
Computer vision is the technology that grants a robot the power of sight. It enables a machine to process, interpret, and understand the visual world through a camera, much as humans do with their eyes. This capability is the crucial distinction between a simple, pre-programmed robotic arm and an intelligent system that can genuinely perceive its environment, identify objects, and make informed decisions in real time.
Giving Robots the Power of Sight
Consider a modern manufacturing facility. A robotic arm is no longer just mindlessly placing parts. With computer vision, it can inspect those same parts for microscopic defects invisible to the human eye. In a bustling warehouse, autonomous carts deftly navigate around misplaced pallets and people without human guidance. This is not science fiction; it is the current reality of embedding computer vision into robotic systems.
For business leaders, this marks a significant leap from basic automation to genuine operational intelligence. A robot with vision can adapt to new products on the assembly line, handle unexpected changes in its workspace, and perform tasks that demand a level of judgment previously exclusive to humans.
The Business Impact of Robotic Vision
This shift is driven by measurable business results. The global market for robotic vision is projected to grow from USD 3.29 billion in 2025 to USD 4.99 billion by 2030. This incredible expansion is a direct result of advancements in AI and more powerful sensors that provide robots with near-human perception. You can discover more about this market expansion on MarketsandMarkets.com.
The key benefits are clear and quantifiable:
- Enhanced Quality Control: Robots can spot flaws, confirm correct assembly, and maintain product consistency with superhuman accuracy, 24/7, without fatigue.
- Increased Throughput: Vision-guided robots operate faster and more precisely, accelerating processes from sorting packages to performing intricate manufacturing steps.
- Greater Flexibility: Unlike traditional automation, vision systems allow robots to switch between different products or adapt to new workflows with minimal reprogramming.
At its core, computer vision in robotics is about converting visual data into intelligent, actionable outcomes. Whether a camera is identifying a part or LiDAR is mapping a room, the objective remains the same: provide the robot with the situational awareness it needs to perform its job safely and effectively.
However, a robot's vision is only as reliable as the data it was trained on. Just as a person learns from experience, an AI model learns from thousands of meticulously labeled images and sensor readings. This foundation of high-quality, accurately annotated data is the single most important factor in building a dependable robotic vision system.
Without it, even the most advanced hardware will fail to perform. This is where expert partners in data annotation services become essential to achieving success.
Understanding How Robots See the World
To understand how computer vision drives business value, it is helpful to examine how a robot interprets what its cameras see. The process is not a single event but a combination of sophisticated tasks working in concert to turn raw pixels into intelligent, physical actions.
Each task provides the robot with another layer of understanding, much like how humans combine sight, context, and experience to navigate the world.
This flowchart provides a high-level overview of the journey from perception to action.
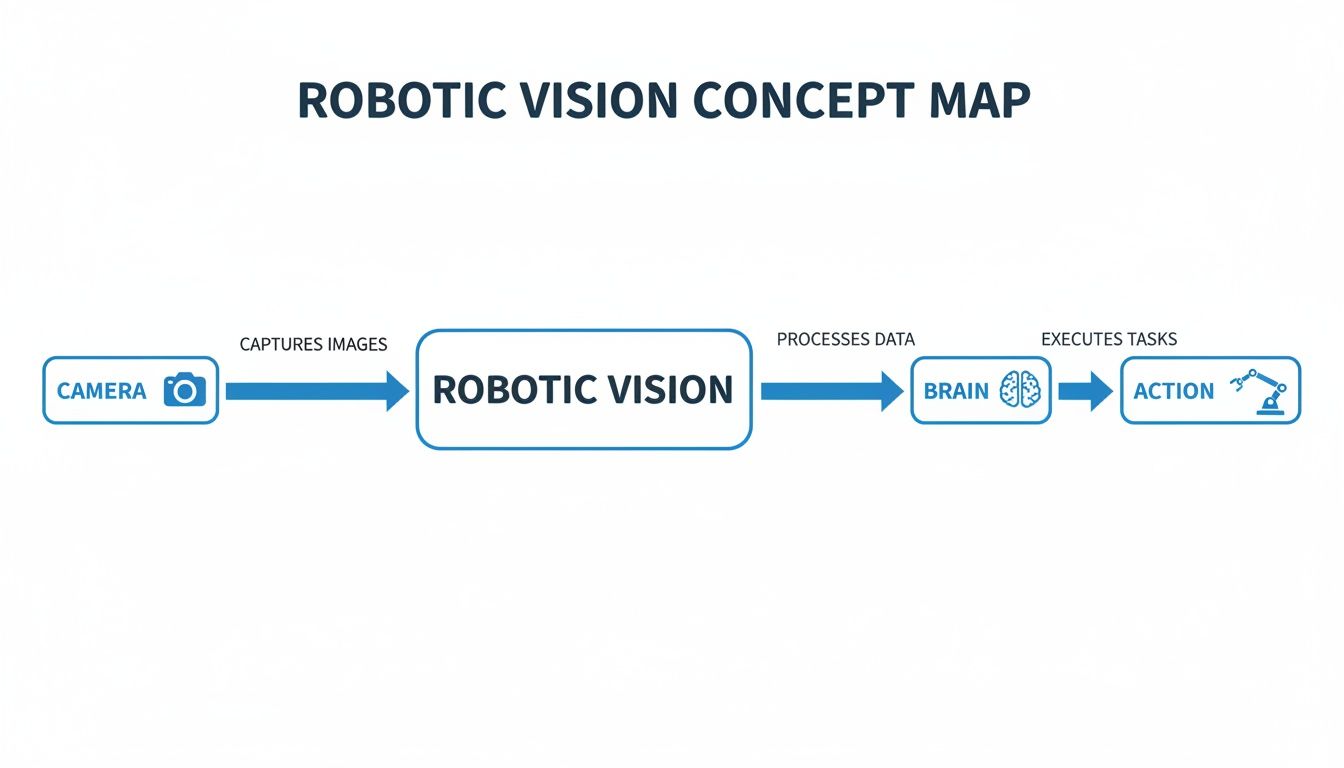
As illustrated, the camera captures visual data, the AI "brain" processes it, and the robot's actuator performs a task based on that interpretation. Let's explore the core vision tasks occurring within that "brain."
Object Detection: What and Where
The most fundamental task is object detection. This is how a robot answers two basic questions: "What is in front of me?" and "Where is it?" It does not just see a blur of pixels; it draws a precise bounding box around an item and classifies it.
For example, a robot on a fast-moving production line uses object detection to identify a specific car part among dozens of others. The business value here is immediate. The robot can select the correct component with 99%+ accuracy, ensuring the assembly is correct the first time and significantly reducing costly rework.
Semantic Segmentation: Mapping the Entire Scene
While object detection identifies individual items, semantic segmentation provides the robot with a complete, contextual map of its environment. It does not just find objects; it classifies every single pixel in an image, assigning labels like "floor," "conveyor belt," "human," or "hazardous area."
This capability is crucial for safety and navigation. An autonomous mobile robot (AMR) in a warehouse uses segmentation to differentiate between a safe, drivable floor and a restricted zone where people are working. It gains a comprehensive understanding of the entire scene. You can gain a deeper understanding of how this pixel-perfect classification works with semantic image segmentation.
The real power of computer vision in robotics emerges when these tasks are combined. A robot detects an object, understands its context through segmentation, and then uses that combined knowledge to decide its next move. This layered understanding is what enables complex, autonomous behavior.
Pose Estimation: Precision in Three Dimensions
Once a robot identifies an object, it often needs to interact with it. This is where pose estimation is applied. This critical task calculates an object's precise orientation and position in 3D space. It tells a robotic arm not just where an item is, but its exact angle, tilt, and rotation.
Consider a "pick-and-place" robot in a logistics center tasked with retrieving a product from a bin of jumbled items. Pose estimation allows the robotic gripper to calculate the perfect approach angle to pick up the item securely without dropping it or disturbing other objects. This directly boosts fulfillment speed and accuracy.
SLAM: Mapping and Moving on the Fly
For any mobile robot, knowing its location and mapping its surroundings is non-negotiable. Simultaneous Localization and Mapping (SLAM) is the technology that allows a robot to build a map of an unknown environment while simultaneously tracking its own position within that map.
An autonomous forklift in a busy distribution center uses SLAM to navigate crowded aisles it has never seen before. It constantly updates its internal map to account for new obstacles like pallets or people, ensuring it always has a clear, collision-free path. This ability to adapt to dynamic environments is what makes mobile robotics truly effective, leading to a more efficient and scalable logistics operation.
The Technology That Powers Robotic Vision
To fully appreciate the capabilities of computer vision in robotics, it is necessary to examine the underlying technology. Similar to human sight, which requires both eyes to see and a brain to interpret, a robot relies on a combination of sophisticated sensors to capture data and powerful AI models to process it. The true innovation occurs when these two components work together seamlessly, transforming a simple machine into an intelligent partner.
The process begins with a sensor. These are the "eyes" of the robot, and selecting the right one is fundamental to the task at hand. The optimal sensor depends on the application, the environment, and the level of detail required for the robot to operate safely and accurately.

Choosing the Right Sensors for the Job
Not all robotic "eyes" are created equal. Each type of sensor provides different kinds of information and comes with its own set of trade-offs.
To clarify the options, here is a comparison of the most common sensors used in robotics today.
Comparison of Robotic Vision Sensors
| Sensor Type | Key Strengths | Limitations | Common Applications |
|---|---|---|---|
| 2D Cameras | Cost-effective and excellent for capturing rich color and texture detail. | Lacks depth perception, sensitive to lighting changes. | Quality inspection, barcode reading, object identification. |
| 3D Depth Sensors | Provides depth information, allowing for 3D object recognition and spatial awareness. | Lower resolution than 2D cameras, can struggle with reflective surfaces. | Bin picking, pose estimation, obstacle avoidance. |
| LiDAR | Highly accurate at measuring distances and creating detailed 3D maps of large areas. | Expensive, lower resolution than cameras, struggles with transparent objects. | Autonomous navigation (AMRs), environmental mapping. |
As shown, selecting the right hardware is a critical first step. A simple 2D camera might be perfect for a robot sorting colored parts on a well-lit conveyor belt. However, for a mobile robot navigating a dynamic warehouse, a combination of LiDAR for mapping and 3D sensors for close-range obstacle avoidance would be more appropriate. It is about matching the tool to the task.
The AI Brain Processing the Visual Data
Once the sensors capture the raw visual data, the "brain" of the system takes over. This is where AI, specifically deep learning models, comes into play. The primary model for computer vision in robotics is the Convolutional Neural Network (CNN).
A CNN can be understood as a series of digital filters that learn to recognize patterns, one layer at a time.
- Input: The process begins with an image or video frame from the sensor.
- Pattern Recognition: The initial layers of the network identify simple features like edges, corners, and colors.
- Complex Assembly: Deeper layers combine these simple features into more complex patterns, such as the shape of a screw, the texture of a box, or the outline of a person.
- Actionable Output: Finally, the network provides a decision, such as "this is a defective part" or "the object is located at these coordinates."
These models are incredibly powerful but must be trained on massive datasets of carefully labeled images or sensor data. You can learn more about the different algorithms for image recognition that form the backbone of these systems here.
A robot's ability to see and understand its environment is a direct reflection of the quality and precision of its training data. The most advanced sensors and AI models are ineffective without a foundation of expertly annotated data to teach them what to see. This human-centered process is what powers robotic intelligence.
The Critical Role of Data Annotation in Robotics
While advanced sensors and intelligent AI models are crucial, they are only half of the equation. The single most important factor determining the success of a computer vision in robotics project is the quality of its training data. The principle of "garbage in, garbage out" is not a cliché in this context; it is a fundamental engineering reality.
Accurately annotated data is the fuel that powers an intelligent robot. Without it, even a multi-million-dollar machine is effectively blind, unable to make sense of the visual world. Preparing this fuel involves a meticulous process that transforms raw, unstructured pixels into a structured language an AI can understand.
From Raw Pixels to Actionable Intelligence
The journey begins with collecting relevant data: thousands of images or video frames that accurately represent the variable and unpredictable conditions the robot will encounter in the real world. However, this raw footage is useless to an AI on its own. It requires context.
That context is provided by data annotation, a process where human experts carefully label every object of interest in every single frame.
This task requires different levels of precision for different applications:
- Bounding Boxes: For basic object detection, annotators draw a simple rectangle around an item. This tells the model, "This cluster of pixels is a product on a shelf."
- Polygons: When a robot needs to know the exact shape of an object to grasp it correctly, annotators trace its precise outline, pixel by pixel.
- Semantic Segmentation: This is the most detailed level. Every pixel in an image is labeled, creating a complete map of the scene that distinguishes "floor" from "walkway" from "dangerous machinery."
The purpose of data annotation is to create the "ground truth": a flawless, human-verified dataset that serves as the textbook from which the AI model learns. The closer this ground truth is to reality, the more reliable and predictable the robot will be.
This is a demanding, detail-oriented job. The real world is full of challenging situations like partially occluded objects, variable lighting, and camera glare that can confuse an AI. That is why skilled annotators and a robust quality assurance (QA) process are absolute necessities for building a trustworthy system. A detailed overview of our specialized data annotation services demonstrates how this precision is achieved at scale.
Ensuring Accuracy and Scalability in Data Labeling
As robotic systems become more complex, the demand for pristine training data grows. The market for vision-guided robots (VGRs), which are entirely dependent on this technology, is expected to expand from USD 15,964.2 million in 2025 to USD 34,623.6 million by 2035. A significant 57.6% of this market in 2025 will be 3D vision robots, which require incredibly precise spatial data to handle complex tasks like assembly and sorting. You can read the full research about these market trends on Future Market Insights.
Meeting this demand requires a data annotation process built for both quality and scale. A multi-layer QA workflow is non-negotiable. This typically involves a senior annotator reviewing the initial team's work, supported by automated checks that identify common errors. It is this combination of human expertise and automated validation that ensures the final dataset is as close to perfect as possible.
This painstaking preparation is what differentiates a proof-of-concept robot in a lab from a dependable asset on the factory floor. Investing in high-quality data annotation and rigorous QA upfront is the most effective way to de-risk a robotics project, avoid costly failures, and ensure your robot performs with the accuracy and consistency your business requires.
Robotic Vision Applications Across Industries
The concepts of object detection, segmentation, and SLAM translate into tangible business advantages when applied to real-world challenges. Across various sectors, robots with advanced vision are not just improving existing processes; they are creating entirely new operational models. The return on investment is clear: greater accuracy, speed, and safety.

The market impact is undeniable. The global robotics market is expected to grow from US$50 billion in 2025 to US$111 billion by 2030, at a 14% CAGR. Mobile robots, which rely heavily on computer vision for navigation, are a massive component of this growth. They are projected to account for US$30 billion in 2025 sales and soar to US$75 billion by 2030. You can explore more of these trends in the global robotics market outlook from ABI Research.
Manufacturing and Quality Control
In manufacturing, precision is paramount. Vision-guided robotic arms are now standard on automotive assembly lines, handling tasks that demand superhuman consistency. Using high-resolution cameras and precise pose estimation models, these robots place components with sub-millimeter accuracy, guaranteeing a perfect fit every time.
Beyond assembly, computer vision is a game-changer for quality control. A robotic arm can scan a finished product, using object detection and segmentation to identify microscopic cracks, misaligned labels, or color imperfections that a human inspector might miss at the end of a long shift. This directly translates to lower defect rates and fewer costly product recalls.
Logistics and Warehouse Automation
Warehouses are inherently dynamic environments. This is where autonomous mobile robots (AMRs) excel, using a combination of LiDAR and 3D cameras to move through crowded aisles, avoid obstacles, and transport goods. SLAM algorithms enable them to build and update maps in real time, adapting to ever-changing layouts without manual intervention.
Computer vision also enhances the sorting process. High-speed cameras mounted over conveyor belts identify barcodes, package dimensions, and destination labels instantly. This visual data directs robotic arms or diverters on where to send each package, sorting thousands of items per hour with near-perfect accuracy. This level of automation is essential for meeting the demands of modern e-commerce.
The true value of robotic vision is its ability to bring structure to unstructured environments. A warehouse is inherently chaotic, but a robot with sight can perceive that chaos, understand it, and navigate it safely and efficiently, turning a complex space into a predictable, optimized workflow.
Healthcare and Surgical Assistance
In medicine, precision and stability can be critical. Computer vision systems now guide robotic arms during highly delicate surgeries. These systems can overlay 3D models of organs onto a surgeon’s view, track instruments with pinpoint accuracy, and even compensate for a surgeon's natural hand tremors.
This application combines the core vision tasks discussed. Semantic segmentation helps the robot differentiate between healthy tissue and a tumor. Pose estimation tracks the exact orientation of surgical tools. The result is less invasive procedures, lower patient risk, and often, faster recovery times.
Agriculture and Environmental Monitoring
Agriculture is also undergoing a high-tech transformation. Drones equipped with multispectral cameras fly over vast fields, gathering data on crop health. Onboard vision models analyze this imagery to detect early signs of disease, identify areas needing irrigation, or estimate harvest yields.
This data-driven approach is known as precision agriculture, where resources like water and fertilizer are applied only where needed. On the ground, vision-guided robots can automate tasks like weed removal or harvesting delicate produce such as strawberries, which require a gentle touch and an eye for ripeness. This is not just about efficiency; it is about building more sustainable farming practices.
Your Blueprint for a Successful Robotics Vision Project
From core vision tasks like object detection and SLAM to hardware choices and industry applications, the path from a simple camera to a robot making intelligent, real-world decisions is complex. However, one central truth connects every element: an AI is only as good as the data it is trained on.
While the models and robotic hardware receive most of the attention, their success depends entirely on data quality. This is not just a technical requirement; it is the foundation of a reliable, scalable, and safe robotics system. Without meticulously annotated datasets and a rigorous QA process, even the most advanced computer vision in robotics project is prone to failure, leading to unpredictable behavior and costly mistakes.
Turning Data Into Your Strategic Advantage
To succeed, data must be treated as a core asset. This means partnering with an expert who understands the nuances of data annotation and AI quality assurance, ensuring your robot learns from a flawless digital representation of its environment. The true differentiator between a lab prototype and a production-ready robot lies in the final-mile execution on data.
The ultimate goal is to build robotic systems you can trust. That trust is not born from complex algorithms alone. It is built on the painstaking human effort of creating perfect ground-truth data to guide the AI’s learning.
This is not a journey to undertake alone. Engaging experts de-risks your investment and accelerates your path to meaningful automation. The right partner provides the people, processes, and platforms necessary to deliver AI training data that meets the highest standards of accuracy and consistency.
Ready to build smarter, more reliable robotic systems? The experts at Prudent Partners are here to help. Let’s discuss your specific automation challenges and explore how our deep expertise in data annotation and AI quality assurance can accelerate your success.
Connect with Prudent Partners today to schedule a consultation and begin your journey toward intelligent automation.
Common Questions About Computer Vision in Robotics
Implementing computer vision in robotics raises numerous questions about strategy, data, and real-world system performance. Obtaining clear answers to these common queries is essential for moving from a proof of concept to a reliable, production-ready system.
Let's address some of the most frequent discussion points.
What’s the Biggest Challenge in Deploying Robotic Vision?
The primary challenge is rarely the algorithm itself. The real hurdle is the data.
The single greatest challenge is ensuring your training data truly represents the full spectrum of variability the robot will encounter in its daily operations. This involves much more than simply taking a few pictures.
It means capturing everything from shifting light conditions in a warehouse to partially occluded products on a shelf and unexpected reflections from a wet floor. A model trained on clean, perfect, laboratory-style data will fail when it encounters the messy reality of a factory or stockroom. Robust performance is built on a dataset that anticipates chaos.
How Much Training Data Does a Robotic Vision Model Need?
There is no magic number, and focusing on quantity is a common mistake. The focus should always be on data quality and diversity over sheer volume.
A thoughtfully curated dataset of 10,000 images covering a wide range of scenarios, edge cases, and environmental conditions will always produce a better model than a million repetitive images of the same object. The goal is not for the AI to memorize a few perfect examples; it is to teach it how to generalize and make intelligent decisions in unexpected situations.
The most effective strategy is iterative. Start with a solid, diverse dataset. Train the initial model. Then, test it relentlessly to identify its breaking points. Once these weaknesses are identified, strategically collect and annotate new data that directly addresses those failure points.
Can Computer Vision Work in Harsh Industrial Environments?
Absolutely. Achieving reliable vision system performance in a dusty factory, a dimly lit warehouse, or an outdoor farm is entirely possible with the right strategy. Success depends on a smart combination of specialized hardware and intelligent data practices.
Here’s how this is typically addressed:
- Specialized Hardware: A standard camera will not suffice in poor visibility. Systems can be outfitted with infrared or thermal cameras that see clearly in low light. For environments with significant dust or glare, 3D sensors and LiDAR are often better choices as they are less affected by atmospheric conditions.
- Data Augmentation: We can also teach the AI to handle these challenging conditions before deployment. During training, data augmentation is used to programmatically simulate harsh environments. We can add digital "noise" to images, alter brightness levels, or even simulate dust particles, effectively training the model to perform reliably under various conditions.
At Prudent Partners, we help you turn your data into a real strategic advantage. Our expertise in high-accuracy data annotation and AI quality assurance gives your robotic vision systems the rock-solid foundation they need to perform with the accuracy and dependability your operations demand.
Start your journey to intelligent automation by connecting with our experts today.