
Machine learning images are the foundational textbooks from which an artificial intelligence learns to perceive and interpret the visual world. These datasets, ranging from everyday photographs to complex medical scans, are meticulously labeled to teach AI models how to recognize objects, understand complex scenes, and make informed decisions. For any organization aiming to leverage computer vision, mastering the preparation and quality assurance of these images is a critical step toward achieving scalable, high-impact results.
How AI Learns to See the World
Before an AI can navigate a vehicle through city streets or identify a microscopic defect on a manufacturing line, it must undergo a rigorous training process. This process mirrors how humans learn—starting with fundamental concepts and gradually building toward more complex understanding. For an AI, this entire education depends on the quality, accuracy, and diversity of the machine learning images it studies.
An AI model doesn’t inherently see a “car” or a “pedestrian.” It begins by processing a vast grid of pixels. Only after training on thousands, or even millions, of expertly annotated images does it start to discern the patterns—the specific pixel arrangements that consistently signify a “car.” This is where the groundwork for any successful computer vision project is laid, and where precision in data preparation delivers a measurable impact on performance.
From Pixels to Patterns
The journey from raw pixel data to actionable, real-world insight involves several core computer vision tasks. Each task represents a deeper level of comprehension, much like a person first recognizes a shape, then identifies it as a distinct object, and finally understands its context within a larger scene.
This infographic breaks down the foundational computer vision tasks that transform a simple image into actionable intelligence.
As you can see, there’s a clear progression from basic classification to the highly detailed output of segmentation, with each step demanding greater complexity and data accuracy. This is not a niche technological pursuit; it is a significant economic engine driving innovation across industries.
The global image recognition market was valued at around USD 53 billion and is projected to hit over USD 146 billion by 2032. This explosive growth is fueled directly by AI’s expanding role in healthcare, retail, automotive, and security.
This staggering growth highlights how critical high-accuracy data pipelines have become. Without a human-in-the-loop focus on data quality from the outset, companies risk building their models on a shaky foundation, leading to poor performance, costly rework, and missed opportunities. You can find more details on the image recognition market’s key drivers here.
To help clarify these concepts, here’s a breakdown of the core tasks you’ll encounter in computer vision.
Core Computer Vision Tasks Explained
| Vision Task | What It Does | Real-World Example |
|---|---|---|
| Image Classification | Assigns a single label to an entire image. | A social media platform automatically tagging a photo as “beach” or “city.” |
| Object Detection | Locates and identifies multiple objects in an image with bounding boxes. | A self-driving car identifying other vehicles, pedestrians, and traffic signs. |
| Semantic Segmentation | Assigns a class label to every pixel in an image. | An agricultural drone mapping out which pixels are “healthy crops” vs. “weeds.” |
| Instance Segmentation | Like semantic segmentation, but also distinguishes between individual instances of the same object. | A retail analytics system counting each individual apple in a crate, not just identifying the “apple” region. |
Each of these tasks serves a different purpose, but they all share one common requirement: exceptionally high-quality annotated data.
The quality of that initial dataset directly determines your model’s capabilities. Think of it like building a skyscraper—if the foundation is weak, the entire structure is compromised. In AI, meticulously labeled data is that non-negotiable foundation. This makes professional data annotation services a strategic investment, not just an operational cost. It is how you guarantee your AI learns from a reliable source of truth, setting the stage for dependable, real-world performance and measurable business impact.
Preparing Your Images for Machine Learning
Raw, unlabeled images are like a book written in a language your AI cannot comprehend. They are full of visual information, but without context, they are just meaningless pixels. The process of preparing machine learning images is where we translate that raw data into a structured format the model can learn from, turning a liability into a valuable asset.
This critical step, known as data annotation, is what transforms those pixels into high-value training data that drives model accuracy and reliability.
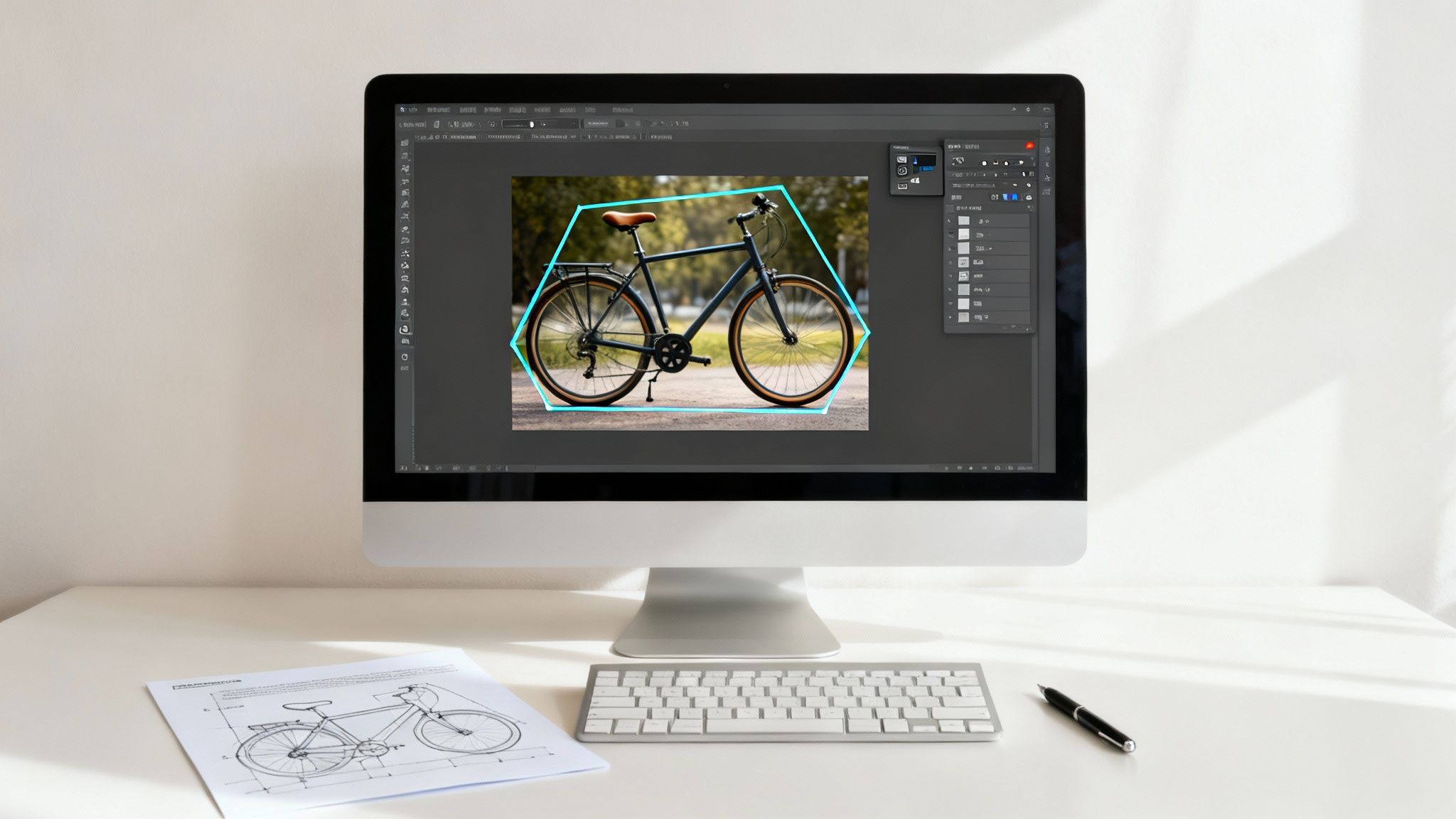
This preparation phase is far more than just drawing boxes around objects. It is a deliberate, structured process that involves selecting the right annotation technique for your specific business goal, then ensuring every label is precise, consistent, and free from bias. The quality of this foundational work directly dictates your model’s future performance; shortcuts here almost always lead to costly failures and delays down the road.
Choosing the Right Annotation Technique
Not all computer vision tasks are created equal, and neither are the annotation methods used to train them. Selecting the right technique is the first, and arguably most important, step toward building a high-performing model. Each method offers a different level of detail and is tailored for distinct use cases, directly impacting the accuracy and scalability of your solution.
Here are some of the most common types of image annotation:
- Bounding Boxes: This is the simplest form of annotation—drawing a rectangle around an object. It’s ideal for object detection tasks where the model only needs to know an object’s location and general shape, such as identifying cars and pedestrians in a street view for traffic analysis. Its efficiency makes it a practical choice for large-scale projects.
- Polygons: For objects with irregular shapes that do not fit neatly into a rectangle, polygons deliver much greater precision. Annotators trace an object’s outline with a series of connected points, creating a custom shape. This is a common and effective technique in agriculture for identifying individual plants or in satellite imagery for mapping buildings and land use.
- Semantic Segmentation: This incredibly detailed technique involves classifying every single pixel in an image. The result is a pixel-perfect map where all pixels belonging to “cars” are one color, all “road” pixels are another, and so on. It is essential for applications that demand a deep, granular understanding of a scene, like medical imaging analysis or autonomous vehicle navigation.
The choice between these methods depends entirely on what you need your model to accomplish. Bounding boxes are fast and cost-effective for general detection, while segmentation is non-negotiable for tasks requiring granular detail and high accuracy. Prudent Partners helps clients navigate these choices, ensuring the selected approach aligns perfectly with their operational goals and delivers measurable impact. You can learn more about how we implement these techniques in our detailed guide to professional image annotation services.
Building a Diverse and Unbiased Dataset
Once you have selected an annotation method, the next challenge is curating the dataset itself. A model is only as good as the data it is trained on. If your dataset lacks diversity or contains hidden biases, your AI will inherit those exact same flaws, leading to poor performance and inequitable outcomes.
For example, a facial recognition model trained primarily on images of one demographic will perform poorly and unfairly on others. An autonomous vehicle trained only on images from sunny, clear days will be a liability in rain or snow. Mitigating this risk requires a deliberate and thoughtful strategy focused on real-world representation.
A successful AI model must generalize to the real world, not just the specific images it was trained on. This is why dataset diversity—covering a wide range of scenarios, lighting conditions, angles, and object variations—is non-negotiable for building robust and equitable AI systems.
To achieve this, teams must actively source images that represent the full spectrum of conditions the model will encounter in production. This may mean collecting data from different geographic locations, times of day, and weather patterns. A human-centered approach to data sourcing is your first line of defense against building a biased or ineffective model. By ensuring your machine learning images reflect the complexity of the real world, you create a solid foundation for a truly intelligent system.
Advanced QA for High-Stakes AI Models
In high-stakes AI, quality assurance is not just a final checkbox—it is a discipline woven into the entire data pipeline. When you’re working with machine learning images for critical applications in sectors like autonomous driving or medical diagnostics, a single misplaced annotation can cause a model to fail spectacularly. A reactive, “catch-it-at-the-end” approach is insufficient and introduces unacceptable risk.
Imagine an AI model designed to spot cancerous nodules in CT scans. If an annotation error causes the model to miss a tiny anomaly, the consequences are profound. Proactive, multi-layered quality assurance is the safety net that prevents these errors and transforms a promising model into a production-ready system you can trust.
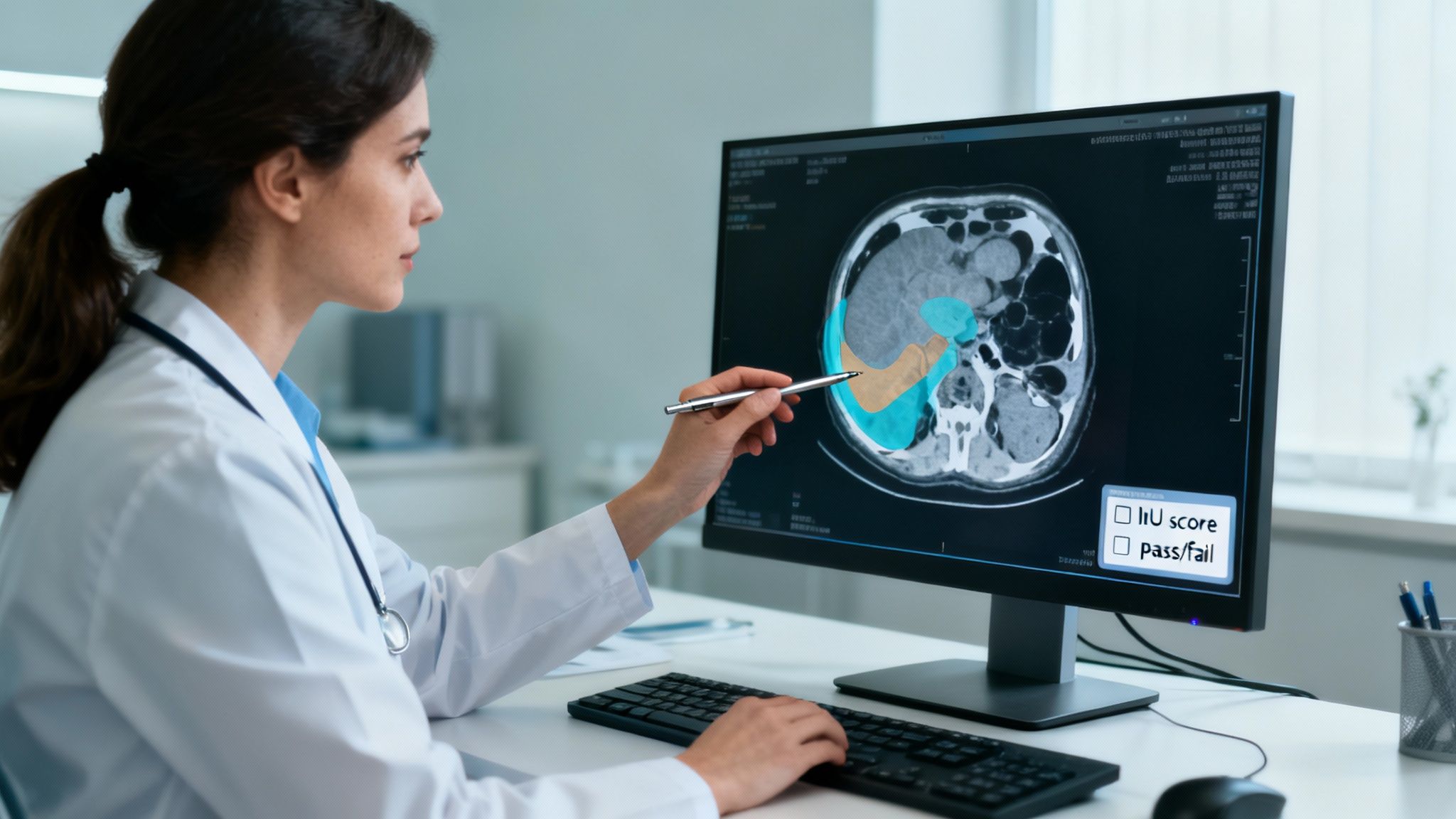
This is where a human-in-the-loop approach demonstrates its value. It blends the raw speed of automated checks with the nuanced judgment of human experts, creating a robust framework for achieving exceptional accuracy and reliability at scale.
Demystifying Core Quality Metrics
You cannot manage what you do not measure. While AI is filled with metrics, a few are absolutely essential for computer vision projects. Understanding these is the first step toward a robust QA workflow that delivers actionable insights.
Here are three key metrics, explained with practical examples:
- Intersection over Union (IoU): Think of this as a grade for how well a bounding box or mask fits an object. It measures the overlap between the human’s label (the ground truth) and the model’s prediction. An IoU of 1.0 (or 100%) is a perfect score, while 0 means they missed each other completely. In object detection, a common passing grade is 0.5—anything lower is considered a failure.
- Precision: This metric answers the question: “Of all the things the model flagged, how many were actually correct?” High precision means the model is trustworthy and does not generate false positives. If a security camera AI flags 10 “intruders” but 2 were just stray cats, its precision is 80% (8 correct / 10 total).
- Recall: This answers a different question: “Of all the real things that were there, how many did the model actually find?” High recall means the model is thorough and does not miss relevant instances. If there were 12 intruders in total, but the model only spotted 8, its recall is 66.7% (8 found / 12 total).
Balancing precision and recall is a classic challenge in AI development. A well-designed QA process continuously tracks these metrics to ensure the model is optimized for its specific, real-world application.
Implementing a Multi-Stage QA Workflow
A single layer of review is never enough for complex, high-stakes projects. A multi-stage workflow builds in multiple checkpoints to catch mistakes early, maintain dataset consistency, and ensure scalability.
Quality is not an act, it is a habit. For AI data, this means embedding quality checks at every stage—from initial annotation to final model validation. This proactive approach is what separates reliable AI from unpredictable algorithms.
An effective process combines automated checks with expert human review. Here is what a strong, scalable workflow looks like:
- Consensus Scoring: Several annotators label the same sample of images without seeing each other’s work. The results are compared to calculate a “consensus” score. If annotators disagree on an image, it is a red flag—either the guidelines are unclear, or the image represents a difficult edge case that requires expert review.
- Gold Standard Datasets: A small, perfectly labeled “gold set” is created by your top domain experts. This dataset becomes the benchmark for quality. New annotators are tested against it to measure their skills, and it’s used to periodically recalibrate the entire team to prevent annotation drift over time.
- AI-Powered Assistance: Modern QA uses AI to police itself. Automated scripts can instantly flag common errors like overlapping bounding boxes, labels that violate project rules, or annotations that are statistically anomalous. This frees up human reviewers to focus their expertise on the complex, subjective judgments that automation cannot handle.
This rigorous, multi-layered process is foundational to success. You can dive deeper into this topic by reading our guide on why data quality is the real competitive edge in AI, which breaks down how superior data pipelines create real business value.
Solving Industry-Specific Annotation Challenges
Generic, one-size-fits-all annotation strategies do not work for specialized applications. Computer vision challenges are rarely universal—every industry brings its own unique set of problems, regulations, and data complexities. An effective strategy for handling machine learning images must be tailored to the specific world the AI will operate in, whether that is a sterile operating room, a chaotic retail aisle, or a fast-moving highway.
This is where domain-specific expertise makes a measurable difference. It is what separates a model that merely functions from one that truly performs, ensuring the annotation process captures the subtle but critical details that a generic algorithm would miss.
Navigating Healthcare and Medical Imaging
The healthcare sector is governed by some of the tightest data privacy and accuracy standards on the planet. When annotating medical images—such as MRIs, CT scans, or ultrasounds—precision can directly impact a patient’s outcome.
The challenges here are significant:
- Regulatory Compliance: All data must be handled in strict compliance with regulations like HIPAA. This requires secure, end-to-end workflows and complete anonymization of patient data.
- Expert-Level Annotation: Identifying a tiny tumor or a hairline fracture is not a job for a generalist. It requires certified radiologists or medical professionals who possess the domain expertise to interpret complex imagery accurately.
- Extreme Precision: The boundaries of a lesion or an organ must be traced with pixel-perfect accuracy using sophisticated polygon or segmentation tools. A deviation of just a few pixels can lead a model to an incorrect conclusion.
In medical AI, there’s no such thing as “good enough.” The annotation process is a direct extension of the diagnostic workflow, demanding a level of precision and domain expertise that mirrors clinical practice itself.
Managing these projects requires a partner with proven experience in healthcare data and a robust Business Process Management (BPM) framework to ensure every step is documented, secure, and auditable.
Fusing Sensor Data for Autonomous Vehicles
The world of autonomous vehicles is defined by dynamic, unpredictable environments where safety is paramount. To make safe decisions in real-time, an autonomous system must process a continuous flood of information from multiple sensors to build a comprehensive, 3D picture of its surroundings.
This creates a unique annotation challenge known as sensor fusion. Self-driving cars do not just “see” with cameras; they use LiDAR for depth perception and radar to track object velocity. To build a reliable training dataset, you have to precisely align and label the data from all these sources in a 3D space—a task far more complex than drawing 2D boxes on an image.
Key hurdles in this space include:
- Multi-Sensor Alignment: Annotators must label objects consistently across camera feeds and the corresponding LiDAR point clouds, ensuring a pedestrian seen in a video is perfectly matched to their 3D representation.
- Tracking Dynamic Objects: Vehicles, cyclists, and pedestrians are constantly in motion. Annotations must track these objects across multiple frames to capture their trajectory and behavior over time.
- Edge Case Scenarios: The dataset must be populated with a wide variety of challenging conditions—heavy rain, blinding sun glare, and partially occluded objects—to train a model that is truly resilient and reliable.
Building these sophisticated, multi-modal datasets is a core mission for any team working on autonomous systems. For a deeper dive into this area, check out our guide on AI data annotation for autonomous vehicles.
Optimizing Operations in Retail
In retail, computer vision is used for everything from automating inventory counts with shelf-scanning robots to analyzing shopper behavior. However, retail environments are visually noisy and cluttered, which makes accurate product identification extremely difficult.
Annotators constantly face challenges like product occlusion (where items are partially hidden) and slight variations in packaging that can easily confuse a model. Furthermore, product catalogs can contain tens of thousands of individual SKUs. Accurately labeling products on a crowded shelf requires incredible attention to detail and crystal-clear guidelines to differentiate similar-looking items. Successfully deploying computer vision in a store requires solving these granular, real-world annotation problems first to ensure accurate and scalable performance.
Choosing Your Tools and Avoiding Common Pitfalls
The success of any computer vision project often comes down to the choices you make before a single image is labeled. Selecting the right tools and partners can mean the difference between a smooth, scalable workflow and one bogged down by costly rework and delays. It’s all about understanding the trade-offs and knowing where the common traps are hidden.
The market for machine learning images and the software that powers them is exploding. Projections show the global image recognition market rocketing from around USD 60 billion to a potential USD 280 billion by the early 2030s, with services and software making up over 39% of that value. You can dig deeper into these numbers on the image recognition market research page. This incredible growth means you have more tool choices than ever, but that also makes the decision more complex.
Selecting the Right Annotation Platform
Think of your annotation platform as the digital workbench where raw images get turned into structured, model-ready data. The decision usually boils down to two paths: open-source software or a fully managed, enterprise-grade solution.
- Open-Source Tools: Platforms like CVAT or Label Studio are fantastic for smaller projects, academic research, or teams with the engineering muscle to handle setup, maintenance, and inevitable troubleshooting. They’re free and highly customizable, but they often lack the advanced quality control features, user management, and dedicated support needed to scale effectively.
- Enterprise-Grade Solutions: Commercial platforms are built for large-scale operations right out of the box. They come with integrated QA workflows, detailed performance analytics, and dedicated customer support. While they require an investment, they deliver the stability and efficiency that production-level AI development demands.
The right tool isn’t just about a list of features; it’s about aligning with your team’s scale, expertise, and long-term project goals. A tool that works for a five-person research team will likely grind a 50-person enterprise deployment to a halt.
Sidestepping Common Project Pitfalls
Even with the best tools, many projects get derailed by predictable—and entirely preventable—mistakes. Just knowing what these pitfalls are is the first step toward avoiding them. This is where a managed services partner like Prudent Partners becomes invaluable, bringing the expertise to navigate these challenges from day one and turn potential roadblocks into smooth, managed processes.
We’ve seen it all before. The table below outlines the most frequent mistakes teams make and how an experienced partner provides the solution.
Common Project Pitfalls and How to Solve Them
| Common Pitfall | Impact on Project | The Expert Solution |
|---|---|---|
| Ambiguous Guidelines | Inconsistent annotations, high rework rates, and a confused model that fails to generalize. | Develop a detailed “rulebook” with visual examples and clear definitions for every edge case, then conduct rigorous team training. |
| Hidden Dataset Bias | The model performs poorly on real-world data that differs from its limited training set, leading to unfair or unreliable outcomes. | Proactively source and curate a diverse dataset that reflects the full spectrum of operational conditions. |
| Inadequate QA | Low-quality labels make it into the final dataset, poisoning the model and leading to poor performance and a lack of trust. | Implement a multi-stage QA workflow with consensus scoring, gold standard reviews, and automated checks. |
| Poor Scalability | In-house teams become overwhelmed as data volume grows, causing bottlenecks that delay the entire project timeline. | Leverage a managed services model with a trained, scalable workforce to handle fluctuating data needs without the overhead. |
Ultimately, trying to build a complex data operation from scratch often proves far less efficient than partnering with a team that has already mastered these challenges. When you outsource the heavy lifting of annotation, QA, and project management, your team is freed up to focus on what it does best: building exceptional AI models.
Building Your Next Vision AI Project with Confidence
If there’s one theme that runs through this entire guide, it’s this: world-class AI models aren’t born from complex algorithms alone. They’re built on a foundation of expertly prepared data. Success with machine learning images is less about brute-force computation and more about a smart, human-centered strategy focused on accuracy, consistency, and relentless quality assurance. Every single step, from curating the initial dataset to the final multi-stage review, directly shapes how your model performs in the real world.
As you map out your next computer vision project, remember that the quality of your data is the single most important predictor of its success. It’s what will determine your model’s reliability, its fairness, and its ability to handle whatever the real world throws at it.
Turning Data from a Liability into an Asset
Let’s be honest—navigating the complexities of annotation, quality control, and scalable data operations can feel like a grind. Too many teams get bogged down in the operational overhead, pulling valuable engineering resources away from where they’re needed most: core model development. Instead of trying to wrestle these challenges alone, it’s worth considering the measurable impact of a dedicated partner.
A strategic partner doesn’t just label data; they build the dependable data pipeline that fuels your innovation. This transforms data preparation from a potential bottleneck into a powerful strategic asset that accelerates your time to market.
Working with a team that lives and breathes data quality means you can sidestep the common pitfalls and build your project on solid ground from day one. This proactive approach stops costly rework before it starts and gives you genuine confidence in your AI’s outputs. You can even explore how our virtual assistant services can support your project management needs, freeing up your team to focus entirely on innovation.
Partner with Prudent Partners for Your Next Project
At Prudent Partners, we believe that exceptional AI is built on a bedrock of trust and precision. We bring together human expertise with battle-tested processes to deliver data that meets the highest standards of accuracy and consistency. Our whole approach is designed to give you complete confidence in the data powering your most critical models.
We invite you to connect with our experts and talk through your unique challenges. Whether you’re kicking off a brand-new project or looking to elevate an existing one, we can help you design a data strategy that’s perfectly aligned with your goals. Let us show you how we can help you build your next vision AI initiative with the quality and confidence it deserves.
Frequently Asked Questions About Machine learning Images
As computer vision projects move from theory to production, many teams run into the same practical questions. This section cuts through the noise to give you clear answers on the most common hurdles we see people face when working with machine learning images.
How Much Image Data Do I Need for My Project?
This is easily the question we hear most, and the honest answer is always: “it depends.” There’s no single magic number. A straightforward classification task might perform beautifully with just a few thousand high-quality images, whereas a model for an autonomous vehicle could demand millions to cover every possible scenario.
The real focus shouldn’t be on quantity, but on quality and relevance. A smaller, meticulously curated and labeled dataset will almost always beat a massive, noisy one. Plus, techniques like data augmentation—where you programmatically alter existing images by flipping, rotating, or changing the brightness—help you stretch the value of the data you already have.
The goal isn’t just to gather data; it’s to gather the right data. A dataset that’s diverse and covers all your critical edge cases is far more powerful than a million repetitive, easy examples.
What Is the Difference Between Object Detection and Segmentation?
While both tasks are about finding things in an image, they operate at completely different levels of precision. The best way to think about it is with a simple analogy.
- Object Detection: Imagine you’re looking at a group photo. Object detection is like drawing a simple rectangle around each person and slapping a “person” label on it. It tells you what is in the image and gives a rough idea of where it is. Fast, efficient, and great for counting things.
- Semantic Segmentation: Now, take that same photo. Segmentation is like taking a fine-tipped marker and coloring in every single pixel that belongs to a person. It creates a pixel-perfect map of the scene, showing the exact shape and boundaries of each object class.
You’d use object detection when you need speed and a general location, like tracking inventory on a shelf. You need segmentation when precision is non-negotiable, like in medical imaging, where the exact boundary of a tumor is critical.
How Can I Ensure My Annotations Are Consistent?
Inconsistent annotations will poison your dataset and confuse your model, leading to poor performance. Consistency isn’t an accident; it’s the result of rigorous documentation and a rock-solid quality assurance (QA) process.
Here are the strategies that actually work:
- Create a Detailed “Rulebook”: Your annotation guidelines need to be crystal clear. Include visual examples for both correct and incorrect labels, paying special attention to those tricky edge cases that are bound to pop up.
- Use Consensus Scoring: Have several annotators label a small sample of the same images. The areas where they disagree are gold—they expose the ambiguities in your rulebook that need to be clarified.
- Implement Multi-Layer Reviews: A workflow where senior reviewers check the work of the primary annotators is essential. This catches errors early and enforces a high standard of quality across the entire team and dataset.
At Prudent Partners, we don’t just talk about quality—we build it into every step of our process. Our QA workflows are designed to ensure your model is trained on a reliable, consistent source of truth. Ready to build your next vision AI project with confidence? Contact us to schedule a pilot.