
Data curation is not just about cleaning up messy spreadsheets. It is the active, ongoing process of managing data through its entire lifecycle to make it truly valuable for analysis and machine learning. Think of it as transforming raw, chaotic information into a trustworthy, high-value asset. This discipline ensures data is relevant, contextualized, and ready for whatever you throw at it.
What Data Curation Actually Means

Imagine a museum curator. Their job is not just to dust off old artifacts. They carefully select, preserve, and arrange pieces in an exhibit, adding context to tell a compelling story. Data curation does the exact same thing for your organization’s information. It is a strategic discipline that makes sure your data is not only clean but perfectly suited for its intended purpose.
This is far more than a one-time cleanup job. Curation is a continuous cycle of maintaining and improving data quality, relevance, and usability. The whole point is to build a rock-solid foundation that supports accurate analytics, powerful AI models, and confident business decisions.
From Raw Data to a Strategic Asset
Effective curation is what turns that jumble of raw information into a polished, strategic asset. It involves a few core activities that add structure and value every step of the way.
The key components of the curation process include:
- Organizing Data: This is about creating order. It means structuring datasets logically, using consistent naming conventions, and building a clear hierarchy so data is easy to find and understand.
- Standardizing Formats: Curation makes sure data from different sources plays nicely together. It eliminates frustrating inconsistencies in formats like dates, addresses, or units of measurement.
- Enriching with Context: This step adds valuable metadata and labels, giving the data crucial context. It is what makes the information meaningful and truly useful for machine learning models.
- Maintaining Lifecycle Quality: Curation is never "set it and forget it." It includes ongoing validation, updates, and archival plans to keep the data reliable and trustworthy over time.
To give you a clearer picture, here’s a quick breakdown of how these activities come together.
Data Curation at a Glance
This table shows how each core activity transforms data from a raw state into an analysis-ready asset, highlighting the direct impact on AI model performance.
| Core Activity | Objective | Impact on AI Models |
|---|---|---|
| Data Organization | Create a logical structure for easy access and interpretation. | Reduces feature engineering time and helps models find patterns faster. |
| Data Standardization | Ensure consistency across different data sources and formats. | Prevents model confusion caused by inconsistent inputs (e.g., "USA" vs. "United States"). |
| Data Enrichment | Add metadata, labels, and contextual information. | Provides richer features for models to learn from, boosting accuracy and predictive power. |
| Lifecycle Management | Maintain data quality through validation, updates, and archival. | Protects against model drift by ensuring the training data remains relevant and accurate. |
By systematically applying these principles, you can build high-quality AI training datasets that serve as the bedrock for innovation. This meticulous preparation is what separates high-performing AI systems from those that fail to deliver reliable results.
Why Data Curation Is Your AI's Foundation
In the world of artificial intelligence, a powerful algorithm is only half the story. The old saying "garbage in, garbage out" is amplified with AI, where even the most advanced models will fail if they are trained on flawed, biased, or irrelevant data.
Data curation is the essential quality control that stops this from happening. It is the foundational investment that ensures your AI initiatives deliver accurate insights and real business value, not just expensive mistakes.
Without meticulous curation, you risk building models that produce unreliable predictions, leading to costly errors and misguided strategies. A model trained on a poorly curated dataset might learn the wrong patterns, amplify existing biases, or simply fail when it encounters new, real-world scenarios. This is why a proactive approach to data curation is a strategic necessity, not an optional expense.
The Tangible ROI of High-Quality Data
Investing in a robust curation process generates measurable returns across your entire operation. The impact shows up directly in better model performance, greater efficiency, and a faster pace of innovation. Companies that get their data quality right from the start build a significant competitive advantage.
The market data backs this up. Data scientists often spend a staggering 60% to 80% of their project time just cleaning and preparing data. It's no surprise the global data preparation market is valued at roughly USD 6.50 billion in 2024. It highlights the massive industry-wide effort poured into this foundational work.
By investing in proper curation upfront, you reclaim that lost time, slash the risk of model failures, and get to valuable insights much faster. You can explore more on these data preparation market trends and what they mean for AI development.
A well-curated dataset doesn't just improve model accuracy; it dramatically cuts the time and computational resources needed for training. It frees your data science team to focus on innovation and model refinement instead of getting stuck in endless data cleanup cycles.
Ultimately, curation transforms your raw data from a potential liability into your most powerful strategic asset. It builds the stable groundwork you need to create AI systems that are not only intelligent but also trustworthy, scalable, and directly aligned with your business goals.
Curation vs. Cleaning vs. Governance Explained
In the world of data, it is easy to get tangled in a web of similar-sounding terms. Data curation, data cleaning, and data governance are often thrown around interchangeably, but they represent distinct, critical functions. Getting the differences right is the first step toward building a data strategy that actually works.
Think of it like managing a world-class library. Data governance sets the rules: the Dewey Decimal System, the checkout policies, and the security protocols. Data cleaning is the librarian fixing a torn page or re-alphabetizing a misplaced book. Data curation, however, is the head librarian who decides which books to acquire, how to categorize them for different audiences, and which collections to feature to make the library truly valuable.
While all three aim for better data, they operate at completely different altitudes.
Comparing Key Data Management Disciplines
To cut through the noise, it helps to see these disciplines side-by-side. Each has a unique focus, a different goal, and its own set of activities. Understanding where one ends and the other begins is key to assigning the right resources to the right problems.
| Discipline | Primary Scope | Main Goal | Example Activities |
|---|---|---|---|
| Data Cleaning | Individual Datasets | Correct errors and inconsistencies at a granular level. | Removing duplicate entries, correcting typos ("St." vs. "Street"), handling missing values. |
| Data Curation | Datasets & Collections | Maximize the long-term value and usability of data for specific goals. | Enriching data with metadata, organizing it for AI training, ensuring relevance and context. |
| Data Governance | Entire Organization | Establish policies, standards, and accountability for data as a corporate asset. | Defining data ownership, setting access controls, ensuring regulatory compliance. |
As you can see, cleaning is tactical, governance is strategic, and curation is the essential bridge that connects the two, turning raw data into a purpose-driven asset.
What Is Data Cleaning?
Data cleaning is the most hands-on of the three. It is the essential, ground-level work of fixing what is obviously broken in a dataset. The goal is simple and immediate: identify and correct errors, inconsistencies, and inaccuracies.
Common cleaning tasks include:
- Finding and removing duplicate customer records.
- Standardizing formats, like converting "USA," "U.S.," and "United States" into a single, consistent value.
- Addressing missing values by either removing the record or filling in the gap with a logical estimate.
This is a reactive, focused process. You have a messy dataset, and you make it tidy.
What Is Data Governance?
At the opposite end of the spectrum sits data governance. This is not about the data itself but the rules of the road for the entire organization. It is the high-level framework of policies, roles, and standards that control how data is managed, accessed, used, and protected.
Think of it as the constitution for your data. It defines who can do what, with which data, and under what circumstances. A commitment to standards like ISO/IEC 27001, which we uphold at Prudent Partners, is a direct outcome of strong data governance. It ensures security and compliance are baked into every process, not just bolted on at the end.
Where Data Curation Fits In
This brings us to data curation, the strategic link between tactical cleaning and high-level governance. While curation certainly includes cleaning activities, its vision is much broader. Curation is about maximizing a dataset's long-term value by not just fixing it, but by actively enriching it with business context and ensuring it is perfectly suited for a specific purpose, like training a high-stakes AI model.
Ultimately, data curation is a proactive, holistic discipline. It ensures your data is not only correct but also relevant, discoverable, and ready to generate real value, both today and for future projects.
The Data Curation Workflow in Action
To really grasp what data curation is, it helps to see the process in motion. Think of it as a repeatable, structured pipeline that takes raw, messy data and methodically turns it into a polished, high-value asset ready for AI model training or deep analytics. This is not a one-off task; it is a core operational workflow.
This diagram shows how different data management jobs fit together. Governance sets the high-level rules, curation applies strategic intelligence, and cleaning is one of the hands-on tasks that makes it all work.
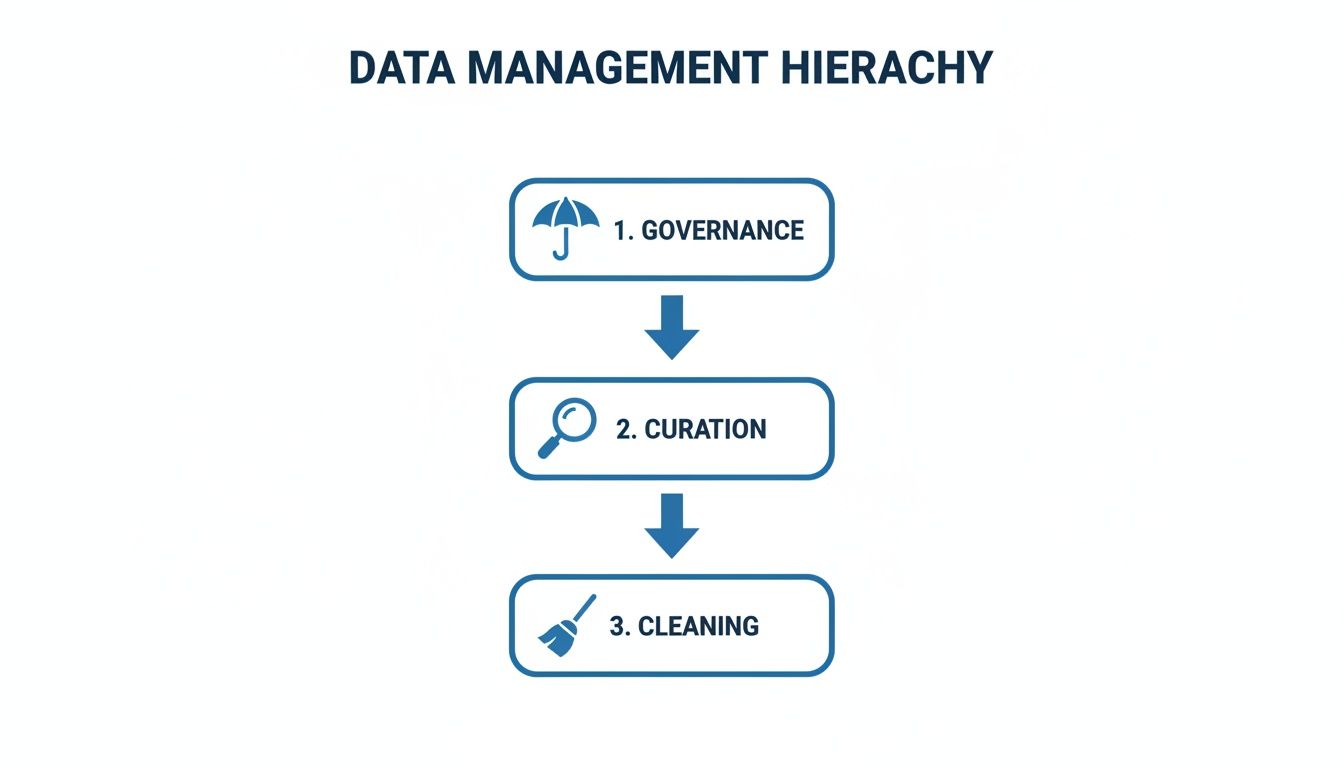
As you can see, curation sits right in the middle, guided by the bigger governance strategy but also rolling up its sleeves to manage essential activities like cleaning. This central role is what makes it so critical for preparing trustworthy data.
Key Stages of the Curation Pipeline
A strong curation workflow moves in logical steps, with each stage building on the one before it to make the data more reliable and useful.
-
Sourcing and Ingestion: It all starts with gathering the right raw materials. This means identifying and pulling data from all the relevant places, like internal databases, third-party APIs, or IoT devices. The first job is to get all this raw information into one place where you can work on it.
-
Profiling and Validation: Once the data is in, it is time for a health check. Profiling gives you a snapshot of your data's characteristics: its structure, its patterns, and how complete it is. Automated validation rules are then applied to flag obvious errors or weird outliers, giving you an initial baseline for quality.
-
Cleaning and Standardization: This is where the real cleanup happens. Your team will dive in to get rid of duplicate records, fix inaccuracies, and figure out what to do with missing values. Just as important is standardization. This ensures everything is consistent, like converting all dates to a single
YYYY-MM-DDformat or making sure address fields are uniform. -
Transformation and Enrichment: With a clean foundation, you can start adding serious value. Transformation involves reshaping the data to fit the exact needs of your project. But enrichment is where the magic happens. This is where you add context that makes the data truly powerful. For instance, our expert data annotation services can label images or text, creating the "ground truth" that machine learning models need to learn from.
-
Storage and Maintenance: Finally, the fully curated dataset is stored in a secure and accessible repository, often in a format optimized for fast queries. This last step also involves setting up rules for how long to keep the data and creating a maintenance schedule to ensure it stays accurate and relevant for the long haul.
How Specialized Curation Drives Innovation

As data gets more and more complex, the idea of data curation has shifted. What used to be a standard IT task has become a highly specialized field that is now fueling innovation, especially where data integrity is everything.
Take the life sciences and bioinformatics sectors. Here, meticulous data curation is the engine running drug discovery, genomic research, and clinical trials. Researchers are swimming in massive volumes of sequence, proteomics, and clinical-omics data, a world where one tiny error can ripple into huge consequences.
Curation as a Catalyst for Scientific Breakthroughs
In this high-stakes environment, specialized curation makes sure datasets meet the FAIR principles (Findable, Accessible, Interoperable, and Reusable). This framework is the gold standard for making scientific data trustworthy and, just as importantly, reproducible.
Expert curators handle critical tasks that a generalist simply cannot:
- Ensuring Provenance: They meticulously trace the origin story of every data point, from the moment a sample is collected to when it is sequenced.
- Validating Metadata: They double and triple-check that genomic data is correctly annotated with the right patient details, experimental conditions, and biological context.
- Enforcing Interoperability: They standardize complex data formats so information from different studies and labs can be pooled for bigger, more powerful analyses.
This focused approach has a real-world impact. The global market for biological data curation was valued at USD 581.4 million in 2024 and is expected to climb to USD 1,277.1 million by 2030. That growth alone tells you how critical this work has become. You can dive deeper into the growth drivers in biological data services to see the full picture.
Ultimately, this example proves a universal point. Whether you are in finance, geospatial analysis, or developing advanced AI like those using Retrieval-Augmented Generation, expert curation is what unlocks new possibilities. It ensures that innovation is built on a foundation of absolute trust.
Level Up Your Curation with the Right Partner
Knowing what data curation is and actually doing it well are two very different things. That gap between theory and a smooth, scalable workflow is exactly where most AI projects get stuck. It is also where a dedicated partner can turn your data strategy from a painful cost center into a serious business advantage.
Bringing in an expert is not just about getting more hands on deck. It is about injecting battle-tested processes and deep knowledge directly into your operation. This kind of collaboration helps you skip the common mistakes, speed up your timelines, and guarantee the kind of high-quality data that powerful AI models depend on.
Plugging Expertise Into Your Curation Workflow
At Prudent Partners, our services are built to slot right into every stage of your data curation workflow. We bring the specialized support you need to turn raw information into a true strategic asset, ensuring precision from start to finish.
Here is how we help:
- High-Accuracy Data Annotation: We enrich your datasets with the precise labels needed to create ground truth for robust machine learning models. This is a non-negotiable step in any serious curation process.
- AI Quality Assurance: Our QA experts do not just check the raw data; they validate your model outputs, making sure the entire pipeline holds up to the highest standards for accuracy and consistency.
- Business Process Management: We design and implement scalable systems that make your entire curation lifecycle more efficient, repeatable, and cost-effective.
When you hand off these critical functions, your team is free to focus on core innovation. We handle the meticulous work of building and maintaining your high-value datasets. The result? Faster development cycles, more reliable AI, and a real, measurable impact on your bottom line. A smart curation strategy is the key to unlocking what your data can really do.
Frequently Asked Questions
What's the Difference Between Data Curation and Data Annotation?
It helps to think of it like building a world-class library. Data curation is the entire strategic process: deciding which books to acquire, organizing them by subject, removing damaged copies, and ensuring the collection as a whole is valuable and useful.
Data annotation, on the other hand, is a specific task within that process. It is like putting the correct genre sticker on each individual book. It is a vital step, but it is just one piece of the larger curation puzzle.
How Can We Measure the Success of Our Data Curation Efforts?
You will see the results in your team’s efficiency and your model's performance. The most obvious KPI is a sharp drop in the time your data scientists spend cleaning and wrestling with data, a task that often eats up a staggering 60-80% of their work.
Beyond that, look for tangible business outcomes: higher accuracy in your AI models, fewer data-related errors in production, and faster, more reliable insights from your analytics projects.
Can Data Curation Be Fully Automated?
While automation is a huge help, a completely hands-off process is rarely the answer for complex, high-stakes datasets. Tools are great for repetitive tasks like finding duplicates or standardizing date formats.
However, human expertise remains crucial for the tricky parts: understanding nuanced business context, setting the right quality rules, and validating what the automated tools produce. The most effective approach is a human-in-the-loop system, where you get the scale of technology guided by the wisdom of an expert.
Ready to transform your raw data into a high-value, AI-ready asset? The experts at Prudent Partners specialize in building precision curation and annotation workflows that deliver measurable impact. Connect with us today for a customized data strategy consultation.