
At its core, AI data annotation services involve labeling data, whether images, text, audio, or video, so a machine learning model can understand and learn from it. Think of it as being the teacher for an artificial intelligence system. The quality of that teaching directly shapes the model's accuracy, performance, and ultimately, its value to your business. Without clean, human-validated data, even the most sophisticated algorithms are bound to fail.
The Hidden Engine Behind Every Successful AI
Behind every powerful AI model is a secret weapon, and it is not just the algorithm. It is the thousands, or even millions, of meticulously labeled data points that taught the AI how to interpret the world. It is a lot like teaching a child to recognize different animals by showing them pictures with clear labels. The AI learns the exact same way, relying on precise examples to build its understanding.
This process is the heart of what AI data annotation services do: they take raw, unstructured data and prepare it for machine learning. Without this step, your data is just noise. An AI designed to spot manufacturing defects cannot identify a flaw it has never been shown, and a medical AI cannot detect a tumor unless it has been trained on countless expertly labeled scans.
From Technical Task to Strategic Imperative
It is a common and costly mistake to see data annotation as just a low-level, technical task. In reality, it is a strategic business decision that directly fuels your outcomes, sharpens model accuracy, and delivers a powerful return on investment. The quality of your annotation sets the performance ceiling for your entire AI initiative.
This critical dependency has ignited explosive growth in the market. In 2024 alone, valuations for the global AI data annotation market ranged from USD 936.30 million to USD 2.3 billion, depending on the research. Even more telling, projections show the market could soar as high as USD 28.5 billion by 2034, proving just how intense the demand for high-quality training data has become.
High-quality data annotation is not an expense; it is an investment in the intelligence and reliability of your AI systems. Inaccurate or inconsistent labels will only lead to flawed models, poor user experiences, and wasted development cycles.
At the end of the day, the success of any AI project comes down to the quality of its training data. When you partner with experts in data tagging and annotation, you are building your models on a foundation of accuracy and precision. This is how raw information gets transformed into a powerful asset, enabling your AI to make dependable, intelligent decisions that drive real business value.
Matching Annotation Techniques to Your AI Project
Not all data annotation is the same. Far from it. The right technique depends entirely on your data and, more importantly, what you want your AI model to actually do.
Think of it like building a house. You would not use a hammer when you need a screwdriver. Choosing the wrong annotation method will only lead to poor results, and it is a core reason why so many AI projects stall. To build a genuinely effective AI, you have to connect the annotation technique directly to a business goal.
Annotation for Images and Videos
Computer vision models learn to "see" by studying millions of labeled pixels. The kind of label you use determines what the AI can recognize, from simply spotting an object to understanding a complex scene.
Let's look at two foundational techniques: bounding boxes and semantic segmentation.
-
Bounding Boxes: This is the most common and straightforward type of image annotation. Annotators draw simple rectangular boxes around objects you care about. It is a fast and efficient way to teach an AI to detect the presence and location of an object. For example, an e-commerce company could use bounding boxes to train a model that identifies every product on a warehouse shelf for automated inventory management.
-
Semantic Segmentation: This is a much more granular technique. Instead of just drawing a box around an object, annotators classify every single pixel in an image. In a medical setting, this allows an AI to distinguish between healthy tissue and a tumor in an MRI scan with incredible precision, outlining the exact shape of the anomaly.
This framework shows how high-quality data, precise annotation, and continuous feedback loops all work together to build more accurate AI models.
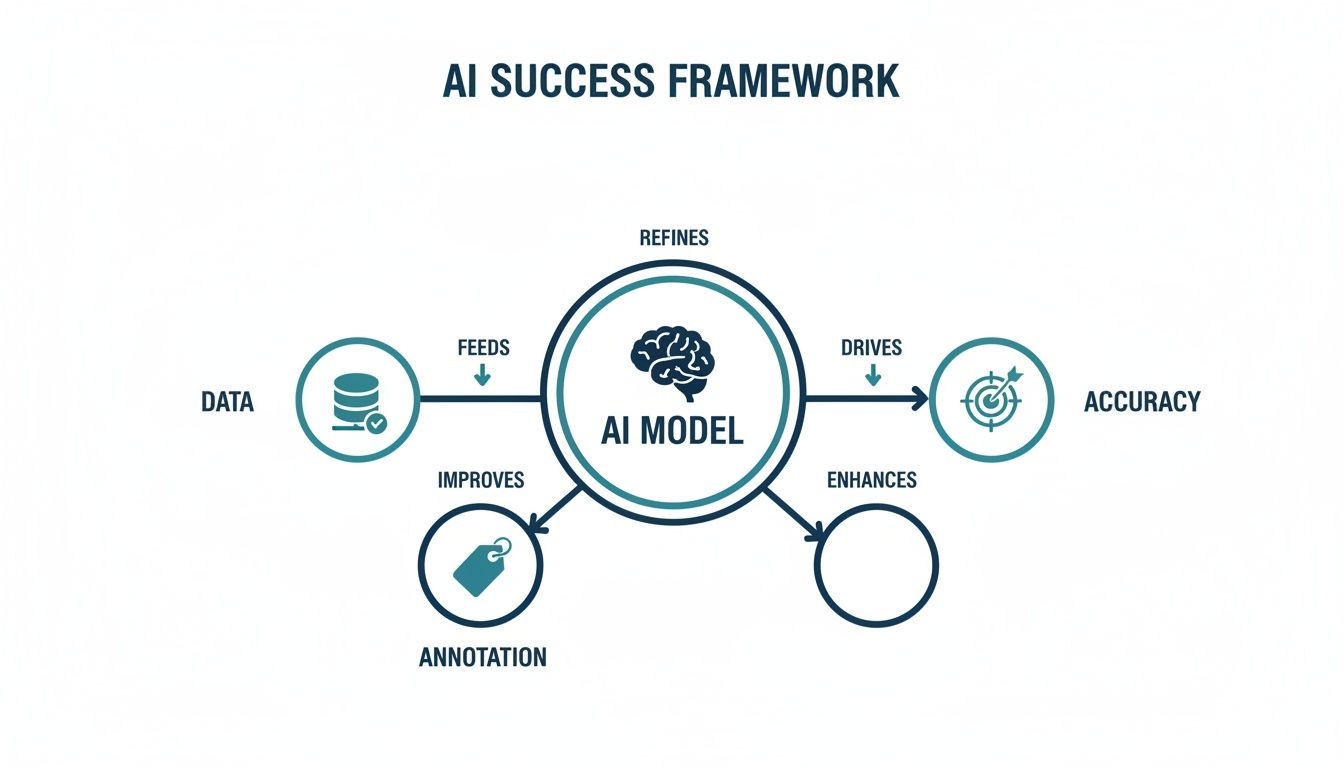
As the diagram makes clear, a successful AI model is not a one and done product. It is an interconnected system where accurate data annotation is a critical pillar supporting the entire structure.
Annotation for Text and Language
For models that work with language, the goal is to add structure and meaning to messy, unstructured text. This is where techniques like Named Entity Recognition (NER) and sentiment analysis come in, teaching AI to understand human communication.
By transforming raw text into structured data, annotation allows AI to extract valuable business intelligence from documents, customer feedback, and financial reports.
Named Entity Recognition (NER) is all about identifying and categorizing key pieces of information in a text, like names of people, organizations, locations, and dates. A financial firm might use NER to automatically pull client names, company mentions, and transaction dates from thousands of contracts, slashing manual review time. Our work on Gen AI quality assurance often involves a human-in-the-loop to validate these extracted entities for total accuracy.
Sentiment Analysis involves labeling text with an emotional tone, think positive, negative, or neutral. This is incredibly powerful for understanding customer feedback at scale. An airline, for instance, could analyze thousands of social media mentions and reviews. By using sentiment analysis, they can quickly spot patterns of customer frustration and fix service issues before they turn into bigger problems.
To bring this all together, here is a quick look at how different industries match annotation types to their specific AI goals.
Matching Annotation Type to AI Application
| Industry | AI Application | Required Annotation Type | Example Use Case |
|---|---|---|---|
| Healthcare | Medical Imaging Diagnostics | Semantic Segmentation | Precisely outlining tumors in MRI scans to assist radiologists. |
| E-commerce | Automated Inventory Management | Bounding Boxes | Identifying and counting products on warehouse shelves via camera feeds. |
| Geospatial | Land Use Classification | Polygon Annotation | Mapping agricultural fields, forests, and urban areas from satellite imagery. |
| Finance | Contract Analysis | Named Entity Recognition (NER) | Extracting client names, dates, and monetary values from legal documents. |
Ultimately, choosing the right annotation method ensures your AI model gets the exact training data it needs to perform reliably and deliver real business value. This strategic alignment is what separates a proof-of-concept from a successful, production-ready AI solution.
The Unseen Engine Driving AI Industries
The explosion in demand for AI data annotation services is not happening in a vacuum. It is a direct consequence of massive, industry-wide investments in artificial intelligence. Think of it as a powerful ripple effect: for every dollar poured into AI development, there is a corresponding need for high-quality, expertly labeled data to make it work. As companies race to deploy AI, they are all hitting the same fundamental truth, their algorithms are only as smart as the data they are trained on.
This symbiotic relationship is exactly what is fueling the market’s incredible growth. The broader AI market, valued at USD 371.71 billion in 2025, is on a trajectory to hit an astonishing USD 2.41 trillion by 2032. A huge chunk of that investment gets funneled directly into the foundational work of data preparation and annotation. As companies commit billions to building intelligent systems, they have to invest in the human-powered services that teach those systems how to think. You can explore more research about this interconnected growth and its market impact.
Fueling Breakthroughs in Healthcare
Nowhere is this connection more critical than in healthcare. The industry is on track to invest over USD 15 billion in AI solutions by 2027, driven by the need to improve diagnostics, personalize treatments, and make operations more efficient. But these advanced applications are entirely dependent on meticulously annotated medical data.
Take these high-stakes examples:
- Diagnostic AI: To train an AI that can spot the earliest signs of cancer in an MRI or X-ray, every single pixel of that medical image must be precisely segmented. Radiologists and trained annotators work hand-in-hand to outline tumors, lesions, and other anomalies, teaching the model to see patterns a human eye might miss.
- Clinical Decision Support: AI systems that guide doctors toward the best treatment plans are trained on enormous datasets of electronic health records (EHRs). This requires expert text annotation to pull out and label symptoms, medications, patient outcomes, and lab results, turning messy clinical notes into structured, usable data.
For these life-saving AI models, accuracy is not just a goal; it is non-negotiable. This is why specialized AI data annotation services with deep domain expertise are so essential for healthcare innovation. We support medical AI companies by providing the high-accuracy annotation needed to build diagnostic tools people can trust.
Securing the Financial Sector
The financial services industry is another major force, projected to spend around USD 30 billion on AI by 2030. Here, the focus is on fraud detection, risk assessment, and algorithmic trading, all of which rely on flawlessly annotated data to function.
In finance, a single mislabeled transaction or a poorly interpreted document can lead to significant financial losses or regulatory penalties. Precision is paramount.
For instance, building a truly robust fraud detection algorithm means training it on millions of transaction records. Human annotators have to label each one as either legitimate or fraudulent, identifying the subtle patterns that signal illegal activity. In the same way, AI models built for risk assessment must be fed annotated financial reports and market data to learn how to predict volatility.
This relentless drive for AI-powered solutions creates a virtuous cycle. As more organizations adopt AI, the demand for annotated data skyrockets. This, in turn, fuels the growth of specialized service providers like Prudent Partners, who can deliver the accuracy, scale, and security these high-stakes industries demand.
Building a Bulletproof Quality and Security Framework
When it comes to high-stakes AI in fields like healthcare or finance, “good enough” data simply is not good enough. One bad label can send a model off the rails, leading to flawed decisions and a complete loss of trust. This is exactly why top-tier AI data annotation services are built on a non-negotiable foundation of quality and security.
It all starts with a robust Quality Assurance (QA) workflow. This is not just a quick check at the end of the line; it is a multi-layered system designed to enforce precision from the very first annotation. The real goal is to produce datasets that are not only accurate but consistently and verifiably so, creating the "ground truth" your AI model needs to perform reliably.

The Anatomy of a Robust QA Workflow
A truly effective QA process is about more than just catching mistakes, it is about creating a system of checks and balances that makes data integrity the default outcome. This framework includes a few non-negotiable parts that work together to push accuracy toward 99% and beyond.
-
Multi-Level Review Cycles: Annotation is never a one and done job. A proper workflow involves an initial annotation followed by at least one or two review cycles from more senior annotators or dedicated QA specialists. This hierarchy is what catches subtle errors and ensures every label sticks to the project guidelines.
-
Consensus Models and Inter-Annotator Agreement (IAA): To root out subjectivity, multiple annotators will often label the exact same piece of data without seeing each other's work. If their labels match, it is approved. If not, a senior reviewer steps in to make the final call. This approach is absolutely critical for keeping labels consistent, especially with large teams working remotely.
-
Continuous Feedback Loops: The job is not over once the data is labeled. A true partnership thrives on constant communication between the annotation team and your own project managers. This feedback loop is essential for refining guidelines, clarifying tricky edge cases, and making sure everyone is perfectly aligned on your goals. You can see how we build clear instructions in our guide to annotation guidelines.
A world-class QA framework is not just about catching mistakes; it is a systematic process designed to prevent them from happening in the first place. It combines human expertise, statistical validation, and collaborative refinement to produce data you can depend on.
Fortifying Data with Enterprise-Grade Security
Just as crucial as quality is the security of your data. When you are dealing with sensitive information, think patient records, financial data, or proprietary IP, security cannot be an afterthought. It has to be baked into every single step of the annotation process.
Reputable partners prove their commitment to security with internationally recognized certifications and compliance with strict regulations. These are not just logos on a website; they are hard-earned proof of a tested and validated security posture.
Here are the key credentials to look for:
- ISO/IEC 27001: This is the global gold standard for Information Security Management Systems (ISMS). A provider with this certification has implemented rigorous, audited controls for data protection, risk management, and operational security.
- GDPR Compliance: If your project involves data from EU citizens, GDPR compliance is mandatory. It guarantees strict protocols for how data is handled, stored, and protected.
- HIPAA Compliance: In healthcare, the Health Insurance Portability and Accountability Act is the law of the land for protecting sensitive patient information. A HIPAA-compliant partner ensures all medical data is handled with the highest level of confidentiality.
By prioritizing both a meticulous quality framework and an impenetrable security posture, you ensure your AI projects are built on a foundation of trust. This dual focus is what gives you the confidence to deploy models in the real world, where accuracy and data protection matter most.
Decoding Pricing and Partnership Models
Picking an AI data annotation service is about more than just tech specs and accuracy scores. You also need a partnership and pricing model that fits your budget, timeline, and goals. The way your deal is structured will make or break your project's cost-effectiveness and ability to scale.
Think of it this way: you are not just hiring a vendor, you are bringing on a partner. The right model ensures you get the expertise you need without paying for things you do not, creating a clear and predictable financial relationship from day one.
Comparing Common Pricing Structures
Data annotation providers generally stick to three main pricing models. Each has its own sweet spot, and the best choice really hinges on how complex your project is, how much data you have, and how predictable you need your costs to be.
-
Per-Annotation Model: This is as straightforward as it gets. You pay a fixed price for each item labeled, whether it is an image, a sentence, or a single video frame. It is perfect for high-volume, repetitive tasks where you need clear cost predictability.
-
Per-Hour Model: With this model, you are paying for an annotator's time. This works much better for complex or exploratory projects where it is tough to guess how long each annotation will take, think nuanced sentiment analysis or tricky semantic segmentation.
-
Dedicated Team (FTE) Model: Here, you get a full-time equivalent (FTE) team of annotators working exclusively on your projects. This is the go-to for long-term, massive initiatives that demand deep domain expertise and a tight, collaborative relationship with the annotation team.
Choosing the right pricing model is a strategic decision. A per-annotation model optimizes for simple, repetitive tasks, while an FTE model builds a dedicated, expert extension of your own team for complex, ongoing work.
To make this even clearer, let's break down when each model shines.
Choosing the Right Pricing Model for Your Project
A comparison of common data annotation pricing models to help buyers select the most cost-effective and suitable option for their specific project requirements.
| Pricing Model | Best For | Pros | Cons |
|---|---|---|---|
| Per Annotation | High-volume, simple tasks like bounding boxes or basic classification. | – Cost predictability – Easy to budget – Scalable for repetitive work |
– Can be expensive for complex tasks – Less flexibility for exploratory projects |
| Per Hour | Complex, nuanced, or R&D-stage projects with unclear time requirements. | – Flexible for evolving requirements – Ideal for intricate tasks – Pay only for time worked |
– Less cost predictability – Requires close project monitoring |
| Dedicated Team (FTE) | Large-scale, long-term projects requiring deep domain expertise and continuous work. | – Deep team integration & expertise – Consistent quality & workflow – High-touch collaboration |
– Higher initial investment – Less flexible for short-term projects |
Ultimately, the best model lines up with your project’s unique demands. Simple, high-volume work fits the per-annotation model, while a long-term, complex partnership is built for the FTE approach.
Fully Managed Services vs. Platform-Based Approaches
Beyond just the price tag, you need to decide on an engagement model. This choice comes down to one simple question: how much control do you want over the annotation process?
A platform-based approach gives you access to powerful software, but your team is on the hook for managing everything, the entire workflow, QA, and the annotators themselves. This can work if you have experienced project managers in-house and want to use specific data labeling tools for your projects.
On the other hand, a fully managed service, like what we offer at Prudent Partners, is a complete, end-to-end solution. This does not just include annotators; you get dedicated project managers, QA specialists, and a battle-tested operational framework. This model is ideal for teams that want to offload the headaches of data annotation and focus on what they do best: building great AI.
With a fully managed service, you get guaranteed quality, predictable timelines, and the freedom to scale your project up or down without the pain of hiring and training your own workforce. For most companies, this approach delivers a much stronger return on investment, turning a complex process into a reliable service that gets your AI to market faster.
How to Select the Right Data Annotation Partner
Choosing a partner for your AI data annotation services is one of the most important calls you will make for your entire AI project. This is not just about finding a vendor; it is about finding a team that acts as a true extension of your own. The right choice directly impacts your model's accuracy, your timeline, and your data's security.
To get it right, you have to look past the sales pitches and start asking the tough, specific questions. This framework will help you cut through the noise and find a partner who is transparent, capable, and genuinely invested in your success.
Evaluating Technical and Operational Excellence
First, you need to look under the hood. A partner's day-to-day operations are the engine that drives quality and speed. A team with mature, well-managed systems will have no problem giving you straight answers about how they work.
Here are the questions I always start with:
- Quality Assurance: "Can you walk me through your complete quality assurance methodology?" Do not settle for a simple "we check our work." Look for specifics like multi-level review cycles, consensus models, and clear feedback loops. A great answer will detail exactly how they hit and maintain accuracy rates of 99% or higher.
- Team Management: "How do you train, manage, and retain your annotation teams?" This question tells you how much they invest in their people. A good partner will talk about their in-depth onboarding, continuous training on project-specific rules, and what they do to keep their teams consistent and motivated.
- Technology Stack: "What tools and platforms do you use for annotation and project management?" Ask if they use AI-assisted labeling to work smarter and whether they can plug into your existing systems. At Prudent Partners, we built our own platform, Prudent Prism, to give our clients total visibility into every project metric.
Assessing Domain Expertise and Scalability
A partner must do more than just label data, they need to understand it. Generic annotation experience falls short when you are dealing with complex data like medical scans, financial contracts, or satellite imagery. They also need to prove they can grow with you.
A partner with deep domain expertise gets the nuances of your data. That means more accurate labels, fewer costly revisions, and a much smoother project. This is what separates a simple vendor from a strategic partner.
Ask these questions to see if they have the expertise and scale you need:
- Industry Experience: "Could you share case studies or examples of projects you've completed that are relevant to our industry?" This is where they show you, not just tell you. You want to see real proof that they have handled data like yours, whether it is for healthcare, finance, or geospatial intelligence.
- Scalability: "What is your process for scaling a team from a pilot project to a full-scale production workload?" A reliable partner will not just say "we will add more people." They will have a clear, documented process for ramping up resources without letting quality slip.
- Security and Compliance: "What are your specific protocols for data security and regulatory compliance (e.g., ISO 27001, HIPAA, GDPR)?" For high-stakes industries, this is non-negotiable. They must be able to walk you through their security setup and back it up with recognized certifications.
Using this structured approach, you can systematically vet potential partners. You will move beyond a simple vendor search and find a team that will not only deliver clean data but will help guarantee the long-term success of your AI goals.
Your Questions Answered: What to Expect from an AI Data Annotation Service
Diving into the world of AI data annotation can feel complicated, and it is natural to have practical questions. To help you make a smart decision, here are clear, straightforward answers to the queries we hear most often from AI and machine learning teams.
How Much Do Data Annotation Services Cost?
The honest answer? It varies a lot. The cost of data annotation is not a one-size-fits-all number, and it really comes down to a few key factors. The pricing model you go with (per-annotation, per-hour, or a dedicated team) is a big one, but the complexity of the task itself is just as important.
For example, drawing simple bounding boxes around cars in an image is far less expensive than performing pixel-perfect semantic segmentation on a medical MRI. Likewise, if your project requires specialized knowledge (like certified radiologists for medical data) or you have a massive volume of data, that will shape the final price. Any partner worth their salt will give you a detailed cost breakdown based on your project's specific needs.
How Do You Guarantee the Quality of the Annotations?
This is easily the most critical part of the whole process. High-quality annotations are everything, and reputable providers do not leave it to chance. They build quality assurance (QA) right into their workflow with a multi-layered framework.
A common approach is a consensus model, where several annotators label the same piece of data. Their work is then compared to ensure everyone is on the same page. Beyond that, a senior review process is essential, this is where experienced QA specialists spot-check a sample of the annotated data against your project guidelines. This, combined with a constant feedback loop between your team and the annotators, is how you handle tricky edge cases and push accuracy rates to 99% or higher.
What’s the Typical Turnaround Time for a Project?
Project timelines are completely tied to the scope, complexity, and scale of your annotation needs. A small pilot project with a few thousand images might just take a week or so. On the other hand, a huge initiative involving millions of data points could be a multi-month effort.
The best AI data annotation services will sit down with you during the initial consultation to map out a realistic timeline. Things like the number of annotators on the project, the difficulty of the labeling task, and how efficient the QA process is will all play a part in the final delivery schedule. Clear project management and regular check-ins are key to making sure everything stays on track.
Ready to build your AI model on a foundation of accuracy and trust? The team at Prudent Partners provides high-quality, secure, and scalable data annotation services designed for your specific industry needs. Connect with our experts today to start a pilot project and see the difference precision makes.