
At its heart, medical data annotation is the process of labeling medical information, like MRI scans, clinical notes, or pathology slides, so that AI algorithms can understand it. It is the essential bridge that turns raw, unstructured healthcare data into a structured format that machines can learn from, forming the very foundation of reliable medical AI.
The Foundation of Medical AI: What Is Medical Data Annotation?
Think of an artificial intelligence model as a medical student. Before it can begin to diagnose diseases, it must study countless examples that have been reviewed and explained by seasoned experts. Medical data annotation is that exact educational process, but for machines.
When an expert radiologist points to a shadow on an X-ray and says, "That's a fracture," they are providing context. In the digital world, an annotator does the same thing for an AI, meticulously labeling anomalies, organs, and other critical features within digital files. This process is fundamental because most healthcare data is inherently unstructured. An MRI scan or a physician's handwritten note is meaningless to a computer until annotation provides that vital context.
The Impact on Patient Outcomes
The importance of this work cannot be overstated. In healthcare, precision is everything. A single, seemingly minor labeling error during the training phase could undermine a diagnostic model's reliability. This could lead to incorrect assessments down the line and directly impact patient outcomes.
High-quality annotation ensures that AI tools are built on a bedrock of accuracy, making them safe and effective for real-world clinical use. This meticulous work is what enables AI to assist with incredible tasks, such as:
- Identifying tumors in CT scans with superhuman speed and accuracy.
- Analyzing thousands of electronic health records (EHRs) to predict patient risk factors.
- Powering robotic surgery with enhanced, real-time visual guidance.
The Surging Demand for Quality Data
As healthcare becomes a primary driver of AI innovation, the demand for accurately labeled datasets is exploding. The global data annotation market was valued at $630 million in 2021 and is projected to grow at a compound annual growth rate (CAGR) of 26% through 2030. This incredible growth highlights just how critical specialized expertise in medical data annotation has become. You can explore more about the future of healthcare AI and its market trends.
At its core, medical data annotation is about teaching AI to see and understand the immense complexities of human health. It demands a powerful combination of deep clinical knowledge, technical skill, and an unwavering focus on quality.
Ultimately, this field is not just about drawing boxes on images; it is about building trust in the next generation of medical technology. By ensuring AI models learn from the most accurate and reliable information possible, we pave the way for a future where technology works hand-in-hand with clinicians to improve health for everyone.
Understanding Core Types of Medical Data Annotation
To truly grasp the power of medical data annotation, one must look at the specific methods used to label the different kinds of healthcare data. Each type of annotation serves a specific purpose, turning raw, unstructured information into structured intelligence that a machine can understand. Think of these techniques as the essential building blocks for creating specialized AI in diagnostics, research, and patient care.
Let's move beyond abstract concepts and examine practical applications. We will break down the main annotation types and see how each one fuels a real-world healthcare solution. The chosen method always depends on two factors: the type of data being worked with and the clinical problem the AI is intended to solve.
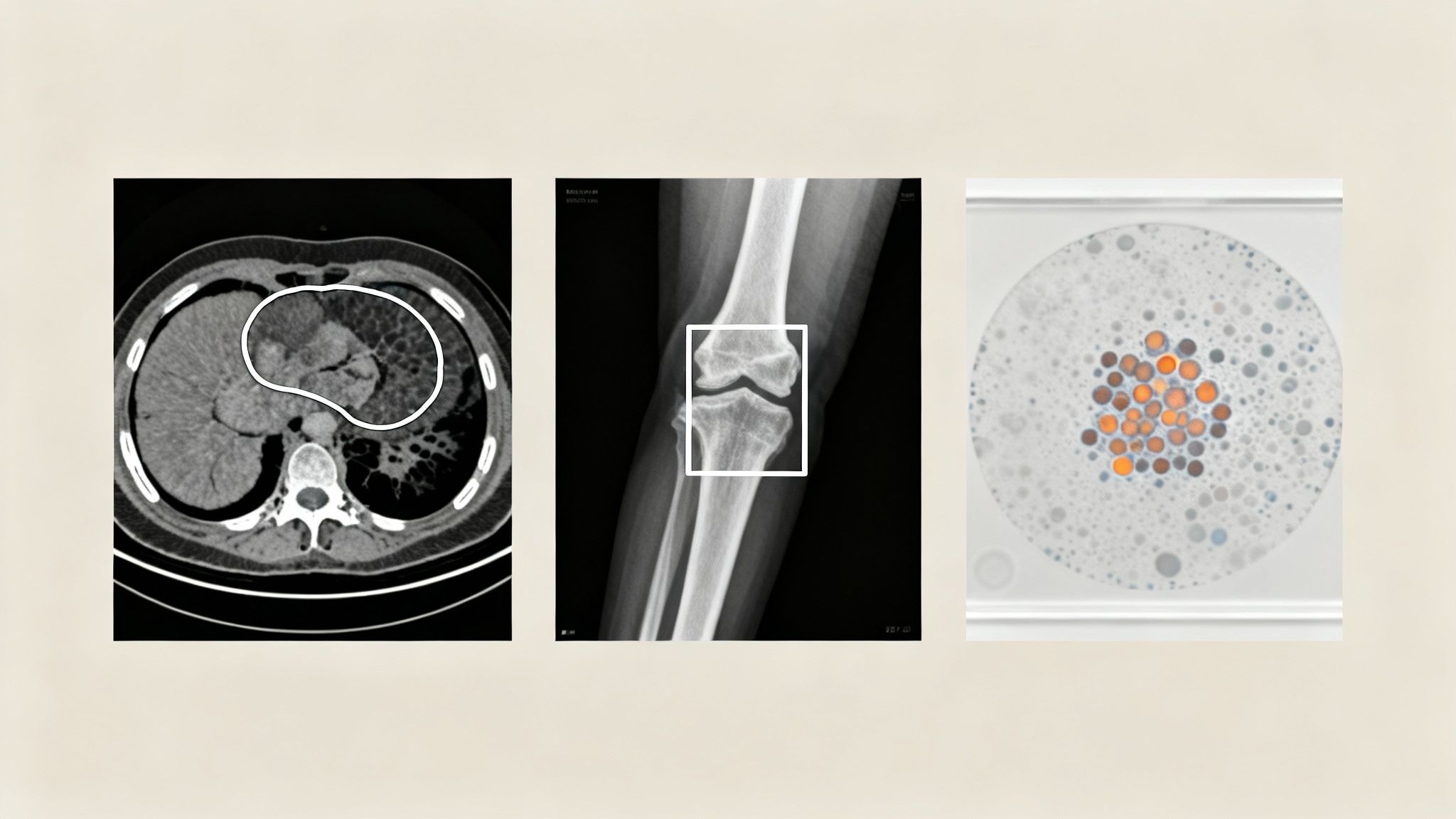
Labeling Medical Images for Computer Vision
Medical imaging is often the first application that comes to mind with medical annotation. It is where visual data from X-rays, CT scans, and MRIs is meticulously labeled by experts. This process teaches an AI model to "see" by identifying anatomical structures, finding anomalies, and spotting diseases with incredible accuracy.
A few core techniques are used, each suited for a different diagnostic goal:
- Bounding Boxes: This is one of the most direct methods. An annotator simply draws a rectangle around an object of interest. For example, a radiologist might use bounding boxes to quickly highlight potential fractures on an X-ray, which in turn trains a model to flag similar injuries for review.
- Semantic Segmentation: This is a much more detailed approach. Instead of a simple box, semantic segmentation involves tracing the exact pixel-by-pixel border of an object. This level of precision is critical for tasks like outlining a tumor on a CT scan to measure its volume or plan a surgical procedure.
- Keypoint Annotation (Pose Estimation): This technique involves marking specific points of interest on an image. In orthopedics, for instance, an AI can be trained by placing keypoints on joints in an X-ray. This allows the model to measure angles and assess alignment, providing valuable assistance in surgical planning.
To illustrate how these annotation types connect to real-world AI applications, here is a quick breakdown.
Common Medical Annotation Types and Their AI Applications
| Annotation Type | Data Source Example | Annotation Technique | AI Application |
|---|---|---|---|
| Bounding Box | Chest X-ray | Drawing a rectangle around suspicious nodules | Automated detection of potential lung cancer for radiologist review |
| Semantic Segmentation | Brain MRI | Outlining the precise border of a glioblastoma tumor | Calculating tumor volume and tracking treatment response over time |
| Keypoint Annotation | Orthopedic X-ray | Marking key joint locations on a knee or hip | AI-assisted surgical planning for joint replacement surgeries |
| Named Entity Recognition | Electronic Health Record (EHR) | Tagging diagnoses, medications, and symptoms in clinical notes | Identifying patients at high risk for adverse drug reactions |
| Audio Transcription | Doctor-patient consultation recording | Transcribing speech and labeling medical terms | Creating automated clinical summaries to reduce physician burnout |
This table shows that the right annotation method is key to building an AI tool that solves a specific clinical problem, whether it is finding a tumor or organizing patient records.
Unlocking Insights from Pathology and Text
Annotation is not just for radiology. It is just as crucial for making sense of other complex medical data, from microscopic tissue samples to unstructured clinical notes. Each of these requires a specialized approach to extract meaningful information that would otherwise be inaccessible to a machine.
In digital pathology, for example, annotators might use semantic segmentation to classify different cell types within a high-resolution image of a tissue sample. This trains AI models to spot cancerous cells, count specific cell populations, or identify biomarkers for disease. It automates a process that is traditionally time-consuming for pathologists, allowing for faster and more consistent analysis at a massive scale.
Medical data annotation transforms unstructured clinical text from a simple record into a dynamic source of searchable, analyzable information. It gives AI the ability to read and comprehend a doctor's notes, much like a human would.
For the clinical text buried in Electronic Health Records (EHRs), Natural Language Processing (NLP) techniques are essential. Named Entity Recognition (NER) is a key method where annotators tag specific pieces of information, like diagnoses, medications, dosages, and patient symptoms, within unstructured notes. This trains an AI model to pull out these critical details from thousands of records, turning a wall of text into structured data. This data can then be analyzed to spot patient trends, predict adverse drug reactions, or manage population health.
Navigating Data Security and HIPAA Compliance
When handling medical data, certain responsibilities cannot be ignored. In the world of medical data annotation, security and regulatory compliance are not just best practices; they are the absolute bedrock of any trustworthy AI project. Failures in this area can lead to serious legal penalties, shatter patient trust, and derail promising initiatives before they begin.
At the heart of these duties, especially in the United States, is the Health Insurance Portability and Accountability Act (HIPAA). HIPAA sets the national standard for protecting sensitive patient health information (PHI) from being disclosed without a patient's consent. For any team building healthcare AI, following HIPAA is a legal and ethical imperative.
The Critical Role of Data De-identification
Before a single label is applied, the raw medical data must be made safe. This happens through a careful process called de-identification, where every piece of personally identifiable information is stripped out or masked. The goal is to make it impossible to trace the data back to an individual, protecting their privacy while keeping the data clinically valuable for AI training.
Key identifiers that must be removed include:
- Names, addresses, and any specific dates tied to a person.
- Medical record numbers, Social Security numbers, and other unique IDs.
- Any other information that could reasonably be used to identify an individual.
This is much more than a simple "find and replace" operation. It demands a deep understanding of data structures and privacy laws to ensure no residual PHI is left behind. Only after the data is fully de-identified is it considered safe to hand over to an annotation team.
Protecting patient data is not an obstacle to innovation; it is a prerequisite. A project built on a weak compliance foundation is destined to fail, no matter how sophisticated its AI.
Partnering with an ISO 27001 Certified Provider
While HIPAA defines what data to protect, international standards like ISO/IEC 27001 define how an organization should manage its information security. Choosing a vendor that holds this certification is a strong signal that they take security seriously. An ISO 27001 certified partner like Prudent Partners has proven they have a systematic, repeatable approach to managing sensitive information.
This certification means your annotation partner has built and maintains a comprehensive Information Security Management System (ISMS). This system governs everything they do with your data, including:
- Secure Data Transfers: Using encrypted channels to move data between systems.
- Strict Access Controls: Ensuring only authorized personnel can see or touch sensitive data.
- Regular Risk Assessments: Proactively identifying and fixing potential security vulnerabilities.
By vetting a partner’s security framework from the start, you ensure your project is built on a secure and ethical foundation. Engaging with expert teams for your business process outsourcing in healthcare provides that essential layer of compliance and security assurance. It frees up your team to focus on building great AI, confident that the data operations are managed with the highest standards of care.
How to Build a High-Accuracy Annotation Workflow
Achieving medical-grade accuracy does not happen by accident. It is the direct result of a disciplined, structured, and repeatable workflow. Think of this process as your best defense against costly errors and rework that can derail a healthcare AI project. Building it right means moving deliberately from foundational preparation to multi-layered quality assurance.
The real work begins long before the first label is ever applied. It starts with careful data preparation and the creation of crystal-clear annotation guidelines. These guidelines are the single source of truth for the entire project, eliminating ambiguity and ensuring every annotator works from the same rulebook.
This whole process is powered by a team of experts working in sync. It brings together project managers who monitor timelines, skilled annotators who perform detailed labeling, and clinical experts, like radiologists or pathologists, who provide indispensable medical context. When technical execution is guided by deep domain knowledge, great outcomes are achieved.
The Core Roles of a Successful Annotation Team
A high-performing annotation team is more than just a group of people; it is a cohesive unit where every role is clearly defined and connected. The best analogy is a surgical team where everyone from the lead surgeon to the scrub nurse has a specific, vital function.
The key players in this process usually include:
- Project Manager: This person is the orchestra conductor. They manage timelines, align resources, and act as the main point of contact, ensuring the project stays on track and meets its goals.
- Clinical Subject Matter Expert (SME): Often a radiologist, pathologist, or another medical professional, the SME is the source of clinical truth. They are instrumental in creating the guidelines and have the final say on complex or ambiguous cases.
- Lead Annotator: This is a senior, highly experienced annotator who trains the rest of the team, answers their questions, and often does the first pass on quality review. They act as the perfect bridge between the clinical expert and the annotation team.
- Annotators: These are the skilled professionals who handle the day-to-day labeling. They meticulously follow the guidelines to ensure every label is consistent and precise.
Tight collaboration between these roles is what separates a good project from a great one. When annotators have a direct line to clinical experts for quick clarifications, the quality of the final dataset improves dramatically.
Creating Crystal-Clear Annotation Guidelines
Ambiguity is the enemy of accuracy. Your annotation guidelines document is the constitution for your project; it needs to be exhaustive, clear, and packed with visual examples. A good set of guidelines anticipates edge cases and gives explicit instructions on how to handle them, leaving zero room for interpretation.
A great guideline document does not just tell annotators what to do; it shows them. Including numerous positive and negative examples is one of the most effective ways to ensure everyone understands the task perfectly.
This document should be a living resource, updated as new edge cases are discovered. Maintaining this central source of truth ensures that every label applied is consistent and meets the project's strict quality standards. This discipline is the secret to producing reliable data that powers dependable AI.
Measuring Quality with Inter-Annotator Agreement
So, how do you objectively measure if your team is on the same page? The answer is a crucial metric called Inter-Annotator Agreement (IAA). IAA calculates the level of agreement between two or more annotators labeling the exact same piece of data. A high IAA score is a strong signal that your guidelines are clear and your team is interpreting them consistently.
Running IAA checks at the start of a project is a powerful diagnostic tool. If agreement is low, it indicates the guidelines need tweaking or the annotators need more training. By catching these issues early, you prevent systemic errors from spreading through your entire dataset. You can also use our free Data Annotation Assessment to evaluate your current quality and pinpoint areas for improvement.
Implementing Multi-Layered Quality Assurance
Finally, a truly high-accuracy workflow depends on a multi-layered quality assurance (QA) process where data is reviewed at multiple stages. This systematic validation helps teams hit the 99%+ accuracy needed for clinical applications. A typical multi-layer QA process involves a review cycle where senior annotators and clinical experts check the work of the initial labelers. This catches errors and, just as importantly, provides feedback that helps the whole team improve over time.
Choosing the Right Annotation Tools and Technology
The right technology stack is a massive accelerator for medical data annotation projects. The right choice can deliver a huge boost in both speed and quality. Think of it like choosing a diagnostic instrument for a clinic; the tool has to be precise, reliable, and built for the specific job. Making that choice means understanding what is available and how the options align with your project’s unique demands.
Generally, annotation tools fall into three categories: open-source, commercial, and proprietary. Each comes with its own set of advantages and disadvantages, especially when operating within the heavily regulated world of healthcare.
Comparing Annotation Platform Types
Open-source tools are a great starting point for research teams or projects on a tight budget. They offer significant flexibility and are often free to use. The trade-off is that they can lack the dedicated support, advanced security features, and specialized functions needed when handling sensitive medical data at scale.
Commercial platforms are a step up, offering a much more robust solution. These tools are built for enterprise use, meaning they come with professional support, regular updates, and compliance features baked right in. They often bundle a suite of services that make project management and team collaboration much smoother.
Finally, you have proprietary platforms. These are the custom-built systems developed by an annotation service provider like Prudent Partners. They offer the ultimate in customization, allowing us to tailor workflows and features exactly to a client’s needs. For complex medical annotation, this level of precision ensures maximum efficiency and security.
The big shift we are seeing in medical data annotation is toward hybrid models that blend automation with deep human expertise. It is part of a broader move away from purely in-house teams toward outsourced, semi-automated services that deliver both scale and precision.
The market for healthcare data collection and labeling is expected to grow by $3.63 billion at a CAGR of 13.34% by 2032. This surge is fueled by the global AI annotation market, where data annotation services make up over 57.20% of the market share in 2024. Discover more insights about these healthcare data trends.
Mission-Critical Features for Medical Annotation
When you are vetting tools for a medical AI project, some features are simply non-negotiable. The platform needs to be more than just a labeling screen; it must be a secure, collaborative, and intelligent ecosystem designed for the complexities that come with healthcare data.
Here are the absolute must-haves:
- Native DICOM and NIfTI Support: The platform must handle standard medical imaging formats without issue. This ensures all metadata stays intact and lets annotators view images just as a clinician would.
- Integrated Security Measures: Look for platforms with solid access controls, data encryption, and audit trails. These are your best friends for staying compliant with regulations like HIPAA.
- Collaborative Tools: Annotation is a team sport. Features that enable real-time communication, version control, and smooth review cycles are essential for maintaining high quality, especially if your team is remote.
The Power of Automation and Model-in-the-Loop
Today’s best platforms are getting smarter, using AI-powered assistance to boost efficiency without sacrificing accuracy. One of the most powerful examples of this is model-in-the-loop (MITL) annotation.
Here is how it works: an AI model takes the first pass at labeling a medical image, perhaps by drawing an initial outline of a tumor. Then, a human expert, like an oncologist, steps in to refine that suggestion instead of starting from scratch.
This partnership between human and machine radically speeds up the annotation process. It lets your experts spend their valuable time on what matters most: verification and tackling tricky edge cases. This approach gives you the scalability of automation with the irreplaceable judgment of a clinical professional, making it a cornerstone of modern, high-quality medical data annotation.
Finding the Right Partner and Avoiding Common Pitfalls
Picking the right partner for your medical data annotation is one of the most important decisions you will make. It is a choice that can make or break your entire healthcare AI project. Think of your annotation partner not as a simple vendor, but as an extension of your R&D team; their work directly shapes the reliability and accuracy of your final model.
Making the right choice is not about finding the most persuasive sales pitch. It requires a methodical approach that digs deep into a potential partner’s real-world capabilities and ensures they are the right fit for your specific needs.
A Checklist for Vetting Annotation Partners
To compare partners objectively, you need a clear framework. Use this checklist to make sure their expertise truly aligns with what your project demands.
- Proven Medical Experience: Have they worked with your kind of data before? Whether it is DICOM files for radiology, massive whole slide images for pathology, or unstructured EHR text, ask for concrete proof. Case studies and project examples are non-negotiable.
- Airtight Quality Assurance: How do they guarantee accuracy? You are looking for a multi-layered QA process, not just a single check. Ask about their approach to Inter-Annotator Agreement (IAA) and, crucially, whether clinical experts are involved in the final review.
- Serious Compliance and Security: Protecting patient data is everything. Your partner must be fully HIPAA-compliant, but do not stop there. Look for ISO/IEC 27001 certification, which proves they have a formal, structured Information Security Management System in place.
- Scalability and Clear Communication: Can they grow with you? A good partner can handle your current volume and scale up as your needs expand. You also need to assess their project management style to ensure you will have a transparent, collaborative relationship.
Mitigating Common Project Pitfalls
Even with the perfect partner, things can go wrong. Being proactive about common traps is the key to keeping your project on track and hitting your goals. One of the biggest mistakes we see is poorly defined annotation guidelines. Ambiguity is the enemy of quality data. Your guidelines need to be exhaustive, packed with visual examples that cover every possible edge case.
Another frequent pitfall is not having enough clinical expertise on the labeling team. When annotators run into a gray area, they might make assumptions that bake systemic errors into your entire dataset. Your partner must have a workflow that gives annotators a direct line to subject matter experts for quick clarifications and final sign-offs.
Running a pilot project is a smart, low-risk strategy to assess a partner’s true capabilities. It allows you to test their communication, quality, and adherence to guidelines before committing to a large-scale engagement.
A pilot project tells you everything a sales deck cannot. It shows you how a partner handles feedback, manages deadlines, and most importantly, delivers the quality you need. This trial run is invaluable for building the confidence required for a long-term partnership.
By vetting partners carefully and getting ahead of common risks, you build a solid foundation for success from day one. You can start with a tailored consultation to see how our certified processes can support your project.
Frequently Asked Questions About Medical Data Annotation
Even after you have mapped out your workflow and picked your tools, some questions always pop up once a medical data annotation project gets rolling. Here are a few of the most common ones we hear, with straightforward answers to help you navigate tricky situations.
How Do You Handle Disagreements Between Annotators?
First, disagreements are not just normal; they are a good sign. When annotators do not agree, it usually means your guidelines have a gray area that needs to be addressed. The first step is to track this using an Inter-Annotator Agreement (IAA) score.
When a conflict comes up, the best move is to escalate it to a clinical subject matter expert (SME). Their decision becomes the ground truth for that specific case. More importantly, you use their feedback to update the annotation guidelines. This turns a simple disagreement into a way to make your entire process more accurate over time.
What Is the Biggest Challenge in Medical Annotation?
While data security is always a top priority, the single biggest challenge is getting consistent, high-quality labels at scale. Medical data is incredibly nuanced. Two expert radiologists can look at the same CT scan and draw slightly different conclusions.
The real challenge is turning that complex, intuitive clinical judgment into a black-and-white set of rules that a whole team can follow without fail across thousands of files. It is a huge undertaking that demands crystal-clear guidelines, ongoing training, and a serious QA process.
The only way to solve this is through tight collaboration between your annotation team and clinical experts. That partnership ensures the rules are not just clear, but also clinically sound.
Can Automation Replace Human Annotators?
Not entirely, and in high-stakes medical AI, it probably never will. Automation is a fantastic assistant, but it is not a replacement for human expertise. Tools that use model-in-the-loop (MITL) annotation can dramatically speed things up by having an AI take the first pass at labeling.
But here is the key: a qualified human expert always needs to be in the loop to review, correct, and sign off on what the AI suggests. The future of medical data annotation is a hybrid approach. AI does the heavy lifting, freeing up clinicians and expert annotators to focus on the tricky edge cases and final quality checks. You get the speed of a machine combined with the critical judgment of an expert.
Ready to build a reliable, scalable, and compliant annotation workflow for your healthcare AI project? The experts at Prudent Partners are here to help you turn complex medical data into high-quality, AI-ready datasets.
Schedule a tailored consultation with Prudent Partners today to discuss your specific needs and launch a successful pilot project.