
Text annotation is, at its core, the process of adding labels or tags to pieces of text. This simple act is what makes raw, unstructured text understandable to a machine learning model, effectively teaching an AI to recognize human language, context, and intent.
How Text Annotation Powers AI Models

Think of a massive, unorganized library. Millions of books, but no card catalog. Finding anything specific would be nearly impossible. Raw, unstructured text is that chaotic library to an AI. Text annotation is the meticulous process of carefully labeling each sentence and phrase to give it structure and meaning.
This process is what transforms messy data into a high-quality asset that machines can actually learn from. Just like a librarian tags a book with its genre, author, and key themes, an annotator labels words or sentences with predefined categories. This labeled data becomes the foundation for countless AI applications, from your bank's chatbot to Google's search engine.
The Foundation Of Language Understanding
High-quality annotation is not just a technical step; it is the fundamental process that teaches an AI model to grasp the nuance and intent behind human language. Without it, a model cannot tell the difference between a glowing customer review and a sarcastic complaint. It cannot identify a person’s name versus a company’s name in a legal contract.
The performance of any AI model is directly tied to the quality of the data it's trained on. Inconsistent or inaccurate labels inevitably lead to unreliable, biased outcomes. This makes text annotation a critical strategic priority for any organization building dependable AI. To dive deeper into its strategic value, you can explore more on why data annotations are important.
An AI model is only as intelligent as the data it learns from. Precision in text annotation is the difference between an AI that merely processes words and one that truly comprehends meaning, driving accurate predictions and reliable automation.
Delivering Measurable Business Outcomes
Ultimately, the point of annotation is to build AI that delivers tangible business results. By investing in precise and scalable data labeling, organizations unlock significant improvements across the board. The impact is direct and measurable, from accelerating data analysis to enhancing the customer experience.
The following table highlights a few core business outcomes driven by expertly annotated text.
Core Business Outcomes from High-Quality Text Annotation
| Business Function | Annotation Application | Measurable Impact |
|---|---|---|
| Customer Support | Sentiment Analysis | 25% reduction in ticket resolution time |
| E-commerce | Product Categorization | 15% increase in search relevance and sales |
| Finance | Named Entity Recognition | 40% faster document processing for compliance |
| Healthcare | Relation Extraction | Improved accuracy in medical record analysis |
As you can see, precise annotation is not just a cost center; it's a direct driver of efficiency, revenue, and better decision-making.
Essential Types Of Text Annotation

Annotation of text is not a single, one-size-fits-all task. It is a collection of specialized techniques, each designed to teach AI a different way to understand human language. These methods range from identifying simple names and places to mapping out complex relationships between ideas.
Choosing the right approach is everything. It is what allows a business to solve a specific problem, whether that’s making a chatbot more helpful or speeding up financial risk analysis. Each type of annotation acts as a building block, giving AI models a progressively deeper grasp of unstructured text.
This foundational work is so crucial that it now represents about 34% of the entire global data annotation tool market, according to Fortune Business Insights. That huge share shows just how vital text labeling has become for training the language models and conversational AI systems we rely on every day.
Named Entity Recognition (NER)
Named Entity Recognition, or NER, is one of the most fundamental and widely used forms of text annotation. At its core, it is about identifying and categorizing key pieces of information into predefined classes. Think of it as using digital highlighters to tag specific nouns that you want an AI to recognize on sight.
Common entities tagged with NER include:
- People: Names of individuals (e.g., "Jane Smith")
- Organizations: Companies, agencies, or institutions (e.g., "Prudent Partners")
- Locations: Cities, countries, or specific addresses (e.g., "Chicago")
- Dates and Times: Any reference to time (e.g., "Q4 2024")
- Monetary Values: Currency and financial figures (e.g., "$50 Million")
For instance, a law firm could use NER to automatically scan thousands of pages of discovery documents. A well-trained model can instantly pull out every person, company, and date mentioned, saving attorneys hundreds of hours of manual review.
Sentiment Analysis And Opinion Mining
It is one thing to know what someone is saying; it's another to know how they feel about it. That is where sentiment analysis comes in. This annotation type involves labeling a piece of text with its emotional tone, usually as positive, negative, or neutral.
Imagine an airline monitoring Twitter mentions after a holiday weekend. An annotator would go through customer tweets and tag them. "Our flight was on time and the crew was amazing!" gets labeled positive. "Stuck on the tarmac for three hours. Never again." is obviously negative. This lets the AI quickly quantify customer satisfaction, spot emerging problems, and route urgent complaints to the right team.
By systematically labeling the sentiment in customer feedback, businesses can transform a flood of unstructured comments into structured, actionable data, a clear signal for what to improve in their products, marketing, and support.
Text Classification And Categorization
Text classification is a broader task where an entire document or block of text is assigned a single label from a predefined list of categories. It is all about sorting and routing massive volumes of information with speed and accuracy.
Think about the support inbox for a large software company, which might get thousands of emails every day. With text classification, each ticket can be sorted automatically:
- An email mentioning "login error" is classified as a Technical Issue.
- A message asking "what's my invoice number?" is categorized as a Billing Question.
- A query about "new features" is routed to the Sales team.
This automation ensures every inquiry lands in the right hands almost instantly, which is a game-changer for response times and overall efficiency.
Relation Extraction
While NER is great at finding individual entities, relation extraction takes the next logical step: it identifies and labels the semantic relationships between those entities. This is a more advanced form of annotation of text that helps AI understand context and how different concepts connect.
In a medical research setting, an annotator might analyze a clinical trial summary.
- First, they would use NER to tag entities like a drug ("Lisinopril") and a condition ("hypertension").
- Next, they would use relation extraction to label the link between them as "is a treatment for".
By doing this across thousands of documents, an AI can build a massive knowledge graph. This helps researchers spot treatment patterns, flag potential drug interactions, and accelerate new discoveries. To get a complete overview of all the different methods, you can learn more about the different types of data annotation we handle.
Designing Annotation Guidelines For Consistency

Before a single label gets applied, you have to lay the foundation. For any successful annotation of text project, that foundation is a comprehensive set of annotation guidelines. Think of it as the architectural blueprint for your entire AI model.
Without one, asking a team of annotators to produce consistent results is like telling multiple construction crews to build a house without sharing a single plan. You would get chaos. One team’s idea of a "window" would clash with another's, leading to structural flaws. In text annotation, the consequences are just as severe. Ambiguous rules force annotators to guess, introducing inconsistencies that directly poison the AI model's performance.
The Core Components Of A Strong Guideline
A rock-solid set of guidelines goes way beyond simple definitions. It must anticipate ambiguity and provide crystal-clear instructions for every possible scenario, especially the tricky "edge cases" where labels might overlap or context is fuzzy. This document is the only way to get your entire annotation workforce rowing in the same direction.
To build this blueprint, your guidelines must meticulously detail a few key things:
- Clear Definitions: Give precise, easy-to-understand descriptions for every single label or category. No jargon.
- Positive Examples: Show clear, correct examples of each label used in context. This helps annotators see exactly what you want.
- Negative Examples: Even more important, show examples of what not to label. This is often the fastest way to clarify boundaries.
- Edge Case Resolution: You have to make a call on confusing scenarios. For example, is "New York" a GPE (Geo-Political Entity) or a Facility (like an airport)? Your guidelines must decide.
When you address these things upfront, you drastically cut down on the guesswork. This proactive clarity does not just improve accuracy; it also speeds up the entire annotation workflow, saving you from costly rework down the line. To see how we approach this critical step, learn more about our expert-built data annotation guidelines.
Example Guidelines For Sentiment Analysis
Let's say you're building a model to track customer sentiment on social media. Your guidelines need to be incredibly specific to capture the nuances of human language. A basic "Positive, Negative, Neutral" schema will fall apart the second it meets the real world.
The goal of an annotation guideline is to translate a complex business objective into a series of simple, repeatable, and unambiguous tasks for an annotator. It is the bridge between AI strategy and ground-level execution.
A much more effective schema would look something like this:
Sentiment Analysis Schema
- Positive: Expresses clear satisfaction, excitement, or praise.
- Example: "I love the new update, it runs so much faster!"
- Negative: Shows clear frustration, disappointment, or criticism.
- Example: "The app crashed three times today. This is unacceptable."
- Neutral/Informational: States facts, asks questions, or contains no emotional language.
- Example: "What time does the webinar start tomorrow?"
- Mixed: Contains both positive and negative elements in the same comment.
- Example: "The customer service was great, but the product broke after one week."
This level of detail ensures that every annotator, no matter their background, labels text the same way, every time. It is what turns the annotation of text from a subjective art into a repeatable science, creating the kind of reliable, high-quality data that powerful AI models depend on.
Implement Quality Assurance for Reliable AI
Even the most detailed annotation guidelines are only as good as their execution. Turning that blueprint into consistently high-quality results demands a systematic, multi-layered quality assurance (QA) process. Think of it as the factory floor where raw labeled data is inspected, refined, and validated to meet the rigorous standards needed to build a reliable AI model.
Without a strong QA framework, errors and inconsistencies will inevitably slip through, poisoning your dataset and undermining your AI’s performance. A smart workflow, on the other hand, not only catches mistakes but also reinforces best practices, creating a feedback loop of continuous improvement. The goal is not just to find errors; it is to build a system that makes accuracy the default outcome without killing productivity.
Measuring Consistency With Inter-Annotator Agreement
When you have multiple people annotating text, how do you make sure they’re all on the same page? The answer lies in measuring Inter-Annotator Agreement (IAA), a statistical method that quantifies just how much consensus exists among your annotators.
A high IAA score is a great sign. It means your guidelines are clear and your team is applying them consistently. A low score, however, is a major red flag. It signals that your instructions are ambiguous, or your team needs retraining. Calculating IAA is not just an academic exercise; it's a vital diagnostic tool that gives you objective, data-driven insights into the health of your entire annotation pipeline.
Quality assurance in text annotation isn't about finding fault. It’s about building a system of checks and balances that makes accuracy inevitable. It transforms individual effort into a collective, reliable output that AI models can trust.
Establishing Benchmarks With Gold Standard Datasets
To truly measure performance, you need a single source of truth. A gold standard dataset (often called a ground truth dataset) serves exactly that purpose. This is a smaller, representative sample of your data that has been meticulously annotated by your most experienced experts or project leads, creating a "perfect" set of labels.
This gold standard set then becomes your yardstick for several key tasks:
- Benchmark Annotator Performance: By comparing an annotator’s work against the gold standard, you can calculate their individual accuracy scores. This helps you spot your top performers and identify who might need a bit more coaching.
- Calibrate Model Evaluation: Before you even start training, you can test your model's initial performance against this perfect data to get a clear baseline.
- Onboard New Annotators: Gold standard sets are fantastic training tools, giving new team members clear, verified examples of what "right" looks like from day one.
This benchmarking process turns quality control from a subjective review into a measurable science.
Single-Pass Versus Multi-Pass Review Workflows
Choosing the right review workflow is a critical decision that balances speed, cost, and the level of accuracy you need. The two main approaches are single-pass and multi-pass annotation.
A single-pass workflow is straightforward: one annotator labels a piece of data, which is then checked by a QA manager or reviewer. It is faster and more cost-effective, making it a good fit for simpler projects where the guidelines are clear and an accuracy target of around 95% is acceptable.
Conversely, a multi-pass workflow is built for maximum precision. In this model, two or more annotators label the same data independently. Their results are then compared. If they match, the label is approved. If they disagree, a senior reviewer makes the final call. This consensus-based approach is essential for complex projects with nuanced guidelines, and it's how teams regularly achieve accuracy rates exceeding 99%.
The Power of Continuous Feedback Loops
The most effective QA systems are built on communication. A continuous feedback loop between annotators, reviewers, and project managers is the secret sauce for refining your process and improving results over time. When a reviewer finds an error, they shouldn't just fix it and move on.
Instead, the error should be flagged and sent back to the original annotator with clear, constructive feedback explaining the mistake. This simple step closes the loop, turning every correction into a valuable learning opportunity. At Prudent Partners, we manage this entire lifecycle on our proprietary platform, Prudent Prism. It gives managers real-time visibility into accuracy rates, throughput, and individual performance, making it easy to spot trends and step in with targeted training exactly when it's needed.
Choosing Your Annotation Partner: In-House vs. Outsourcing
Once your annotation guidelines are locked in and you know what quality looks like, you’ll hit a major fork in the road. Who is actually going to do the annotation of text? This decision, whether to build your own team or partner with a specialized firm, will shape your project's cost, speed, scalability, and even its security.
There is no magic answer here. The right choice comes down to your company's goals, resources, and long-term AI strategy.
The Case For An In-House Team
Building an in-house team gives you the ultimate control. You get to handpick every annotator, immerse them in your data science culture, and keep a direct line of sight over the entire process. This is often the default choice for projects with extremely sensitive intellectual property where keeping everything under your own roof is a dealbreaker.
But that control comes at a steep price.
Finding, training, and managing a dedicated annotation team is a heavy lift. It demands more than just labeling skills; it requires expertise in workforce management, QA, and workflow optimization. For most companies, especially those whose annotation needs come in waves, the overhead can be a huge bottleneck, slowing down the very AI initiatives you're trying to accelerate.
Evaluating Scalability And Expertise
This is where bringing in a specialized partner like Prudent Partners changes the game. A seasoned provider gives you instant access to a large, trained workforce. This means you can ramp your annotation capacity up or down on a dime, a level of agility that’s nearly impossible to match with a fixed internal team.
More importantly, these partners bring battle-tested expertise to the table. They have already figured out the best practices for everything from creating clear guidelines to running complex QA workflows, knowledge gained from thousands of projects. You're not just hiring labelers; you're plugging into a fully managed service engineered for precision and speed.
The demand for this kind of expertise is fueling massive growth in the data annotation market. Valued at around USD 1.69 billion in 2025, the global market is projected to skyrocket to between USD 12.42 billion and USD 44.68 billion by the early 2030s. You can explore more data on this explosive trend from Precedence Research.
The Security And Compliance Advantage
For companies in tightly regulated fields like healthcare or finance, data security is everything. While keeping data in-house might feel safer, a dedicated partner with top-tier certifications often provides a stronger security posture. For example, Prudent Partners is ISO 27001 certified, which means our information security systems meet tough international standards.
This certification is your assurance that data is handled in a secure, audited environment with strict access controls. Achieving that same level of compliance on your own is a costly, time-consuming effort, making a certified partner a smarter, safer choice for sensitive information.
This decision tree shows a key quality checkpoint you'll need to consider, whether you're working in-house or with a partner.
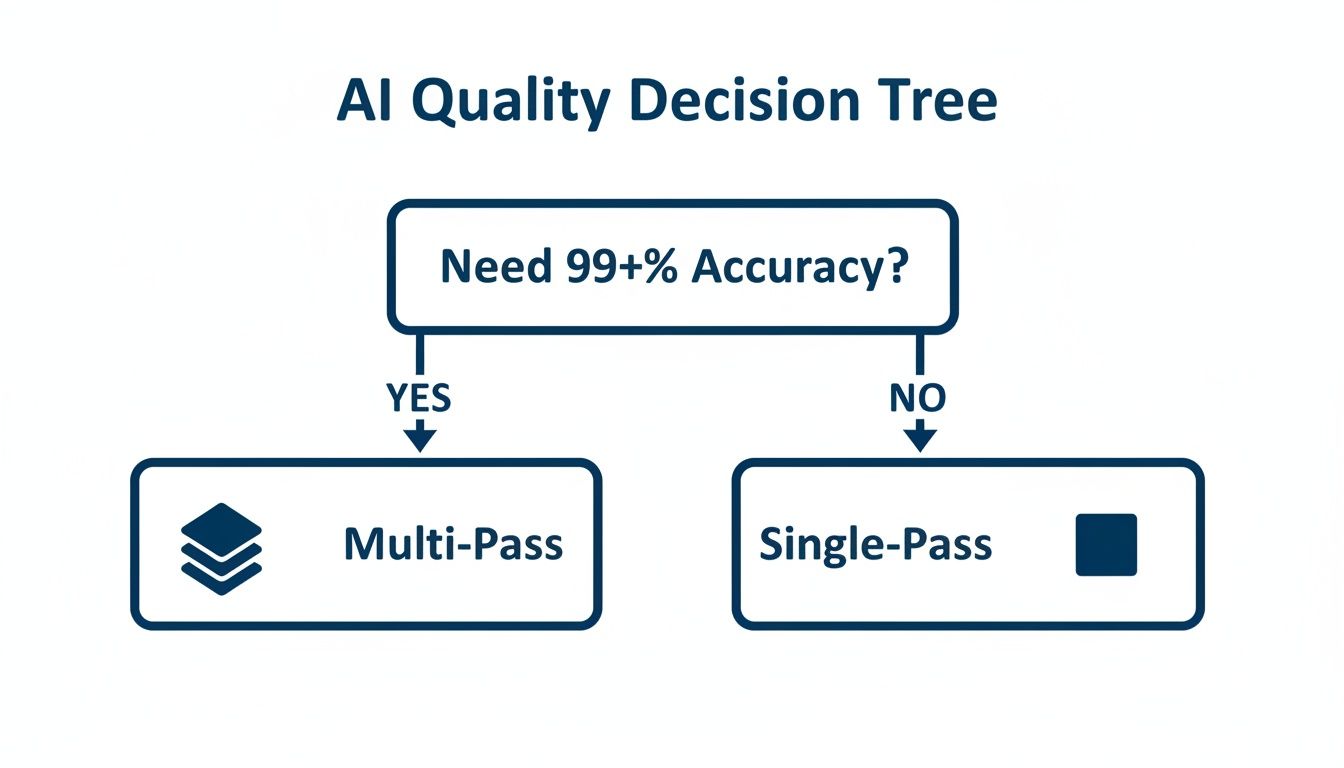
As the flowchart shows, projects that demand the absolute highest accuracy, often over 99%, simply can't rely on a single pass. They require a multi-pass review workflow to guarantee that level of reliability.
Decision Framework: In-House vs. Outsourced Text Annotation
To make this choice clearer, we have broken down the key factors in a head-to-head comparison. This table helps you weigh the trade-offs between building your own team and bringing in an expert partner.
| Factor | In-House Annotation Team | Outsourced Annotation Partner (e.g., Prudent Partners) |
|---|---|---|
| Control & Oversight | Maximum control. Direct management of annotators and workflow. | High control via partnership. Defined SLAs, transparent reporting, and dedicated project management. |
| Cost Structure | High upfront & fixed costs. Salaries, benefits, training, software, and management overhead. | Variable operational expense. Pay-per-project or per-hour model, converting capex to opex. |
| Scalability | Limited and slow. Scaling requires new hiring and training cycles. | Rapid and flexible. Scale workforce up or down instantly to meet project demands. |
| Speed to Market | Slower. Time needed for recruitment, onboarding, and process development. | Faster. Immediate access to a trained workforce and established workflows. |
| Expertise & Quality | Developed internally over time. Requires building QA processes from scratch. | Immediate access to proven expertise. Leverages battle-tested QA frameworks and best practices. |
| Data Security | Managed internally. Requires building and maintaining compliant security infrastructure. | Often higher. Certified partners (ISO 27001, HIPAA) provide audited, enterprise-grade security. |
| Focus of Core Team | Distracted by management. Internal AI/data science teams are pulled into managing a labeling workforce. | Focused on core mission. Your experts can focus on model development, not managing annotation logistics. |
Ultimately, the best path depends on your specific needs, but for most organizations seeking speed, scale, and proven quality, an outsourced partner provides a clear strategic advantage.
Making The Right Strategic Choice
So, how do you decide? An in-house team might be the right call if your project is small, involves top-secret IP, and you already have the resources to manage a team effectively.
For most organizations that need to move fast, scale efficiently, and get it right the first time, outsourcing is the more strategic move. You trade a massive capital investment for a predictable operational cost. You get a scalable talent pool and world-class QA without the management headache.
This frees up your data science and AI teams to do what they do best: build brilliant models, not manage a labeling workforce.
Prudent Partners offers a model that gives you the security of a certified provider with the flexibility you need to grow. Our approach, from the first call to our comprehensive AI quality assurance services, is designed to feel like an extension of your own team, delivering the high-quality annotated data you need to win.
Your Next Steps For Flawless Annotation
Getting text annotation right is not a single task; it is a journey. It starts with understanding the basic concepts and moves all the way to high-stakes execution where your AI’s performance is on the line. Success comes from getting the sequence right. First, you nail down the specific annotation types your model needs. Then, you design rock-solid guidelines that leave no room for guesswork. Finally, you lock in a tough quality assurance workflow to keep everything consistent. Each step builds on the one before it.
The biggest shift in mindset is treating data annotation as a core business function, not just a box to check. If your annotation schema is ambiguous or your QA process is weak, those are not minor hiccups. They are fundamental flaws that will tank your model's performance and give you results you can't trust. Investing in your data labeling strategy is a direct investment in the accuracy of your entire AI initiative.
Elevate Your AI Strategy
The 99%+ accuracy needed for enterprise-level AI does not happen by accident. It is the direct result of a carefully planned and expertly managed annotation pipeline. That level of precision is what separates an AI that drives real business value from a very expensive science experiment.
Are you ready to build an AI that actually delivers on its promise? Prudent Partners specializes in creating the kind of high-quality, reliable datasets that power successful models. We work with data science leaders and AI/ML teams who understand that quality in, means quality out.
Let us help you design a process that delivers precision at scale. Schedule a personalized consultation with one of our experts today to walk through your project and get a pilot program off the ground. Together, we can turn your raw text into your most powerful strategic asset.
Got Questions About Text Annotation? We've Got Answers.
As you dive into the world of text annotation, a few practical questions always come up. How do you pick the right tools? What about data security? How long will this even take? Here are some straightforward answers to the most common queries we hear.
What Are The Best Tools For Text Annotation?
The honest answer? The "best" tool really depends on your project. What works for a small R&D team won't cut it for an enterprise-level deployment. The scale of your project, the complexity of your annotation tasks, and how your team collaborates are the biggest factors.
For teams just getting their feet wet or working on smaller-scale tasks, open-source tools like Doccano or Prodigy are fantastic. They give data science teams the flexibility to get started fast and build custom workflows without a huge upfront investment.
But when you're managing massive datasets, large teams, and uncompromising quality standards, you need something more robust. Enterprise projects demand serious quality control, ironclad security, and seamless team management. At Prudent Partners, we use a battle-tested combination of leading industry platforms and our own proprietary system, Prudent Prism. This hybrid approach gives our clients the best of both worlds: maximum efficiency, 99%+ accuracy, and total transparency from start to finish.
How Do You Ensure Data Privacy During Annotation?
This one is non-negotiable, especially with sensitive data from sectors like finance, healthcare, or legal. True data security is not just a single feature; it’s a framework built on multiple layers of protection. Think strict access controls, end-to-end data encryption, and operating within a certified, audited environment.
Prudent Partners is ISO 27001 certified, which is the international gold standard for information security management. This is not just a badge; it's a commitment that guarantees your data is handled within a system built for security. On top of that, all our analysts operate under strict Non-Disclosure Agreements (NDAs). We also work closely with clients to put data de-identification protocols in place, adding another layer of confidentiality.
Data privacy in text annotation isn't just a checkbox. It's the foundation of trust and compliance. Working with a certified partner gives you verifiable proof that your most sensitive assets are protected.
How Long Does A Typical Text Annotation Project Take?
Project timelines can swing pretty dramatically based on a few key variables. The sheer volume of text, the complexity of your annotation rules, the required accuracy level, and the size of the annotation team all play a huge part.
For example, a small pilot project, maybe a few thousand documents with a simple classification task, could be wrapped up in a week. On the other hand, a massive project involving millions of records and intricate relation extraction could take several months.
This is exactly why we always start with a consultation and a pilot phase. This lets us establish crystal-clear benchmarks for productivity and delivery, so you get a predictable, transparent timeline right from day one. To see how we scope out projects, check out our approach to AI quality assurance services.
What Is The Typical Cost Of Text Annotation Services?
There is no single price tag for text annotation, as the cost is tied directly to the complexity of the work, the volume of data, and your quality targets.
Here is a general idea of the range:
- Simple Tasks: Something straightforward like text classification might fall between $0.02 to $0.10 per document.
- Complex Tasks: More demanding work like advanced relation extraction or coreference resolution can run from $0.15 to $0.30 or more per record. The higher cost reflects the increased mental effort and rigorous QA needed.
At Prudent Partners, we offer transparent pricing models built around your specific project. By kicking off every engagement with a pilot, we can provide a precise, data-driven cost estimate. Our scalable teams and efficient QA workflows are designed to maximize your budget without ever sacrificing the accuracy your AI models depend on.
Ready to turn your unstructured text into a high-value asset for your AI models? The expert team at Prudent Partners is here to help you design and execute a flawless annotation strategy that delivers precision at scale. Schedule a consultation with our team today to discuss your project and get a pilot program started.