
Data curation is the strategic, ongoing process of transforming raw, chaotic information into a structured, reliable asset ready for machine learning. It is more than just tidying up datasets. It is a continuous cycle of collecting, cleaning, enriching, and governing data to ensure it is accurate, relevant, and perfectly suited for its purpose.
In short, it is the non-negotiable foundation for building high-performing and trustworthy AI.
What Data Curation Really Means for AI
Let's move beyond textbook definitions for a moment. Imagine a master librarian building a specialized collection for a world-class research institution. They do not just accept any book that comes through the door. Instead, they meticulously select, categorize, repair, and organize each volume to create a coherent, valuable, and trustworthy resource.
That is precisely what data curation does for artificial intelligence. It is a deeply human-centered activity that injects intelligence and context into otherwise raw information.
This is not a one-time task. It is a continuous cycle that maintains the health and relevance of a dataset over its entire lifecycle. The goal is to create a "golden dataset": one that is not only clean but also rich with context, making it a dependable source for training and validating complex models.
The Strategic Value of Curated Data
High-quality data is the single most important ingredient for AI success. Curation directly shapes that quality, ensuring the information fed into a model is:
- Accurate: Free from the errors, inconsistencies, and noise that can mislead an algorithm.
- Relevant: Directly aligned with the specific problem the AI model is being built to solve.
- Complete: Contains all the necessary information and features, with missing values handled thoughtfully.
- Governed: Managed under clear policies for privacy, security, and compliance.
This meticulous preparation is why expert data annotation services are a cornerstone of effective curation. The importance of this field is impossible to ignore. A report by Future Market Insights projects that the global content curation software market, closely linked to these practices, will grow from USD 780.4 million in 2025 to USD 2,489.4 million by 2035. This massive expansion is driven by the unstoppable demand for quality data.
The Core Stages of the Data Curation Lifecycle
Data curation is not a single action, but a structured journey that transforms raw, messy information into a polished, strategic asset ready to power your AI. This lifecycle has distinct stages, and each one builds on the last to systematically add value and ensure the final dataset is accurate, relevant, and trustworthy.
The work begins long before you touch a single data point and continues well after a model goes live. Let's walk through the five core stages that make up this essential workflow.
This infographic provides a high-level view of that transformation, showing how chaotic raw data becomes a valuable, AI-ready asset through a structured curation process.
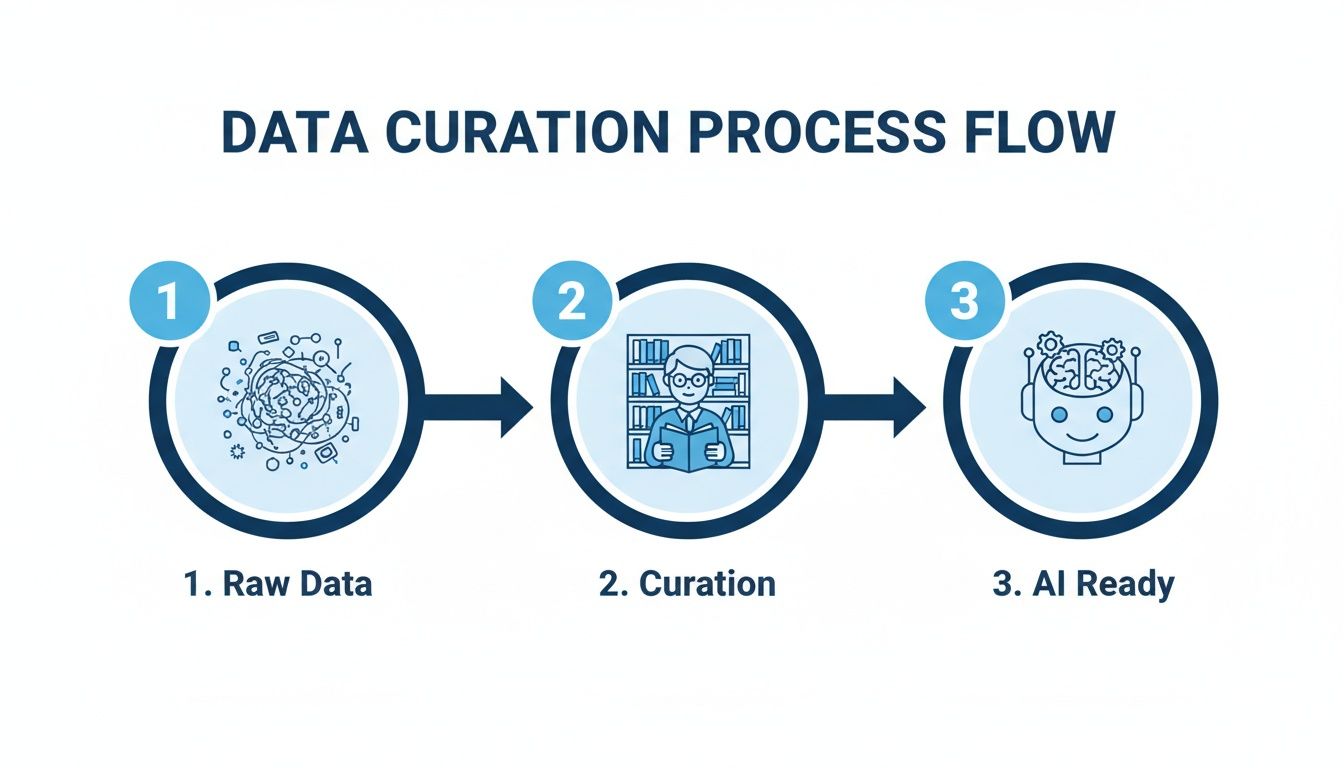
As you can see, curation is the critical bridge between raw potential and intelligent application.
Data Collection and Sourcing
The lifecycle kicks off with identifying and gathering the right data. This first step is more strategic than it sounds; you must define the problem you want to solve and determine the exact information you need. Success here is not just about collecting a lot of data; it is about collecting the right data for your model’s objective.
Getting this wrong can bake in systemic biases from the start. For example, if you build a hiring algorithm with a dataset that predominantly includes profiles from a single demographic, the model will likely produce biased results no matter how well you clean it later. To dig deeper into this foundational step, explore our detailed guide on the fundamentals of data sourcing strategies.
Data Cleaning and Preprocessing
Once gathered, raw data is almost always messy. This stage is about tackling the inconsistencies, errors, and missing values that could completely derail an AI model.
Effective data cleaning is the first line of defense against the "garbage in, garbage out" problem. It ensures that subsequent, more resource-intensive stages are applied to a foundation of clean, reliable information.
Common cleaning tasks include:
- Removing Duplicates: Eliminating redundant entries that can skew model training.
- Correcting Errors: Fixing typos, inconsistent formatting, or incorrect entries.
- Handling Missing Values: Strategically filling in blanks or removing records with incomplete information.
Data Annotation and Enrichment
This is where raw data begins to gain real meaning for an AI. Data annotation is the process of applying labels or tags to data, which teaches the AI what to look for. For example, in medical imaging, annotators might meticulously outline tumors in CT scans, providing the "ground truth" for a diagnostic AI to learn from.
Enrichment takes this a step further by adding external context to make the data even more valuable. A customer dataset, for instance, could be enriched with publicly available demographic data to build more powerful predictive models for a marketing campaign.
Data Validation and Quality Assurance
Before any dataset can be used to train a model, it must be rigorously validated. This critical stage involves systematic checks to ensure the data meets predefined quality standards; we often target 99%+ accuracy. At Prudent Partners, this involves a multi-layer QA process where senior analysts review the work of primary annotators to catch subtle errors and guarantee consistency with project guidelines.
Data Governance and Maintenance
Curation is not a one-time project; it is an ongoing commitment. This final stage is about establishing clear policies for data access, usage, privacy, and security. It also includes creating a plan for maintaining and updating the dataset over time. This prevents model drift and ensures the data remains relevant as new information becomes available. Strong governance turns your data into a secure, compliant, and enduring asset.
Curation vs. Cleaning vs. Management: Understanding the Difference
In the world of data, it is easy to get tangled in terms that sound alike but mean different things. The lines between data curation, data cleaning, and data management often get blurred, which can lead teams down the wrong path and waste valuable resources. Clarifying these concepts is the first step to building an AI pipeline that actually works.
Let’s start with a simple analogy. Think of your data assets as a world-class research library.
- Data Management is the entire library building: the architecture, security systems, and shelving that keep everything safe and organized.
- Data Cleaning is like a librarian spotting a torn page in a single book and carefully taping it back together.
- Data Curation is the expert librarian’s ongoing mission: thoughtfully selecting which books to acquire, organizing them into insightful collections, and adding notes in the margins to make them priceless for future researchers.
What Is Data Management?
Of the three, data management is the broadest concept. It is the high-level framework your organization uses to collect, store, protect, and process data assets across their entire lifecycle. It is the operational backbone that keeps your data available, secure, and compliant.
Key activities under the data management umbrella include:
- Setting up databases and data warehouses.
- Implementing robust security protocols to guard sensitive information.
- Establishing data governance policies for access and compliance.
- Managing data backup and disaster recovery plans.
Essentially, management is about creating a stable, secure home for your data to live in. While absolutely critical, it does not inherently improve the quality or contextual richness of the data itself.
The Specific Role of Data Cleaning
Data cleaning, sometimes called data scrubbing, is a much more focused and often reactive task. It is all about identifying and fixing errors, inconsistencies, and inaccuracies within a dataset. Think of it as a vital subset of the larger curation process, but it is not the whole story.
Data cleaning fixes the past by correcting existing errors. Data curation builds for the future by proactively adding long-term value and context.
A typical data cleaning job might involve removing duplicate customer records, correcting misspelled city names, or filling in missing zip codes. The goal is purely tactical: fix immediate problems to make the dataset usable for a specific, urgent task. Cleaning alone does not add new insights or prepare the data for diverse future applications.
Data Curation: The Strategic Difference
This is where data curation steps in as the proactive, strategic process. It is not just about cleaning data but actively enhancing its value for long-term use. The heart of data curation is its focus on enrichment and context. It is a continuous, human-guided effort to make a dataset more discoverable, understandable, and valuable for a range of applications, especially for complex AI models.
To make these distinctions crystal clear, here is a quick breakdown of how these concepts stack up against each other.
Data Curation vs. Related Concepts
| Concept | Primary Goal | Scope | Key Activities |
|---|---|---|---|
| Data Management | Availability & Security | The entire data infrastructure and its lifecycle. | Storage, governance, backup, security protocols. |
| Data Cleaning | Accuracy & Consistency | A specific dataset or database with existing errors. | Removing duplicates, correcting errors, handling missing values. |
| Data Curation | Long-term Value & Reusability | A specific dataset, with an eye toward future use. | Cleaning, annotation, enrichment, validation, documentation. |
Understanding these differences is not just academic; it is crucial for business leaders. It helps everyone see that while management provides the foundation and cleaning fixes immediate flaws, only strategic data curation can turn a simple dataset into a powerful, enduring asset for AI innovation. It is the difference between just having data and having data that truly drives results.
How Quality Data Curation Drives Business Results
Let's move beyond the technical details. A practical data curation definition must connect directly to business outcomes. Investing in quality data is not just an abstract IT exercise; it is a direct investment in your bottom line. Meticulously curated datasets deliver measurable returns by boosting model performance, speeding up innovation, and reducing significant operational and reputational risks.
This process is what turns raw, messy information into a high-value asset that fuels real competitive advantage and tangible growth.

Accelerating Model Development and Deployment
One of the first things you will notice with great data curation is a massive drop in model training time. When your algorithms are fed clean, relevant, and accurately labeled data from day one, they converge much faster. This efficiency means your data science teams spend less time chasing down errors and more time innovating.
By cutting out endless cycles of retraining and debugging, businesses can get their AI-powered products and services to market sooner. That speed is a critical advantage, letting you pivot quickly to meet market changes and customer demands. When paired with effective Business Process Management (BPM) solutions, the entire data pipeline becomes more efficient and predictable.
Enhancing Accuracy and Reducing Risk
The old saying "garbage in, garbage out" is brutally honest when it comes to AI. Feed a model bad data, and you will get a flawed model, one that can lead to severe financial and reputational damage.
A well-curated dataset is your first line of defense against algorithmic bias and expensive mistakes. By ensuring your data is balanced, representative, and free of errors, you build models that are not only more precise but also fairer and more dependable.
Consider these real-world use cases:
- Healthcare: An AI model trained on impeccably curated medical images can detect diseases earlier and with greater accuracy, leading to better patient outcomes. A model trained on a biased or poorly labeled dataset could miss critical signs or generate false positives, with life-altering consequences.
- Finance: In fraud detection, algorithms need to find subtle, anomalous patterns across millions of transactions. A dataset curated for accuracy and completeness lets the model separate legitimate activity from fraud with surgical precision, saving millions in potential losses.
Fueling Innovation and Competitive Advantage
Ultimately, high-quality data is the fuel for innovation. Organizations with well-curated datasets are in the best position to explore new AI applications, from hyper-personalized customer experiences to predictive maintenance on the factory floor. It becomes a strategic asset that allows you to ask tougher questions and build more sophisticated solutions than your competitors can.
The market already understands this. The broader data-as-a-service market, built on the principles of curation, is projected to grow from USD 29.72 billion in 2026 to USD 72.07 billion by 2031. Healthcare is the fastest-growing vertical within this market, expanding at an impressive 21.8% CAGR as organizations deploy AI for diagnostics and patient engagement.
Best Practices for a Successful Data Curation Workflow
Building a robust data curation workflow does not happen by accident. It is a deliberate effort that blends clear standards, strong governance, and the right mix of technology and human expertise. Following a set of practical, battle-tested principles helps you move from just collecting data to creating genuinely valuable, AI-ready assets.
These best practices ensure your workflow produces consistent, high-quality results that directly support your business goals. When you implement them, you are not just cleaning data; you are building a scalable and dependable process.

Define Quality Standards Upfront
Before a single piece of data is touched, your team must agree on what “high quality” actually means for your project. This involves creating detailed documentation that spells out acceptance criteria, formatting rules, and how to maintain labeling consistency. Good documentation becomes the single source of truth for everyone involved.
For example, a medical AI project might define quality as 99.5% accuracy on tumor segmentation, with specific rules for handling ambiguous boundaries. Clear standards eliminate guesswork, reduce rework, and get everyone aligned. You can explore our detailed guide on developing effective annotation guidelines to start building your own framework.
Combine Automation with Human Expertise
Automation is fantastic for handling repetitive, large-scale tasks like finding duplicates or standardizing formats. However, technology alone often misses the nuanced context and subtle errors that only a human expert can spot. The most successful workflows blend the efficiency of automated tools with the critical thinking of skilled annotators.
An effective data curation definition acknowledges that technology scales the work, but human oversight guarantees the quality. It is this partnership that unlocks the highest levels of accuracy and reliability.
Prioritize Domain-Specific Knowledge
Generic curation skills are not enough for complex fields. An annotator labeling financial documents needs to understand regulatory terms, just as one working on medical scans must recognize anatomical structures. For building trustworthy AI models, this domain expertise is non-negotiable.
This need for specialization is driving major growth in niche markets. For instance, according to a report from Markets and Markets, the global biological data curation market, a highly specialized segment, was valued at USD 581.4 million in 2024 and is projected to reach USD 1,277.1 million by 2030. This rapid expansion highlights the demand for expert-led curation. An experienced partner brings this critical skill set to the table, ensuring your data is not just clean but also contextually accurate.
Find the Right Data Curation Partner with Prudent Partners
Your AI is only as good as the data it is trained on. This is a simple truth that often gets lost in the excitement over algorithms and models.
While the core ideas behind data curation sound straightforward, putting them into practice at scale is a complex challenge. It demands specialized skills, a relentless focus on detail, and a deep understanding of your industry. Choosing the right partner is not just a tactical move; it is a strategic investment in the reliability and performance of your entire AI initiative.
At Prudent Partners, we do not just clean your data; we transform it into your most valuable asset. We go beyond the basics to deliver end-to-end data curation solutions, building a foundation of trust and accuracy that your models can depend on.
Why Prudent Partners Is the Right Choice
We do not just talk about excellence; we prove it. Our commitment is backed by a rigorous, multi-layer quality assurance process and deep expertise across industries, ensuring your datasets meet the absolute highest standards.
With ISO 9001 and ISO/IEC 27001 certifications, we do not just promise quality and security; we have them independently verified. Our workflows are built from the ground up to protect your sensitive information while delivering 99%+ accuracy.
Ready to unlock what your data is truly capable of? Connect with our team for a consultation and see how our precision data curation services can power your next AI breakthrough.
Frequently Asked Questions About Data Curation
Data curation is a complex topic. This section addresses the most common questions teams ask when they are first getting started.
What Makes Data Curation So Challenging?
The main challenge with data curation is that it is not a one-time technical task; it is a long-term strategic commitment. The complexity grows quickly. You must wrestle with massive volumes of data from various sources, enforce consistency, and possess deep domain knowledge to ensure the context is correct. It is a marathon of detail-oriented work, and maintaining that level of quality over time is what separates great AI from mediocre AI.
How Do You Measure the Success of Data Curation?
You measure success by its impact on your business outcomes and your models. When curation is done right, the results are tangible and measurable.
Key metrics to track include:
- Model Accuracy: A direct lift in precision, recall, and F1 scores. This is the clearest sign of success.
- Reduced Training Time: Clean, well-structured data helps models converge faster, saving time and compute costs.
- Lower Bias Scores: Proof that your models are becoming fairer and more equitable in their outcomes.
- Data Reusability: How often is a dataset being used for new projects? High reuse indicates you have created a truly valuable asset.
What Are the First Steps for a Team New to Data Curation?
If your team is just starting out, do not try to accomplish everything at once. The absolute first step is to agree on what "good" looks like.
Start by defining a "golden record" for your most important dataset. What does a perfect, complete, and accurate entry look like? Once you have that, build out your annotation guidelines and document every step of your process. Getting everyone on the same page from day one is essential.
Can Data Curation Be Fully Automated?
No, and it is important to understand why. While automation is a lifesaver for scaling repetitive tasks like deduplication or standardizing formats, it cannot replace human judgment. The most critical part of any data curation definition is the human touch needed for contextual understanding, quality validation, and sorting out complex edge cases. The best approach will always be a smart mix of automated tools managed by expert human oversight.
At Prudent Partners, we transform the messy, complicated process of data curation into a reliable workflow that fuels your AI ambitions. Our ISO-certified processes, multi-layer quality checks, and unwavering commitment to 99%+ accuracy mean your models are built on a rock-solid foundation of trust.
Connect with us today to discuss your data curation needs and build your next great AI solution.