
Ever wonder how a self-driving car sees a pedestrian or how a smart speaker understands your voice? The magic behind it all is perception artificial intelligence. This is the technology that gives machines the ability to interpret raw sensory data from cameras, microphones, and advanced sensors like LiDAR and make sense of the world around them.
Instead of just processing numbers in a spreadsheet, these systems learn to recognize objects, understand context, and make intelligent decisions based on what they perceive. This guide provides a practical overview of how perception AI works, its real-world applications, and the critical role of high-quality data in achieving scalable, accurate results.
What Is Perception Artificial Intelligence

Perception AI is a field focused on building systems that can process and interpret information from the physical world, much like humans do. Just as our senses let us navigate a room or hold a conversation, perception AI uses digital sensors to capture data and sophisticated algorithms to understand what it all means.
This capability is the engine driving many of today's most advanced automated systems. From autonomous vehicles navigating chaotic city streets to medical software that spots tiny anomalies in diagnostic scans, perception AI is what translates complex, real-world inputs into clear, actionable insights.
To make this clearer, let's break down how a perception system works using a simple analogy.
How an AI Perception System Works
This table illustrates the core stages, comparing the AI process to how a human perceives and reacts to their environment. This structured approach is fundamental to building any AI system that interacts with the physical world.
| Component | Function in AI | Human Analogy |
|---|---|---|
| Sensing | Gathering raw data through devices like cameras (vision), LiDAR (depth), radar (motion), and microphones (sound). | Your eyes seeing a red light, your ears hearing a car horn. |
| Processing | Analyzing this raw data to identify patterns, features, and objects. | Your brain processing the visual signal of "red" and the sound of a "horn." |
| Interpretation | Applying learned knowledge to understand the context of the identified objects and their relationships. | Recognizing that a red light means "stop" and a car horn signals a potential hazard. |
| Decision-Making | Using this interpreted understanding to perform a task or make a recommendation. | You decide to press the brake pedal to stop the car. |
Each step builds on the last, turning a flood of raw data into a single, intelligent action.
The Foundation of Modern AI Systems
At its core, perception AI aims to replicate one of the most fundamental aspects of biological intelligence. For any AI to perform useful tasks in an unpredictable environment, it must first build an accurate model of that environment. This digital understanding is what separates a basic script from an intelligent agent that can react and adapt in real time.
However, the effectiveness of any perception model is entirely dependent on the quality of the data it learns from. An AI system cannot understand what a "pedestrian" is unless it has been trained on thousands of precisely labeled examples of pedestrians in different lighting, weather, and traffic conditions. This complete dependency on high-quality data is the single most critical factor in building reliable perception systems.
A perception AI model is only as accurate as the data used to train it. Inaccurate or inconsistent data annotation directly translates to poor real-world performance, creating massive risks in safety-critical applications like autonomous driving and medical diagnostics.
Why Data Quality Is the Biggest Hurdle
As more companies adopt AI, this challenge becomes impossible to ignore. Enterprise-level AI implementation is accelerating, with large companies reporting 87% adoption rates. These organizations are seeing real benefits, including 34% improvements in operational efficiency.
Yet, the primary obstacle remains the same across the board: data quality. It is a problem cited by 73% of organizations as their biggest barrier to success. You can explore the full research about AI adoption in enterprise statistics to see just how widespread this issue is.
This is where expert data annotation and quality assurance become non-negotiable. Without a rigorous, meticulous process to label, verify, and validate training datasets, even the most advanced algorithms will fail in the real world. Building a dependable perception AI system starts not with the model, but with the data that gives it sight and understanding.
Understanding the Senses of Modern AI

A perception AI system makes sense of the world using a suite of digital senses, not unlike how we use our own sight, hearing, and touch. Each sensor type captures a unique stream of data, offering a distinct layer of information about the environment.
When these streams are combined through a process called sensor fusion, the system achieves a rich, multi-dimensional understanding of reality that is far more powerful than what any single sensor could achieve on its own. These digital senses are the gateways that translate raw, unstructured reality into structured, machine-readable information.
Let's break down the primary senses that give modern AI its awareness.
Visual Data: The Eyes of AI
Cameras and video feeds are the most common sensory inputs, serving as the AI’s primary set of eyes. They capture rich information about color, texture, and shape, all fundamental for tasks like object recognition, facial analysis, and scene understanding.
Video also introduces the critical dimensions of motion and time, allowing an AI to track objects, analyze behaviors, and even predict actions. For example, a quality control system on an assembly line uses video to monitor processes, identifying defects in real time that would be missed by static images alone.
- Image Annotation: This is used to identify and classify objects within a single frame, like tagging products on a retail shelf for automated inventory management.
- Video Annotation: Here, we label objects or actions across multiple frames. It is essential for training models that analyze traffic patterns or monitor an assembly line for quality control.
Each of these tasks demands meticulous annotation. Without precise labels, the AI cannot learn to distinguish a stop sign from a speed limit sign or a routine action from a safety hazard.
Spatial and Depth Data: A Sense of the World
While cameras provide a 2D view, many applications need a true 3D understanding of space. This is where sensors like LiDAR (Light Detection and Ranging) and radar come in, giving AI a sense of depth, distance, and shape.
LiDAR works by shooting out laser pulses and measuring the reflections to create a detailed 3D point cloud of its surroundings. This is indispensable for autonomous vehicles, which need to precisely map their distance from other cars, pedestrians, and infrastructure.
Radar, on the other hand, uses radio waves to detect objects and their velocity. Its key advantage is that it works even in bad weather like fog or heavy rain where cameras and LiDAR might struggle, making it a crucial safety component in cars and drones.
Perception AI is not about a single, all-seeing sensor. True environmental awareness comes from sensor fusion, the process of intelligently combining data from multiple sources to create a unified, accurate, and resilient understanding of reality.
Auditory and Textual Data: Hearing and Reading
Microphones act as the ears for an AI system, capturing audio data that is vital for understanding human speech, identifying environmental sounds, and even diagnosing mechanical failures. A virtual assistant processes voice commands to set a timer, while an industrial AI might listen for subtle changes in machine vibrations that signal an impending breakdown.
Textual data is another key sensory input. AI models read and interpret massive amounts of text from documents, websites, and user inputs. The ability to extract meaningful information from unstructured text is central to countless business processes. You can see how this works by exploring our guide to optical character recognition software, which transforms scanned documents into usable digital text.
Each of these data types, from a 3D point cloud to a spoken command, requires a specialized annotation approach. Raw sensory input is just noise until it is meticulously structured, labeled, and validated. That is how you turn it into the high-quality fuel that intelligent systems need to learn.
How AI Models Actually Learn to See and Hear
Collecting data from sensors is one thing, but the real magic of perception AI is teaching a machine to make sense of it all. This is where specialized machine learning models come in. Think of them as the digital brain of the system, responsible for turning raw pixels, sound waves, and point clouds into actual understanding.
At its core, this learning process is all about pattern recognition. Just like a toddler learns to identify a cat after seeing dozens of them, an AI model is trained on huge, carefully labeled datasets. This training helps it build an internal "map" of the world and learn the telltale features that define different objects and events.
The Workhorse of Visual Perception: CNNs
When it comes to images and video, the undisputed champion is the Convolutional Neural Network (CNN). You can picture a CNN as a stack of increasingly specialized filters. The first filters look for simple things, and each subsequent layer builds on the last to find more complex patterns.
For instance, if an AI is learning to recognize a bicycle, the first layers of its CNN might detect basic lines and curves. The next layers would combine those to identify circles (wheels) and triangles (the frame). Finally, the top layers put all those pieces together to confidently label the object as a "bicycle." This layered, hierarchical approach is remarkably similar to how our own visual cortex works, which is why CNNs are so effective.
- Automatic Feature Detection: CNNs figure out on their own what features matter, whether it's the specific shape of a stop sign or the texture of asphalt on a road.
- Built-in Spatial Awareness: Their structure is designed to understand where features are in relation to each other, which is key for recognizing an object no matter where it appears in the frame.
- Efficiency: For visual tasks, they are far more computationally efficient than other neural networks, letting them process massive amounts of visual data quickly.
This powerful method is the foundation for everything from spotting tumors in medical scans to guiding self-driving cars. To get a better feel for how these systems work under the hood, you can dive deeper into the core algorithms for image recognition and see what powers modern computer vision.
Comparing Common AI Perception Models
With so many model architectures available, it helps to have a quick guide for matching the right tool to the right job. CNNs are fantastic for images, but other models like Transformers have become essential for processing sequences and understanding context across different data types.
This table breaks down some of the most popular models used in perception AI, outlining their best use cases, core strengths, and typical data needs.
| Model Architecture | Primary Use Case | Key Strengths | Typical Data Requirement |
|---|---|---|---|
| Convolutional Neural Networks (CNNs) | Image classification, object detection, segmentation | Excellent at spatial feature extraction, efficient for grid-like data (images) | Large, labeled image datasets |
| Recurrent Neural Networks (RNNs) | Time-series analysis, video processing, audio | Processes sequential data, remembers past information ("memory") | Labeled sequential data (video clips, audio files) |
| Transformers | Natural language processing, advanced vision tasks | Superior at understanding context and long-range dependencies | Very large datasets, often pre-trained on massive corpora |
| Graph Neural Networks (GNNs) | Social network analysis, 3D point cloud processing | Models relationships and connections between data points | Data structured as graphs or point clouds |
Choosing the right model is a critical first step. An architecture that is perfect for analyzing medical images might be completely wrong for interpreting conversational audio, so understanding these trade-offs is key to building a successful system.
Creating a Unified Worldview with Sensor Fusion
A single sensor gives you one slice of reality. But for a truly robust perception system, you need the whole picture. That is where sensor fusion comes in; it is the art of combining data from multiple sensors to create a single, far more reliable understanding of the world. It is like how you use both sight and sound to navigate a busy street; hearing a car horn makes you look around to pinpoint its location.
Sensor fusion is not just about piling on more data. It is about building a system where one sensor’s strengths cancel out another’s weaknesses. The result is a perception model that is more accurate, resilient, and trustworthy than the sum of its parts.
There are a few ways to fuse data, each with its own perks. An autonomous vehicle, for instance, might blend a camera's rich color data with a LiDAR's precise depth measurements and a radar's ability to see through fog and rain. By combining these feeds, the vehicle can confidently track a pedestrian on a dark, stormy night, a task that would be nearly impossible for any single sensor alone.
The Hidden Challenge of Multi-Modal Systems
Fusing different data streams is incredibly powerful, but it is also incredibly complex. Every single piece of data must be perfectly aligned in both time and space. Even a millisecond of lag between a camera frame and a LiDAR scan could cause the AI to misjudge an object's position, potentially leading to a catastrophic failure.
This is why perfectly synchronized and meticulously annotated datasets are non-negotiable. To train a sensor fusion model, you need data where an object, say, a passing motorcycle, is labeled consistently and accurately across the camera footage, LiDAR point clouds, and radar signals, all at the exact same moment. Without that level of precision, the model cannot learn the correct relationships between the different inputs, and the whole system falls apart. The quality of your data annotation is truly the bedrock on which these advanced perception systems are built.
The Unseen Engine Fueling Perception AI
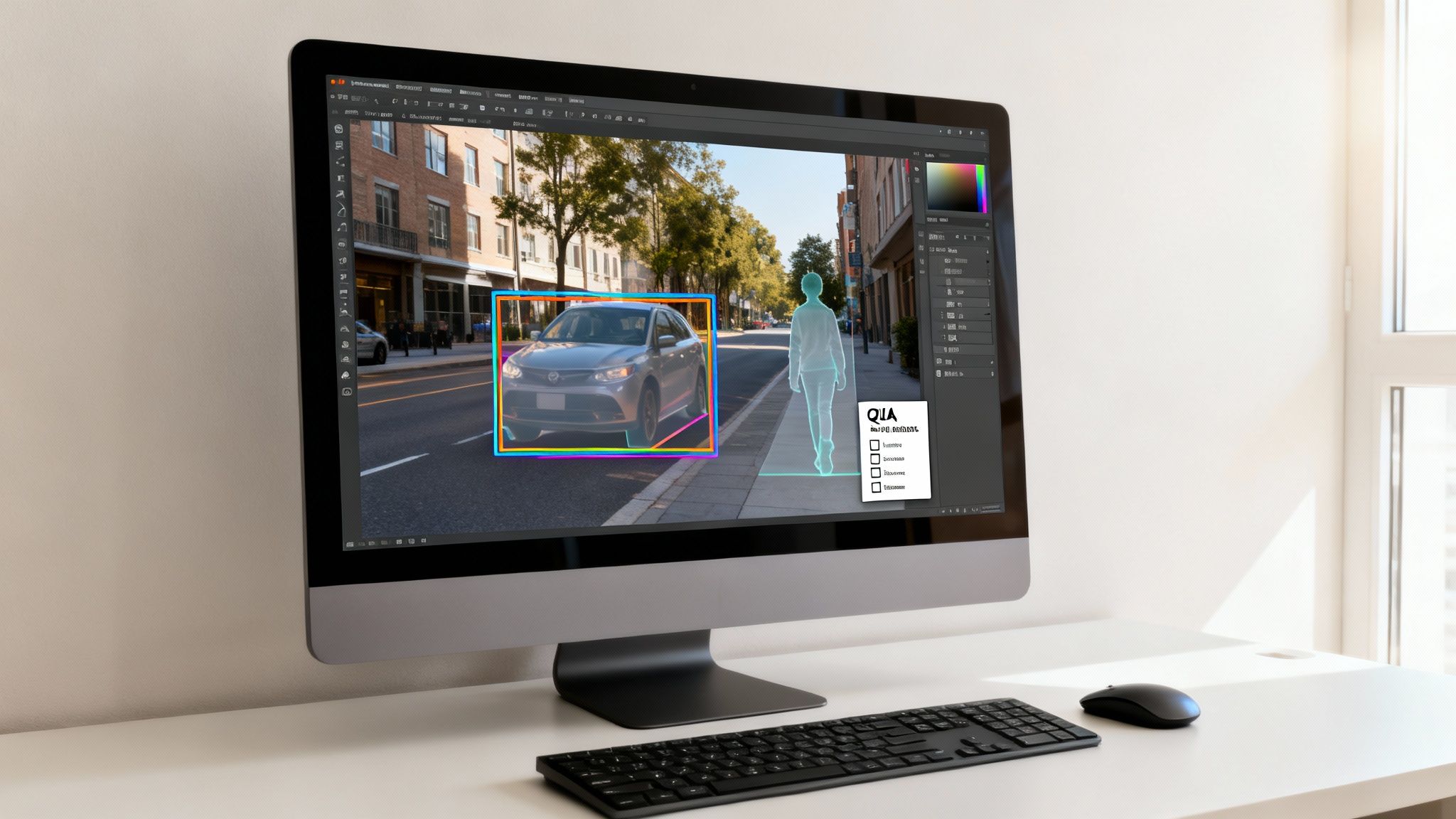
Even the smartest perception models are just quiet algorithms until you give them the one thing they need to learn: high-quality, accurately labeled data. This data is the real engine behind perception AI, turning a flood of raw sensor input into the structured knowledge a machine needs to make sense of the world. Without it, the algorithm has nothing to learn from.
This is not just theory; it is the hands-on, meticulous work of data annotation. It is a craft where precision, consistency, and a strict adherence to guidelines are everything. Every single label is a lesson, teaching the AI to spot patterns and make distinctions on its own.
The Craft of Teaching Machines to See
Data annotation is simply the process of adding descriptive tags to raw data. Think of it as creating a perfect answer key for the AI’s final exam. If that key is full of mistakes, the AI will learn all the wrong lessons.
The process involves a toolkit of specialized techniques, each built for a specific perception task or data type. Which one you use depends entirely on what you need your AI to see and understand.
For instance, a model built for an autonomous vehicle needs a totally different annotation approach than one designed for medical imaging. Three of the most fundamental techniques are:
- Bounding Boxes: This is the go-to method for object detection. Annotators draw a simple rectangle around an object of interest, like a car or a person, and give it a class label. It answers the basic question: "What is this, and where is it?"
- Semantic Segmentation: For a much deeper understanding, semantic segmentation classifies every single pixel in an image. Instead of just a box, this method traces the car's exact outline, separating it from the road, the sky, and everything else. This pixel-perfect detail is crucial for applications that need a rich contextual grasp of a scene.
- 3D Cuboids: When you are dealing with spatial data from sensors like LiDAR, 2D boxes just do not cut it. Annotators use 3D cuboids to capture an object's length, width, and height in a 3D point cloud, giving the model critical information on its volume and orientation.
Why Precision Is Non-Negotiable
The quality of this annotation work directly shapes how well the final perception artificial intelligence system performs. A slightly misplaced bounding box or an inconsistently labeled object can confuse the model, causing it to make dangerous mistakes in the real world.
The success of any perception AI project is not decided by how complex the algorithm is, but by the integrity of its training data. Expert annotation is not just a preliminary step; it is the foundation holding the entire system up.
Think about what is at stake. For a self-driving car, the difference between a correctly identified pedestrian and a mislabeled shadow can be a matter of life and death. In medical diagnostics, a precisely segmented tumor versus a sloppy outline can change a patient’s entire treatment plan. This is exactly why a multi-stage Quality Assurance (QA) process is not just a good idea; it is essential.
Guarding Against Errors and Bias
A robust QA workflow is your critical safeguard. It catches errors, enforces consistency, and helps root out hidden biases in the data. This usually involves multiple layers of review, where senior annotators or automated checks double-check the work of the primary team.
This disciplined approach ensures every label meets the project's strict accuracy goals, which at Prudent Partners, often top 99%. With AI adoption exploding, this commitment to quality has never been more critical. In less than three years, over 1.2 billion people have started using AI tools, and 35.49% of professionals now use them daily. As billions of people come to rely on AI, the annotations that power these systems have to be flawless. You can learn more about the staggering growth and impact of AI adoption statistics to grasp the scale of this responsibility.
Ultimately, expert annotation services are the bridge between raw data and reliable AI. They provide the structure, clarity, and quality needed to build perception systems that we can trust to perform accurately and safely, every time.
Perception AI in Action Across Industries
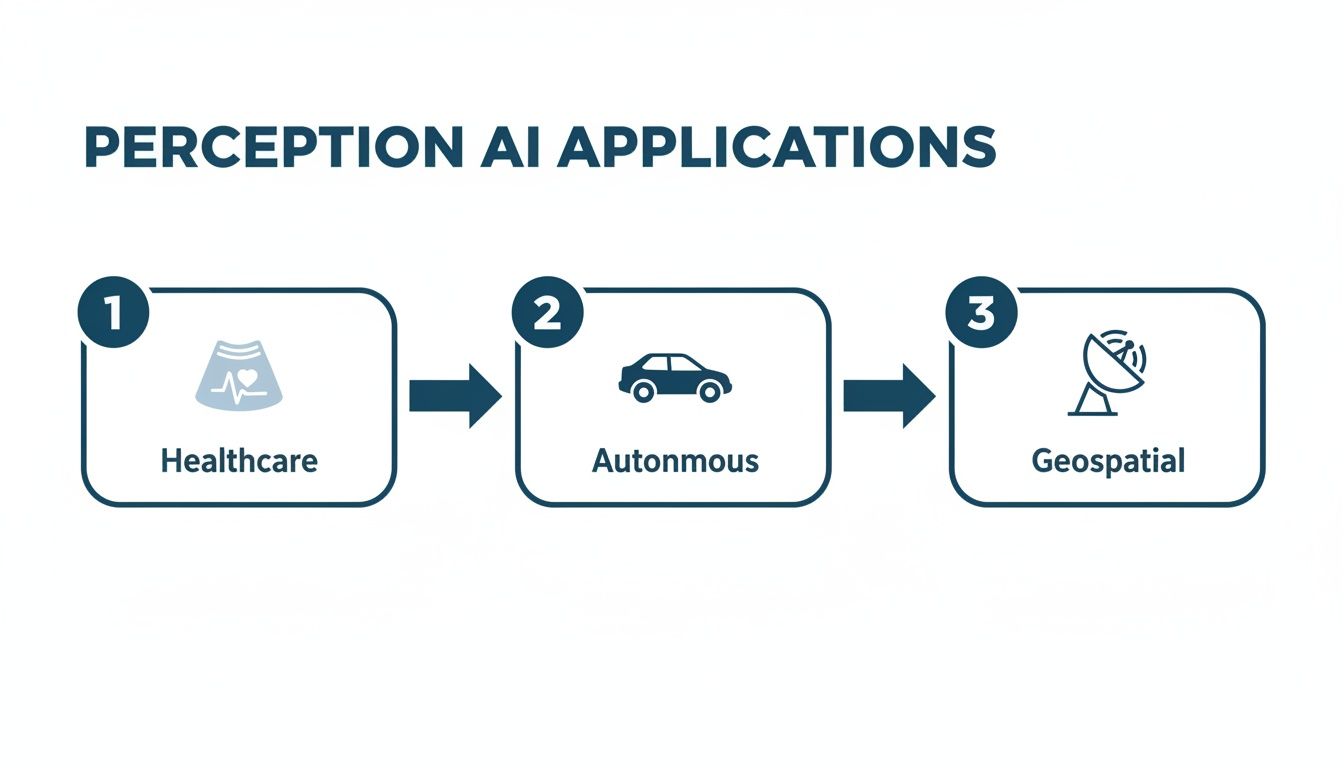
Theory is valuable, but seeing perception AI solve real-world problems is where its impact becomes clear. Let's move past the abstract and look at specific examples where this technology is not just an innovative concept, it is driving measurable business outcomes.
Each of these scenarios breaks down a specific operational challenge, the perception models used to tackle it, and why high-quality data annotation is the non-negotiable foundation for success.
Enhancing Safety in Autonomous Systems
Self-driving cars have to navigate a world that is messy and unpredictable. A split-second error can be catastrophic, especially when visibility is poor. One of the biggest hurdles is reliably seeing what is happening in low light or bad weather, where a single sensor can easily be fooled.
This is where sensor fusion becomes a lifesaver. Picture a car driving down a poorly lit city street at night. Its perception system needs to tell the difference between a person walking their dog and someone riding a bike along the curb.
- Business Challenge: The vehicle must reliably detect and classify vulnerable road users in low-visibility conditions to avoid accidents.
- Technology Applied: The system combines data from two different sources. High-resolution cameras capture color and texture, while LiDAR point clouds provide a precise 3D map of shapes and distances. Fusing them together creates a complete picture that compensates for the weaknesses of each sensor alone.
- The Annotation Imperative: To make this work, human annotators must label everything meticulously in both the 2D camera images and the 3D LiDAR data. The key is ensuring the "cyclist" label is perfectly synced across both data streams. This precision is what teaches the AI that a particular combination of visual cues and 3D shape represents a single object, allowing it to make safer decisions. Without that flawless annotation, the fusion model simply cannot learn correctly.
Improving Diagnostics in Healthcare
In medicine, perception AI is giving clinicians a powerful new tool for diagnostic imaging, helping them spot tiny anomalies the human eye might overlook. Take prenatal care, where ultrasound scans are essential for monitoring fetal development and catching potential health issues early.
By training AI models on huge, expertly annotated medical datasets, healthcare providers can create a powerful diagnostic assistant. The system acts as a second set of eyes, flagging potential areas of concern for an expert to review, ultimately improving patient outcomes.
An AI model can be trained to analyze these scans, compare them against thousands of healthy examples, and highlight even minor deviations from normal anatomical structures.
- Business Challenge: Increase the accuracy and speed of prenatal screenings by automatically flagging potential developmental issues in ultrasound images.
- Technology Applied: A Convolutional Neural Network (CNN) is trained on a massive dataset of annotated ultrasound scans. The model learns to perform semantic segmentation, outlining key fetal organs and structures pixel by pixel.
- The Annotation Imperative: The success of this AI lives or dies by the quality of its training data. Medical experts or highly trained annotators must painstakingly segment every critical structure in thousands of images. This is not just tracing lines; it requires deep domain knowledge. An inaccurate label could cause the AI to miss a critical finding or, just as bad, raise a false alarm.
Strengthening Geospatial Intelligence
When a natural disaster like a hurricane or wildfire hits, emergency responders and insurance adjusters need to know the extent of the damage fast. Manually sifting through thousands of square miles of satellite imagery is far too slow when every minute counts. Perception AI radically speeds up this process.
- Business Challenge: Rapidly assess damage to buildings and infrastructure across a large area using post-disaster satellite imagery to prioritize repairs and process insurance claims.
- Technology Applied: An AI model is trained to analyze high-resolution satellite photos, using object detection to find damaged buildings, flooded roads, and downed power lines.
- The Annotation Imperative: To train this model, you need a dataset where human annotators have carefully labeled examples of both damaged and undamaged infrastructure. If you're looking to build a dataset like this, you can explore our guide on how to build high-quality AI training datasets. These precise labels are what teach the model to recognize the visual signatures of different types of destruction, turning raw images into actionable intelligence for recovery teams.
Building a Scalable AI Perception Pipeline
Taking a perception AI system from a raw concept to real-world insight is a serious journey. A prototype is one thing, but engineering a pipeline that is accurate, dependable, and ready to scale requires a disciplined, strategic approach. This is our roadmap for building a perception system that actually delivers.
It all starts with picking the right sensors for the job. If you are building an indoor robot, a mix of cost-effective cameras and ultrasonic sensors might be perfect. But if you are engineering an all-weather autonomous vehicle, you will need a fused suite of cameras, LiDAR, and radar to guarantee safety in unpredictable conditions. Every choice you make here directly impacts data complexity, annotation needs, and your overall budget.
Establishing Unambiguous Data Annotation Guidelines
Once the data starts flowing in, the next make-or-break step is creating crystal-clear annotation guidelines. Think of these instructions as the single source of truth for your labeling team. They define exactly how every object, feature, or event gets marked. Ambiguity is the enemy here; vague rules create inconsistent labels, and inconsistent labels tank model performance.
Effective guidelines must include:
- Detailed Class Definitions: Clearly explain what makes something a "pedestrian" versus a "cyclist." Provide plenty of visual examples for both.
- Edge Case Protocols: What happens when an object is partially hidden? Or when you encounter a rare weather event? Your guidelines need explicit instructions for these tough calls.
- Visual Examples: A picture is worth a thousand words. Build a library of annotated images and videos to show your team exactly what "good" looks like.
These guidelines are not static. They need to evolve as your project uncovers new challenges, ensuring your data stays consistent as you scale. For teams building their own annotation capabilities, our in-depth guide to creating high-quality AI training datasets offers more practical advice.
Implementing Robust Quality Assurance
The only way to guarantee data integrity is with a rigorous, multi-stage Quality Assurance (QA) workflow. This process is your safety net, catching errors and making sure everyone sticks to the guidelines. At Prudent Partners, we often use a consensus or review-based system where multiple annotators or a senior reviewer validates every single label. It is how we hit accuracy rates that consistently exceed 99%.
This is also where you need to define and track the right metrics. For object detection, Intersection over Union (IoU) is the industry standard for measuring how well a predicted bounding box overlaps with the ground truth annotation. By tracking IoU and other key metrics, you get a clear, quantitative picture of both your data quality and your model’s progress.
Partnering for Scalable Success
As you scale, you will inevitably run into challenges like data drift, where your model's performance starts to slip as real-world conditions change. Getting through these hurdles often requires a partner with deep expertise in data operations.
It is also critical to understand how AI is perceived globally. Public opinion varies wildly by region; while 83% of people in China view AI positively, that number is just 39% in the United States. Discover more insights about global AI perception from the Stanford AI Index to better understand how local concerns might shape the adoption of your technology. An experienced data partner helps you navigate these data hurdles, ensuring you can build and scale perception AI solutions that are not just accurate but also build trust.
Frequently Asked Questions About Perception AI
As AI perception systems move from the lab into the real world, teams on the ground often run into the same practical questions. Here are a few of the most common ones we hear, along with some straight answers based on our experience.
What is the Single Biggest Hurdle in Building Perception AI?
It is always the data. Always.
While flashy new model architectures get all the attention, the truth is that their performance is completely capped by the quality of the data they are trained on. You can have the most advanced algorithm in the world, but if you feed it poorly labeled, biased, or inconsistent data, you will get a mediocre model. It is the classic "garbage in, garbage out" problem, but on a massive scale.
Fixing this is not easy. It requires a rock-solid data annotation and QA pipeline, usually involving expert human annotators and several layers of review. The goal is simple but challenging: create a dataset that is clean, consistent, and truly representative of what the model will see in the wild.
How Do You Actually Measure if a Perception Model is Accurate?
"Accuracy" is not a single number; you need to look at a few key metrics depending on the task.
For object detection, the industry standard is Mean Average Precision (mAP). It is a powerful metric because it does not just check if the model correctly identified an object (like a car). It also measures how well the predicted bounding box overlaps with the actual object.
For segmentation tasks, where you are labeling every pixel, Intersection over Union (IoU) is king. It calculates the percentage of overlap between the model's predicted mask and the ground-truth annotation. Beyond these, teams also rely on metrics like precision, recall, and the F1-score to get a full picture.
But the most important rule is this: you must evaluate your model on a completely separate test dataset it has never seen before. That is the only way to get an honest look at how it will perform in the real world.
Why Is Fusing Data From Multiple Sensors So Important?
Relying on a single sensor is like trying to navigate a busy street with one eye closed. Multi-modal sensor fusion is critical because it gives the AI a far more complete and reliable picture of its surroundings.
Consider these examples:
- A camera is great in perfect daylight but is practically blind in heavy fog or at night.
- LiDAR gives you incredibly precise 3D depth maps but cannot read a street sign or tell a red car from a blue one.
- Radar is a champion in bad weather, cutting right through rain and snow, but its resolution is much lower than a camera's.
By fusing the data from all three, an AI system can use the strengths of one sensor to cover the weaknesses of another. This creates a resilient, layered understanding of the world, which is absolutely non-negotiable for safety-critical applications like autonomous driving.
At Prudent Partners, we specialize in building the high-quality, meticulously annotated datasets that power accurate and reliable perception AI systems. Our expertise in data annotation, AI quality assurance, and scalable workflow management ensures your models are built on a foundation of trust and precision. Contact us to discuss your project and learn how our expert data annotation and quality assurance services can help you achieve your goals.