
Clinical data management (CDM) is the operational backbone of any successful clinical trial. It acts as the air traffic control tower for your research, meticulously guiding every piece of information to ensure it lands safely, accurately, and is ready for analysis. The end goal is simple but critical: to produce a high-quality, reliable, and statistically sound dataset that protects patient safety and proves a therapy’s value.
The Foundation of Trustworthy Clinical Research
At its core, CDM is the disciplined practice of ensuring that the vast amounts of data generated in a trial, from patient-reported outcomes to complex lab results, are handled with absolute precision. Without a rock-solid data management strategy, a trial's findings could be compromised. This can lead to costly delays, regulatory rejection, or, worst of all, risks to patient well-being.
This process is so much more than just data entry. It’s a comprehensive framework that governs the entire data lifecycle, from collection to final lockdown.
More Than Just Collecting Data
Effective CDM services are responsible for designing smart data collection tools, validating information the moment it comes in, and swiftly resolving any inconsistencies. It’s a proactive approach that ensures the final dataset is clean, complete, and ready for statisticians to work their magic. This builds a foundation of trust that regulatory bodies like the FDA depend on when evaluating new therapies.
The demand for these specialized services is exploding for a reason. Valued at USD 3.62 billion in 2025, the global clinical data management market is projected to hit USD 10.89 billion by 2035. This massive growth is fueled by rising R&D investments and regulators who demand nothing less than perfect data integrity. You can discover more about these market trends and their drivers.
Why Data Integrity is Non-Negotiable
Imagine building a skyscraper on a shaky foundation. No matter how brilliant the architecture, the entire structure is at risk. Clinical data is the foundation of a clinical trial, and its integrity is everything. Professional CDM services ensure this foundation is solid by implementing:
- Standardized Procedures: Creating clear, repeatable processes for data collection and handling to ensure consistency across all trial sites and participants. For instance, a standardized procedure would dictate the exact format for entering blood pressure readings (e.g., "120/80 mmHg") across all sites to prevent variations like "120 over 80".
- Rigorous Validation: Applying a mix of automated and manual checks to catch discrepancies, outliers, or missing data points long before they become bigger problems. An automated rule could flag a patient listed as 35 years old whose birth date was entered as 1958, triggering an immediate query.
- Audit Trails: Maintaining a complete, unchangeable record of all data entries and modifications, which is a non-negotiable requirement for regulatory compliance.
Ultimately, expert clinical data management services transform thousands of raw data points into a single, cohesive, and defensible dataset. This is the evidence used to determine if a new medical intervention is safe and effective, making CDM a crucial pillar of modern healthcare innovation.
To put it simply, clinical data management isn't just about managing data; it's about managing trust. Below is a breakdown of its core components.
Key Pillars of Clinical Data Management
| Component | Core Function | Impact on Trial Integrity |
|---|---|---|
| Data Collection (EDC) | Designs and deploys Electronic Data Capture systems for efficient data entry. | Ensures data is captured consistently and accurately at the source, reducing errors. |
| Data Validation/Cleaning | Implements automated and manual checks to identify and resolve discrepancies. | Guarantees the dataset is reliable, complete, and free of errors before analysis. |
| Query Management | Creates a formal process for raising, tracking, and resolving data queries with trial sites. | Ensures all data inconsistencies are formally addressed and documented for audit trails. |
| Medical Coding | Standardizes medical terms (e.g., adverse events, medications) using dictionaries like MedDRA and WHODrug. | Creates uniform data that can be aggregated and analyzed meaningfully across the study. |
| Database Lock | Finalizes the dataset, making it read-only to prevent further changes before statistical analysis. | Marks the official end of data collection and cleaning, preserving the dataset's final state for regulatory submission. |
Each pillar works together to build a dataset that is not only statistically sound but also fully compliant and ready for scrutiny by regulatory agencies. This is the bedrock upon which successful clinical trials are built.
The Core Workflow of Modern Clinical Data Management
To understand what professional clinical data management services bring to the table, you need to follow the data’s journey. It’s a highly structured path, moving from the patient all the way to the final analysis. Each step is built on the last, making sure the final dataset is accurate, complete, and ready for regulatory scrutiny. It all starts with a rock-solid foundation: smart data capture.
The first and most critical phase is setting up the Electronic Data Capture (EDC) system. Think of the EDC as the modern, intelligent replacement for the old paper binder. It’s smarter, more secure, and wildly more efficient. The EDC market is the engine of modern trials, expected to jump from USD 1.1 billion in 2025 to USD 2.5 billion by 2035. Why the explosive growth? Because it can slash data entry errors by 25-50% compared to paper, all while enforcing strict compliance with built-in audit trails. You can read the full research on EDC's impact to see these dynamics up close.
Designing Intuitive Electronic Case Report Forms
Inside the EDC system, the electronic Case Report Form (eCRF) is where the action happens. A well-designed eCRF is easy for clinical staff to use but is also engineered to stop errors before they even start. It’s not just a digital form; it’s a dynamic questionnaire with logic baked right in.
For example, imagine a cardiology trial tracking blood pressure. The eCRF would have range checks built into the blood pressure fields. If a tired clinician accidentally types a systolic reading of "300" instead of "130," the system immediately flags it as an impossible value and asks for a correction. This kind of proactive validation saves an incredible amount of time that would otherwise be spent cleaning up the data later.
The simple infographic below shows the high-level flow, from capturing the data to safeguarding it and finally getting it ready for analysis.
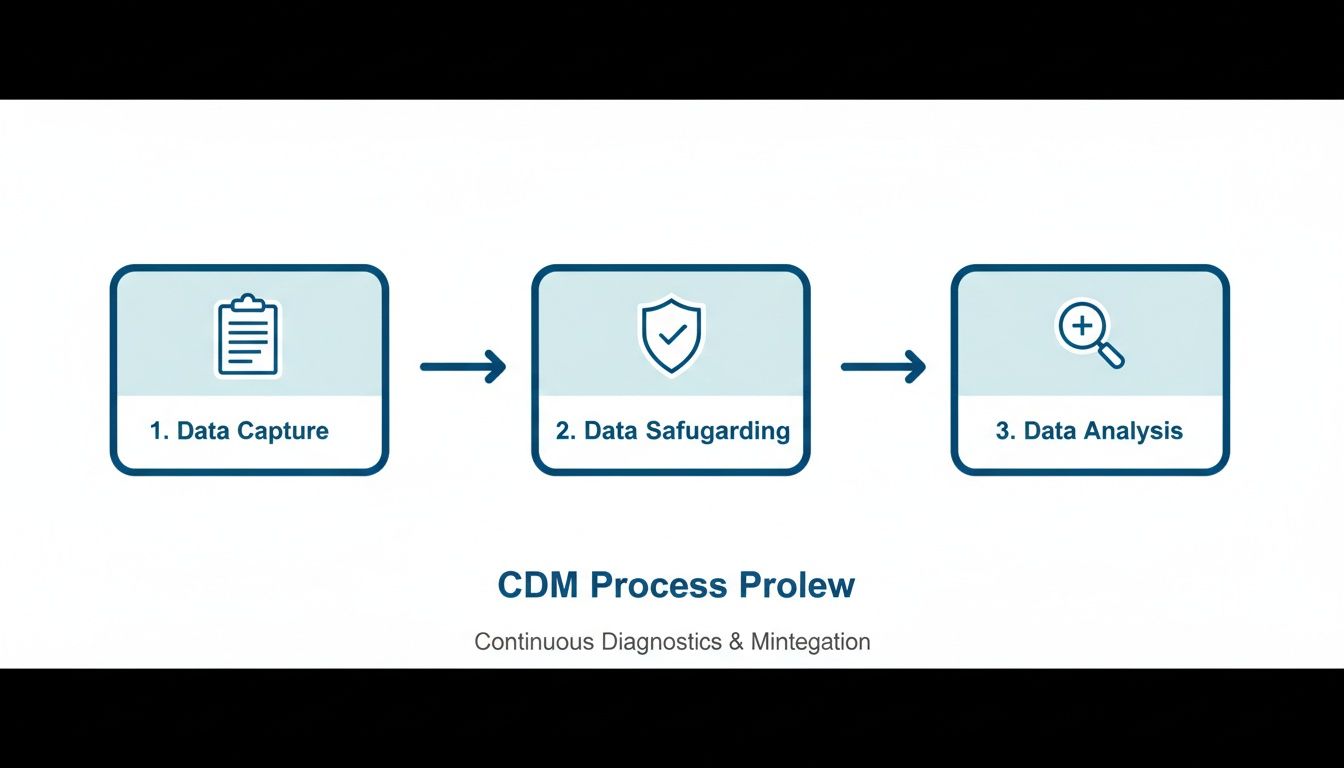
This visual drives home a key point: data management isn't a one-and-done task. It’s a continuous cycle of refinement and validation.
Meticulous Data Cleaning and Validation
As soon as data starts trickling in from clinical sites, the cleaning and validation work kicks off. This is where data managers comb through the dataset, hunting for inconsistencies, missing values, and logical errors that the automated checks might have missed. It’s a systematic and relentless process, all in the name of accuracy.
This process involves a few key activities:
- Automated Validation: Running pre-programmed checks across the entire dataset to catch obvious discrepancies. A classic example is finding a patient record marked "male" that also reports a pregnancy.
- Manual Review: Experienced data managers look over data listings to spot subtle patterns or outliers. These can often point to a systemic issue at a specific trial site that needs attention.
- Source Data Verification (SDV): This is the gold standard. It involves comparing the data typed into the eCRF against the original source documents, like patient charts or lab reports, to confirm everything matches perfectly.
This mix of technology and human expertise ensures no stone is left unturned.
A clean dataset is the direct result of a proactive and collaborative query management process. The goal is not just to find errors, but to resolve them in a way that is transparent, documented, and fully auditable.
The Query Management and Database Lock Finale
When a data manager finds a discrepancy, they raise a formal query within the EDC system. This query is sent directly to the clinical site staff responsible for that data point, creating a documented, closed-loop conversation. For instance, if a patient's date of birth doesn’t line up with their reported age, a query is sent to the site to verify the correct information. Every single step, including the question, the answer, and the change, is logged in the audit trail.
Once all the data is in, cleaned, and every last query has been resolved, we reach the final stage: the database lock. This is a huge milestone in any clinical trial. The database is switched to "read-only," which means no more changes can be made. This frozen, finalized dataset is then handed off to biostatisticians for the analysis that will ultimately determine the trial's outcome. The database lock is the official signal that the data is complete, trustworthy, and ready to support a regulatory submission.
Navigating Regulatory Compliance and Data Security
In the world of clinical trials, data integrity isn’t just a best practice; it's a legal and ethical mandate. The entire framework of clinical data management services is built on a foundation of strict regulatory compliance and rock-solid data security.
These rules aren't bureaucratic hurdles. They are essential safeguards that protect patients, ensure the data is credible, and maintain public trust in medical research.

Think of the regulatory environment as the rulebook for a high-stakes game where every single move must be documented and justified. Failing to follow these rules can lead to rejected submissions, costly delays, and serious legal consequences. That’s why partnering with a provider who deeply understands this landscape isn't just an advantage; it’s a necessity.
The Cornerstones of Clinical Data Governance
Several key regulations form the bedrock of compliant data management. Each one governs a different piece of the data lifecycle, from collection and storage to security and electronic signatures. Together, they create a comprehensive system of checks and balances.
Key regulatory standards include:
- Good Clinical Practice (GCP): This is the international ethical and scientific quality standard for designing, conducting, recording, and reporting trials involving people. GCP compliance ensures the rights, safety, and well-being of trial participants are protected.
- FDA 21 CFR Part 11: A critical regulation from the U.S. Food and Drug Administration, this sets the criteria for electronic records and signatures to be considered trustworthy and reliable. It’s the rule that makes sure every action within an EDC system is traceable and can’t be changed.
- HIPAA: The Health Insurance Portability and Accountability Act sets national standards to protect sensitive patient health information from being disclosed without the patient's consent or knowledge.
These regulations work in concert to make sure every data point is handled with the utmost care. This commitment is especially critical when dealing with complex datasets like those used in medical AI. To learn more, check out our guide on medical annotation and ensuring accuracy for U.S. healthcare AI, which dives into the intersection of data quality and regulatory demands.
Practical Impact of Regulatory Adherence
These regulations have a direct, tangible impact on daily operations. For instance, FDA 21 CFR Part 11 requires a complete audit trail for all electronic records.
This means every time a user logs in, enters data, makes a correction, or signs a record, the system creates a permanent, time-stamped entry. This unchangeable log makes data manipulation virtually impossible and gives regulators a transparent view of the data's entire history.
Likewise, adhering to GCP principles means every process, from eCRF design to query resolution, must be documented in a Data Management Plan (DMP). This document acts as a blueprint for the trial, ensuring consistency and quality across all sites and personnel.
Adherence to international standards is not just about checking boxes; it is a clear demonstration of a provider's commitment to operational excellence and risk mitigation. A certification like ISO 27001 signals that a partner has implemented a systematic approach to managing and protecting sensitive company and customer information.
Why Security Certifications Matter
Beyond government regulations, leading providers of clinical data management services often pursue independent security certifications to validate their internal controls. The most recognized of these is ISO/IEC 27001, the international standard for information security management systems (ISMS).
Achieving ISO 27001 certification proves that a provider has:
- Systematically examined its information security risks.
- Implemented a comprehensive suite of security controls.
- Adopted a management process to ensure these controls meet security needs on an ongoing basis.
For a trial sponsor, this certification provides peace of mind. It confirms that your partner has the processes and infrastructure to protect highly sensitive patient data from breaches, ensuring confidentiality and integrity at every stage. This proactive stance on security is what separates good data management from great data management.
The Strategic Case for Outsourcing Data Management
Deciding how to manage your clinical trial data is a significant strategic decision, one that goes way beyond a simple line-item budget. While the idea of an in-house team sounds good on paper, outsourcing clinical data management gives biotech and pharma innovators a powerful advantage. It frees you up to focus on your core mission: the science and the patients.
Think of it as gaining a competitive edge. You get instant access to specialized skills and scalable infrastructure, right when you need them.
The industry is already moving in this direction, and for good reason. As trials get bigger and more complex, outsourcing to Contract Research Organizations (CROs) and specialized data partners is booming. This model is expected to drive industry growth through 2035, largely because it can slash operational costs by 30-40% and cut data errors by 15-20%. Those numbers tell a pretty clear story about efficiency and quality. For a deeper dive into these market trends, you can explore this market analysis.
Immediate Access to Specialized Expertise
One of the biggest wins of outsourcing is getting a deep bench of talent on your project from day one. Building an internal data team is a long, expensive haul. You have to recruit, train, and keep specialists in EDC development, medical coding, and the ever-changing world of regulatory compliance.
An expert partner shows up with a fully-formed, seasoned team. They aren’t just good at handling data; they bring years of experience across different therapeutic areas. They’ve seen what works and what doesn't in hundreds of trials. That kind of institutional knowledge is almost impossible to build from scratch and can seriously de-risk your study.
Achieving Scalability and Operational Flexibility
Clinical trial workloads are never a straight line. They spike and dip with study phases, patient enrollment, and how many trials you’re running. If you keep a large in-house team on the payroll, you're carrying a lot of overhead during the slow times. But a team that’s too lean will get swamped, leading to burnout and costly mistakes.
Outsourcing solves this puzzle. A specialized provider can flex their resources to match exactly what your project needs. They can scale up for a massive Phase III trial, then scale back down for smaller, early-phase studies. This turns a big, fixed cost into a predictable operational expense. For companies juggling multiple data streams, understanding these efficiencies is key. You can learn more in our guide to data entry outsourcing services.
Outsourcing transforms clinical data management from a fixed operational burden into a flexible, strategic asset. It allows organizations to pay for the exact expertise and capacity they need, precisely when they need it, accelerating timelines and improving financial efficiency.
Leveraging Established Quality and Compliance Frameworks
A reputable provider of clinical data management services already lives and breathes within a battle-tested quality management system (QMS). Their standard operating procedures (SOPs), tech platforms, and security protocols have been refined over countless projects and are built to stand up to tough scrutiny from agencies like the FDA and EMA.
Trying to build and validate all of that from the ground up is a monumental task. When you partner with an expert, you inherit a mature, compliant infrastructure on day one. This dramatically cuts down your implementation time and minimizes the risk of a data-related stumble that could put your regulatory submission in jeopardy. You’re not just outsourcing tasks; you're outsourcing risk and adopting a proven blueprint for success.
In-House vs Outsourced Clinical Data Management: A Comparison
Making the choice between building an in-house team and partnering with an external specialist is a critical decision point for any life sciences company. To make it clearer, let's break down the key differences across several important factors.
| Factor | In-House Management | Outsourced Services |
|---|---|---|
| Cost Structure | High fixed costs (salaries, benefits, training, software licenses). Significant capital expenditure. | Variable, operational costs based on project needs. Predictable and scalable pricing. |
| Expertise & Talent | Limited to the skills of hired employees. Difficult and expensive to recruit specialists. | Immediate access to a deep pool of experienced specialists across multiple domains. |
| Scalability | Inflexible. Difficult to scale team up or down with project demands, leading to overstaffing or burnout. | Highly flexible. Resources are allocated dynamically to match trial phases and workload. |
| Speed to Start | Slow. Requires lengthy hiring, onboarding, and system validation processes. | Fast. Partners are ready to start immediately with established teams and validated systems. |
| Compliance Risk | The entire burden of building and maintaining compliant systems (FDA 21 CFR Part 11, GCP) rests internally. | Reduced risk. Partners operate under pre-validated, regularly audited quality and compliance frameworks. |
| Technology | Requires significant investment in purchasing, validating, and maintaining EDC and other software. | Access to best-in-class, validated technology without direct ownership costs. |
| Core Focus | Diverts internal resources from core scientific research and development activities. | Allows the internal team to focus entirely on science, strategy, and patient outcomes. |
Ultimately, the right path depends on your organization's scale, pipeline, and long-term strategy. However, for most small to mid-sized biotech and pharmaceutical companies, outsourcing offers a more agile, cost-effective, and lower-risk model for achieving high-quality clinical data.
Integrating AI and Data Annotation into Clinical Workflows
The world of clinical data management is changing. For years, the goal was simple: collect clean, compliant data for statistical analysis. But today, that's just the starting point. The real value lies in preparing that data for machine learning and advanced analytics, turning static datasets into dynamic fuel for medical breakthroughs.
This is where Artificial Intelligence (AI) and high-accuracy data annotation become essential parts of modern clinical data management services. Instead of just managing data, today's best providers are transforming it for the next generation of healthcare AI. This shift makes CDM the critical first step in any successful AI initiative.
This evolution is driven by AI's incredible ability to spot patterns and predict outcomes that are invisible to the human eye. But here's the catch: every powerful AI model is built on impeccably labeled data. Without it, the model is useless.
The Role of High-Accuracy Data Annotation
AI algorithms learn from examples, much like a medical student. You have to show them thousands of labeled images, reports, or data points before they can reliably identify specific features on their own. The quality of these labels is everything. Inconsistent or inaccurate annotation leads directly to a flawed, unreliable AI.
This is why expert annotation services are so critical. Think about these real-world scenarios:
- Medical Image Labeling: In an oncology trial, human experts can meticulously outline tumors on thousands of CT scans. This labeled dataset trains an AI model to detect early-stage malignancies with superhuman speed and accuracy, helping radiologists make faster, more confident diagnoses.
- Text Annotation for Unstructured Data: So much valuable information is buried in clinical notes, patient histories, and adverse event reports. Annotation brings structure to this chaos by identifying and labeling key terms like symptoms, diagnoses, and medications, making it all analyzable at scale.
This process is what turns raw data into intelligent, machine-readable assets. You can get a deeper look at the meticulous work involved in our overview of professional data annotation services.
Validating AI Outputs with Generative AI Quality Assurance
With Generative AI now entering the healthcare field, a new challenge has appeared: how do we trust its outputs? For instance, a large language model could be used to generate summaries of complex patient records, helping a clinician quickly get up to speed. It’s efficient, but that summary must be 100% accurate to be safe and clinically useful.
This is where Generative AI Quality Assurance (QA) comes in. It’s a human-in-the-loop process where medical experts review and validate AI-generated content against the original source documents, ensuring nothing is lost or misinterpreted.
A modern clinical data management partner does more than just collect data; they prepare it for the future. By integrating data annotation and AI quality assurance, they build a bridge between clinical research and machine learning, ensuring that every data point contributes to smarter, faster medical innovation.
Building a Data Foundation for the Future
When you integrate AI workflows into your data management strategy, it stops being a simple procedural task and becomes a powerful strategic asset. It creates a single, cohesive data pipeline that serves both your clinical research and machine learning teams.
The key benefits are clear:
- Enriched Datasets: Annotation adds valuable layers of context to clinical data, opening up entirely new possibilities for research and analysis.
- Accelerated R&D: AI models trained on high-quality data can automate tedious work like image analysis or data extraction, drastically shortening research timelines.
- Future-Proofing Data: The data you collect today is structured and labeled for the AI applications of tomorrow, maximizing its value for years to come.
- Improved Reliability: Putting rigorous QA processes in place for AI outputs ensures that new technologies can be deployed safely and effectively in clinical environments.
Ultimately, this integration completely transforms the role of a CDM provider. They are no longer just guardians of your trial data; they become essential partners who prepare that data to power the next wave of AI-driven discoveries in healthcare.
How to Choose the Right Data Management Partner
Picking a provider for your clinical data management services is one of the most important calls you’ll make for your trial. The right partner isn’t just a vendor; they become an extension of your team, protecting your data and helping you hit your deadlines. The wrong one can introduce risks, delays, and mistakes that cost more than just money.
Making a smart choice means looking at a potential partner’s skills, history, and processes with a critical eye. This is about way more than a price tag; it’s about finding a team whose obsession with quality matches your own.
Evaluating Core Competencies and Experience
First, dig into their track record. You’re looking for deep experience in your specific therapeutic area. Why? Because that kind of specialized knowledge is invaluable when it comes to understanding the tricky data and potential traps unique to your field. Don’t be shy; ask for case studies or references from trials similar to yours.
Next, get serious about their quality and security credentials. A real commitment to excellence isn’t just talk; it’s backed by certifications.
- Regulatory Compliance: Check their history with bodies like the FDA and EMA. They should have a solid list of successful submissions under their belt.
- Security Standards: An ISO/IEC 27001 certification is non-negotiable. It’s the clearest sign they have a mature system for managing information security.
- Quality Management: Also look for an ISO 9001 certification. This tells you they stick to internationally recognized principles for quality management.
These aren’t just badges. They show a provider is proactive about minimizing risk and keeping your highly sensitive data safe.
Assessing Technology and Scalability
A partner’s tech stack is just as critical as their people. Ask them about the EDC systems they work with and how flexible they are with different platforms. In a world of wearables and ePROs, their ability to pull in and manage data from all kinds of sources is key to a smooth operation.
Scalability is the other side of that coin. What happens if you suddenly need to add more trial sites or see a surge in patient enrollment? Can they handle it without quality taking a nosedive? Their operating model needs to be flexible enough to grow with your project, giving you the same solid support whether you’re running a small Phase I study or a massive global Phase III trial.
The real test of any partnership is seeing it work in the wild. A pilot project is the best way to get a feel for a provider’s workflow, communication style, and quality before you sign on for the long haul. That trial run can tell you more than any slide deck ever will.
At the end of the day, a partnership is built on trust and straight talk. The best providers are transparent, giving you a clear window into their processes and how they’re performing.
At Prudent Partners, we focus on building solutions that guarantee data integrity and help drive clinical success. We mix proven quality assurance protocols with a scalable infrastructure to deliver reliable, submission-ready data every time.
Ready to build a data solution that secures your trial’s success? Connect with our experts for a tailored consultation.
Frequently Asked Questions
Jumping into clinical data management can feel complex, so we've answered a few of the most common questions we hear. This should help clear things up as you plan your next clinical trial.
What Is the Primary Goal of Clinical Data Management Services?
At its core, the main goal is to make sure the data you collect in a clinical trial is complete, accurate, and totally reliable. Think of it as building a rock-solid foundation for your study's conclusions.
This involves everything from designing the database and validating data as it comes in to resolving inconsistencies. The final deliverable is a clean, locked dataset that’s ready for statisticians to analyze. Ultimately, it’s about protecting patient safety, meeting regulatory demands, and proving a new therapy works on data that can withstand intense scrutiny.
How Does Good Data Management Impact FDA or EMA Approval?
Regulatory bodies like the FDA and EMA are sticklers for data quality, and for good reason. They need to see pristine, consistent data to even consider approving a new drug or device. Good CDM practices create a transparent, auditable trail that proves your data's integrity from day one.
Sloppy data management, on the other hand, can have serious consequences. This can result in outright study rejection, demands for more data, or long delays in the approval process. Those setbacks don't just cost millions; they postpone patient access to treatments that could change their lives.
What Are the First Steps to Outsourcing Clinical Data Management?
First, you need a clear picture of your trial's scope, data requirements, and which regulations apply. Once you have that locked down, you can start looking for the right partner. Focus on their direct experience in your therapeutic area, their compliance certifications (ISO 27001 is a big one), and how they handle quality assurance.
Our advice? Always start with a detailed consultation to walk through your project. After that, a small pilot program is a fantastic way to test a provider’s workflow, communication style, and quality before you sign on for a full-scale partnership.
How Does AI Enhance Traditional Clinical Data Management?
This is where things get really interesting. AI and data annotation take traditional CDM to the next level by pulling valuable insights from unstructured data, like doctor's notes or medical images. For instance, an expert can annotate features in an MRI scan, which then trains an AI model to spot signs of disease automatically.
This turns data management from a simple collection task into a powerful data enrichment engine. It not only makes operations more efficient but also pushes research forward by enabling predictive analytics that just weren't possible to do at scale before.
Ready to make sure your clinical data is accurate, compliant, and built for the future? The experts at Prudent Partners combine rigorous quality assurance with scalable solutions to deliver submission-ready data you can trust. Connect with us today to discuss your project and build a data strategy for success.