspect | Academic Annotation (For Human Readers) | AI Data Annotation (For Machine Learning) |
|---|---|---|
| Purpose | Personal understanding, memory aid, or critical analysis. | To create a structured, consistent dataset for training an algorithm. |
| Audience | The individual reader. | A machine learning model. |
| Consistency | Subjective and personal. My highlights can differ from yours. | Objective and standardized. Every annotator must follow the same rules. |
| Guidelines | Informal and flexible. | Strict, detailed, and rigidly enforced. |
| Quality Metric | Personal usefulness. | High inter-annotator agreement and statistical accuracy (>99%). |
| Scale | One document or book at a time. | Thousands or millions of data points. |
| Tools | Highlighters, pens, simple note-taking apps. | Specialized annotation platforms with built-in QA and analytics. |
Ultimately, the stakes are higher with AI. A personal note-taking system only has to work for one person. An AI annotation workflow has to produce a dataset so clean and reliable that a machine can learn to perform a task with near-perfect accuracy and deliver a positive return on investment.
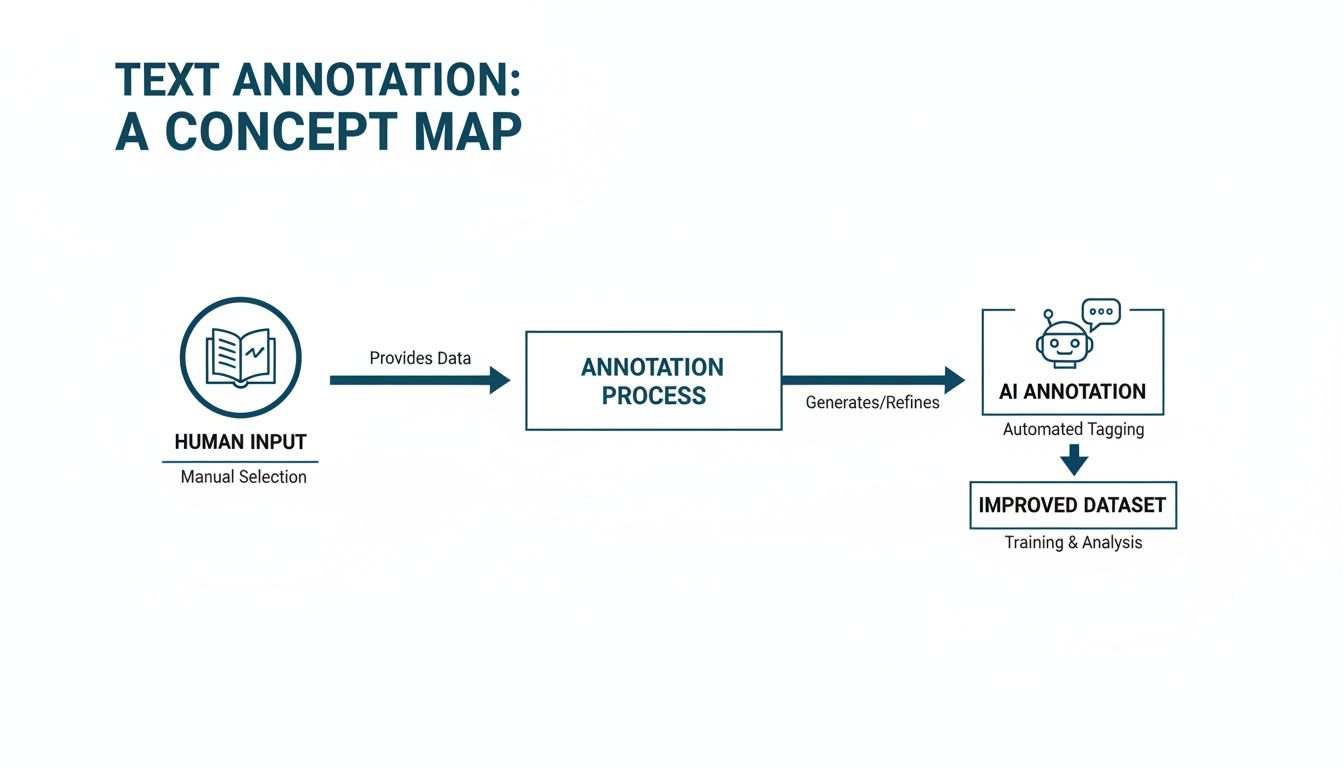
As this workflow shows, the casual act of making a note transforms into a structured, repeatable process for machine learning. The difference in precision is critical. A single inconsistent label can teach an AI model the wrong pattern, leading to flawed outputs and unreliable performance. This is why professional data annotation services are essential for building trustworthy AI that can scale with your business needs.
Exploring Core Text Annotation Techniques

To fully grasp what it means to annotate text for AI, we need to look at the specific methods used to create clean, structured data. These techniques are the fundamental building blocks that teach a machine how to read and interpret human language. Each method solves a different business problem by adding a unique layer of meaning to raw text.
Choosing the right annotation technique is crucial for success. For example, you would not use sentiment analysis to find names in a legal document. Selecting the right tool for the job ensures the resulting AI model provides actionable and accurate insights.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is the process of identifying and categorizing key pieces of information, or "entities," within a block of text. This is like using a set of digital highlighters to mark every person, place, organization, and date in a document. This makes important details stand out for automated processing.
For a business, this is incredibly useful. An AI model trained with NER can instantly scan thousands of resumes to pull out candidate names, former employers, and specific skills. In some recruitment workflows, this reduces manual review time by over 80%, allowing teams to focus on the most qualified applicants and accelerate the hiring process.
By tagging specific nouns and proper names, NER transforms a sea of words into a structured database of actionable information. It is the foundation for any system that needs to answer "who," "what," "when," and "where."
Sentiment Analysis and Text Classification
While NER identifies what the text is about, sentiment analysis determines the feeling behind the words. Annotators label text as positive, negative, or neutral, which in turn teaches an AI to understand customer emotions in reviews, support tickets, and social media posts at scale.
Text classification, a broader but related technique, assigns predefined categories to a piece of text. For instance, an incoming customer email can be automatically classified as a "Billing Inquiry," "Technical Issue," or "General Feedback." We cover more about the various types of annotation techniques in our detailed guide if you want to dive deeper.
When used together, these methods create powerful, automated workflows. A system can spot a negative product review (sentiment analysis) and instantly route it to the customer retention team (text classification). This ensures urgent issues receive a fast response, protecting the brand's reputation and improving customer satisfaction. This direct, measurable impact demonstrates the value of high-quality annotation.
Putting Text Annotation to Work in Your Industry
High-quality text annotation is not just a technical step; it is a strategic advantage that delivers tangible business results. The applications are growing rapidly across all sectors.
At its core, annotating text means meticulously labeling elements like intent or topics within sentences to create a detailed map for AI to navigate the subtleties of human language. This process underpins a global data annotation tools market valued at USD 1.02 billion in 2023, which is projected to reach USD 5.33 billion by 2030. Text annotation makes up a massive 36.1% of that market, driven by its essential role across countless industries. You can dig deeper into this growth in an in-depth industry analysis from Grand View Research.
From Patient Records to Shopping Carts
The return on investment becomes clear when you see how different businesses use text annotation to solve their biggest challenges. Each use case draws a straight line between precise labeling and a measurable outcome.
Healthcare: Hospitals and research clinics use Named Entity Recognition (NER) to extract critical data like diagnoses, medications, and patient IDs from unstructured clinical notes. This organizes vast amounts of information, speeding up medical research and improving diagnostic accuracy.
E-commerce: Online retailers are inundated with customer reviews. They use sentiment analysis to sift through thousands of comments and understand product feedback at scale. This data is invaluable for refining recommendation engines, improving product descriptions, and ultimately boosting sales and customer loyalty.
Annotation transforms raw feedback into a clear signal, allowing businesses to understand what their customers are truly saying and act on it with precision.
Improving Risk Management and Operations
The impact extends far beyond customer-facing applications. Annotation also powers crucial back-office and analytical functions.
In finance, for example, firms train AI models on annotated news articles and reports to track market sentiment in real time. This helps them identify emerging risks and make smarter investment decisions. Similarly, accurate annotation helps streamline everything from legal document review to insurance claim processing, dramatically reducing manual work for expert teams and minimizing the risk of human error.
The Human Intelligence Behind Accurate AI

In the world of AI, there is a simple truth: the quality of your data determines the quality of your results. Achieving the high-accuracy annotation needed for reliable models is not an automated task. It is a process built on human intelligence, robust guidelines, and rigorous quality assurance (QA).
This is where the human-in-the-loop (HITL) approach becomes critical. Algorithms are incredibly powerful, but they fall short when it comes to understanding nuance, context, and ambiguity. Expert human oversight is the essential component that bridges this gap, ensuring every label reflects a deep understanding of the project's goals and delivers the required accuracy.
The process of annotating a text is far more than just tagging words. It is about systematically tagging linguistic features to train AI systems that can mimic human understanding. The demand for this skill is massive. The data annotation tools market was valued at USD 2.87 billion in 2024 and is expected to hit USD 23.82 billion by 2033. This growth is driven by sectors like e-commerce, where annotating product descriptions improves search accuracy by 25-35%. You can explore this market's growth in a detailed report from Straits Research.
The Pillars of Precision Annotation
Achieving over 99% accuracy does not happen by accident. It requires more than just smart people; it demands a structured, multi-layered workflow. Without this foundation, even the most ambitious AI projects are built on shaky ground.
The key components of a high-quality process include:
- Crystal-Clear Guidelines: A comprehensive rulebook that leaves no room for ambiguity.
- Multi-Layered QA: A system of checks and balances where work is reviewed, audited, and validated to ensure consistency.
- Continuous Feedback: A communication loop that connects annotators and reviewers to resolve complex edge cases and refine guidelines.
This commitment to precision is what separates a functional AI model from an exceptional one. It is the human dedication to quality that transforms raw data into a trustworthy, strategic asset.
At Prudent Partners, our 300+ trained analysts operate within this exact framework, ensuring every project is built on a foundation of trust and accuracy. We treat data annotation as a craft, combining human expertise with robust processes to deliver datasets that power reliable, high-performing AI solutions.
Turning Your Annotation Project into a Success
Understanding what text annotation is represents the first step. The real challenge is turning that knowledge into a successful, high-quality project. While the concept seems simple, achieving the accuracy and consistency required, especially at scale, takes proven processes and a skilled team.
This is where you move from theory to execution. Transforming raw, unstructured text into a genuine competitive advantage is where a dedicated partner can make all the difference.
From Concept to Competitive Advantage
At its core, successful annotation adds layers of human interpretation to raw data, teaching machines to understand the nuances of our language. This process turns messy, unstructured text into the clean, structured datasets that NLP models require to perform effectively.
Consider the e-commerce giants in North America and Europe. They use text annotation to tag customer reviews with sentiment, which in turn powers their recommendation engines. This is not a minor tweak; it can boost conversion rates by up to 20-30%. You can learn more about the text annotation market to see just how much this space is growing.
This is not just about putting labels on data; it is about building the very foundation of your AI’s intelligence. Every sentence labeled with precision makes your model stronger. Every inconsistency introduces risk and undermines performance.
The success of an AI initiative is not determined by the complexity of its algorithm alone, but by the quality of the data it learns from. Flawless annotation is the bedrock of dependable AI.
Achieving this level of quality requires a structured, meticulous approach to consistency. Clear annotation guidelines are non-negotiable. They act as the single source of truth for your entire team, ensuring everyone is aligned. Our guide on creating effective annotation guidelines offers a roadmap for establishing the kind of consistency needed for high-stakes projects.
At Prudent Partners, this is exactly what we specialize in. We turn ambitious AI goals into tangible outcomes by providing expert teams, rigorous quality assurance, and scalable processes that deliver datasets with over 99% accuracy.
Every project has unique data challenges. Let’s talk about yours. Connect with our experts today to see how our annotation solutions can power your most important AI initiatives.
Frequently Asked Questions About Text Annotation
When organizations begin exploring text annotation for AI, a few practical questions almost always arise. Let's tackle some of the most common ones.
How Long Does a Typical Text Annotation Project Take?
There is no one-size-fits-all answer. The timeline depends on the volume of data, the complexity of the task, and the required level of accuracy.
A small pilot project might only take a few weeks, providing enough time to test your guidelines and workflow. In contrast, a large-scale enterprise initiative could be an ongoing effort that lasts for months or even years. The best approach is often to start with a pilot to get a realistic sense of the timeline before scaling up.
What Is the Difference Between Text Annotation and Data Labeling?
Think of "data labeling" as the broad umbrella term. It covers adding tags or labels to any kind of data, including images, video, and audio.
Text annotation is a specific, specialized type of data labeling that deals exclusively with text.
So, all text annotation is data labeling, but not all data labeling is text annotation. It is a critical specialty within the broader field.
Can Text Annotation Be Fully Automated?
Not if you require high-quality results. While AI models can perform "pre-labeling" to provide a starting point, they rarely achieve perfect accuracy. The nuances of human language, context, and sarcasm are still too complex for machines to handle alone.
The most effective approach is a "human-in-the-loop" system. In this model, AI provides the first pass, and then human annotators step in to review, correct, and validate the labels. This combination gives you the speed of automation with the accuracy and common sense that only a human can provide, ensuring the final dataset is of the highest quality.
Your AI initiatives are only as good as the data they are trained on. At Prudent Partners LLP, we provide the high-accuracy data annotation and quality assurance needed to build reliable, scalable AI solutions. Connect with our experts today to turn your data challenges into a competitive advantage.