
Imagine teaching a machine to see an image not just as a collection of pixels, but as a detailed map of objects and their context. That is the heart of semantic image segmentation. Think of it as a sophisticated digital coloring book, where an AI assigns a specific category like ‘road’, ‘person’, or ‘building’ to every single pixel in a picture.
Unlocking Pixel-Perfect Understanding
Semantic image segmentation goes far beyond simply drawing a box around something; it meticulously outlines the exact shape and boundaries of every object. The output is a pixel-perfect “mask” that helps machines understand the world with incredible detail. This is the foundational technology that powers the next generation of AI, from self-driving cars navigating complex city streets to medical tools that identify tumors with pinpoint accuracy.
The process essentially transforms a raw image into a structured, machine-readable map where each color represents a distinct class. In a photo of a city street, for example, all pixels belonging to cars might be colored blue, all pedestrians red, and the road surface gray.
By classifying every pixel, semantic segmentation provides a far more granular and contextually aware understanding of a scene than other computer vision techniques like object detection, which only identifies an object’s general location with a bounding box.
This level of detail is non-negotiable for applications where precise boundaries and exact shapes are everything.
The Evolution of Scene Perception
The journey of semantic image segmentation has been a story of rapid advancement, moving from early theories to hyper-accurate deep learning models. The real turning point came around 2014 with the introduction of Fully Convolutional Networks (FCNs), which enabled direct, end-to-end pixel-level predictions from images for the first time. Since then, architectures like U-Net and DeepLab have pushed accuracy even higher. On industry benchmarks like Cityscapes, state-of-the-art performance has soared from 60-70% to over 90% in just a decade.
Why Pixel-Level Accuracy Matters
The true power of this technology lies in the precision it enables. But to train these powerful models, you need equally precise data. This is where creating pixel-perfect labels, a core component of expert image annotation services, becomes absolutely essential.
High-quality annotation is what teaches a model to distinguish between subtle but critical differences, such as:
- Differentiating the edge of a sidewalk from the road surface for an autonomous vehicle.
- Precisely outlining the margin of a tumor in a medical scan for an accurate diagnosis.
- Identifying individual crop rows in satellite imagery to monitor plant health.
Ultimately, this technology gives machines a nuanced understanding of a scene that starts to mirror human vision. That capability drives real, tangible improvements in safety, efficiency, and data-driven decisions across every industry.
Exploring Core Segmentation Architectures
To really understand semantic image segmentation, you have to look under the hood at the deep learning models that make it all happen. These architectures are the engines that turn a chaotic mess of pixels into a structured, meaningful map. By tracing their evolution and learning their unique strengths, you get a much clearer picture of how this technology actually works in the real world.
Think of computer vision as a journey toward deeper understanding. It starts with classifying a whole image, moves to identifying individual objects, and finally lands on the pixel-perfect detail you get with semantic segmentation.
This hierarchy is why pixel-level classification is considered the most granular form of computer vision. It is the foundation for any application where absolute precision is a must.
The Groundbreaking Fully Convolutional Network (FCN)
The story of modern segmentation really kicks off with the Fully Convolutional Network (FCN). Before FCNs came along, most neural networks designed for image classification ended up flattening the image data in their final layers. This process crushed all the crucial spatial information, the “where”, that tells you how pixels relate to each other.
FCNs changed the game by ripping out those dense layers and replacing them with convolutional ones. Suddenly, a network could make a prediction for every single pixel in the original image.
This was a massive breakthrough. For the first time, you could train a model end-to-end for pixel-level tasks, feed it an image of any size, and get a corresponding segmentation map that preserved all the spatial relationships.
U-Net and Its Symmetrical Elegance
Building on the foundation laid by FCNs, U-Net introduced a distinctive and wildly effective architecture, named for its classic ‘U’ shape. The model works with two main paths: a contracting path (the encoder) that captures the broad, contextual information in the image, and a symmetric expanding path (the decoder) that painstakingly reconstructs a full-resolution output.
But the real magic is in its “skip connections.” These act like information highways, bridging the encoder and decoder. They pipe high-resolution feature maps from the contracting path directly over to the expanding path.
This elegant design allows U-Net to fuse deep, contextual understanding with precise, localized detail. It’s fantastic at preserving fine-grained boundaries, which has made it a dominant force in medical imaging for tasks like outlining tumors and organs where every single pixel counts.
DeepLab and the Power of Atrous Convolutions
As models got deeper, a new problem cropped up: how to see the bigger picture without shrinking the image and losing resolution. The DeepLab family of models cracked this puzzle with a clever trick called atrous convolution, sometimes known as dilated convolution.
Imagine a normal convolution looking at a pixel and its immediate neighbors. Atrous convolution works by adding gaps into the filter, letting it sample from a much wider area of the image while using the same number of parameters. This lets the model grasp context at multiple scales without blurring the details.
- Wider Context: It sees more of the image without downsampling, which is a huge help when classifying large objects.
- Resolution Preservation: The model avoids aggressive pooling, so the feature maps stay large and detailed.
- Boundary Refinement: Combining multi-scale information results in much sharper and more accurate object boundaries.
This approach has made DeepLab models incredibly successful for messy, complex scenes like those in autonomous driving, where telling the difference between a pedestrian, a cyclist, and a signpost of varying sizes is a matter of safety.
To properly feed these advanced models, you need meticulously labeled data. Here at Prudent Partners, our expertise in BPM and virtual assistant services allows us to manage the complex annotation workflows required to create these high-stakes datasets.
Comparison of Key Semantic Segmentation Architectures
To bring it all together, here is a quick comparison of the major architectures we have discussed. Each brought a unique innovation to the table, making it better suited for certain types of problems.
| Architecture | Core Concept | Key Advantage | Typical Application |
|---|---|---|---|
| FCN | Replaces dense layers with convolutional layers for end-to-end pixel prediction. | The first model to enable end-to-end training for segmentation on images of any size. | Foundational work for modern segmentation tasks. |
| U-Net | Symmetrical encoder-decoder with “skip connections” to fuse context and detail. | Exceptional at preserving fine details and sharp object boundaries. | Medical imaging (tumor, organ, and cell segmentation). |
| DeepLab | Uses atrous (dilated) convolutions to capture multi-scale context without losing resolution. | Achieves a large field of view while maintaining high spatial resolution. | Autonomous driving and complex street scene analysis. |
Understanding these differences is key to choosing the right tool for the job. A model that excels at medical scans might not be the best choice for parsing a busy city street, and vice versa.
Distinguishing Semantic and Instance Segmentation
Finally, let us clear up a common point of confusion: the difference between what we have been discussing and the task performed by models like Mask R-CNN. Both operate at the pixel level, but they have fundamentally different goals.
- Semantic Segmentation: This is all about categories. It assigns a class label to every pixel. For example, it will label every pixel belonging to a car as “car,” lumping them all into one big group.
- Instance Segmentation: This takes it one step further. It does not just classify each pixel; it also distinguishes between individual instances of the same object. It would identify “car 1,” “car 2,” and “car 3” as three separate things.
Mask R-CNN is an instance segmentation model. Its strategy is to first detect all the objects in an image with bounding boxes, and then generate a pixel-perfect mask for each one. This is a far more complex task, perfect for applications like counting individual items in a warehouse or tracking specific cars on a highway, where telling one object from another is the whole point.
Real-World Applications and Business Impact
Any advanced technology is ultimately measured by its real-world impact. For semantic image segmentation, the leap from theory to tangible business outcomes is already reshaping entire industries. This is not just an academic exercise; it is a practical tool that delivers the pixel-perfect understanding needed for critical, high-stakes applications where mistakes are not an option.
The technology’s power lies in its ability to classify every single pixel, creating an incredibly detailed map of an environment. This unlocks a level of scene understanding that was previously out of reach, laying the foundation for safer, smarter, and more efficient automated systems that create clear business advantages.

Revolutionizing Autonomous Driving and Mobility
In the world of autonomous vehicles, semantic image segmentation is non-negotiable. For a self-driving car to navigate safely, it must understand its surroundings with absolute precision. This goes far beyond just putting a box around another car. The system needs to know the exact boundary of the drivable road, the specific shape of a pedestrian, and the precise location of every lane marking.
Segmentation provides this critical context by creating a dynamic, pixel-level map of the scene. This allows the vehicle’s decision-making system to:
- Identify drivable paths: By segmenting the road surface from sidewalks, curbs, and shoulders, the car can plot a safe course.
- Detect vulnerable road users: The exact shape and outline of pedestrians and cyclists are identified, letting the vehicle predict their movements and maintain a safe distance.
- Navigate complex weather: It can help differentiate a wet road from standing water or snow, improving performance in adverse conditions.
The business impact is direct and substantial, leading to enhanced vehicle safety, reduced accident rates, and faster development of higher-level driving automation.
Advancing Medical Imaging and Diagnostics
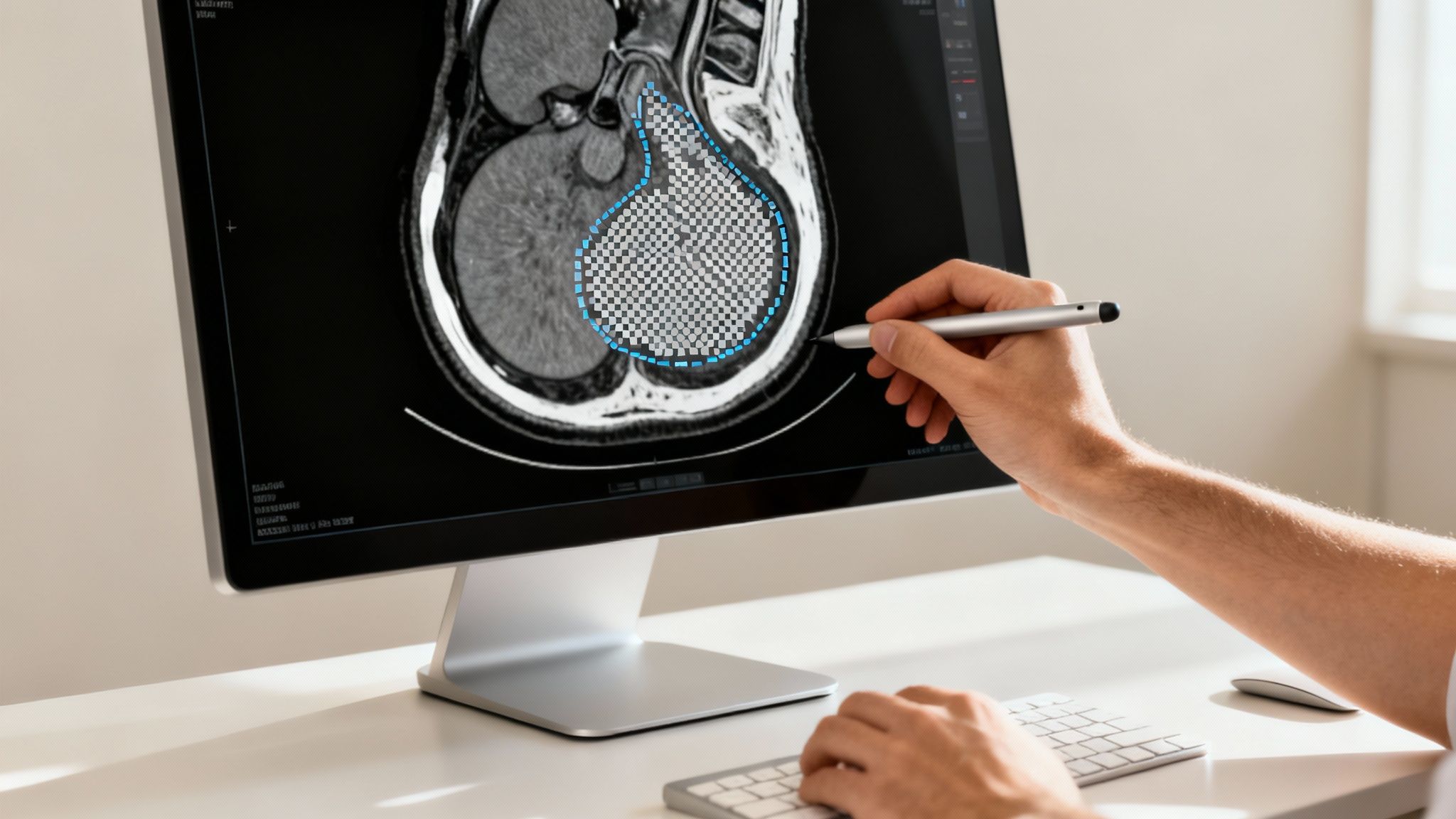
In healthcare, precision can be the difference between a successful treatment and a poor outcome. Semantic image segmentation gives medical professionals a powerful tool for analyzing complex scans like MRIs, CTs, and X-rays with incredible detail. By automatically outlining organs, tissues, and abnormalities, it transforms diagnostic and surgical planning workflows.
This technology acts like a skilled assistant, tirelessly and accurately outlining critical structures pixel by pixel. This frees up clinicians’ time, reduces diagnostic variability, and provides quantitative data for better-informed medical decisions.
Key applications in the medical field include:
- Tumor Delineation: Accurately segmenting tumors and their margins is vital for radiation therapy planning, ensuring treatment targets cancerous cells while sparing healthy tissue.
- Organ Segmentation: Isolating organs like the heart, liver, or kidneys allows for precise volume measurements and better surgical planning.
- Cell Analysis: In pathology, segmentation can automate the counting and analysis of cells in microscope images, speeding up research and diagnostics.
This improved accuracy and efficiency translate directly to better patient outcomes and more streamlined clinical operations.
Transforming Agriculture and Environmental Monitoring
Beyond roads and operating rooms, semantic image segmentation is making a huge impact from a bird’s-eye view. When applied to satellite and drone imagery, it provides invaluable insights for precision agriculture and environmental science. By classifying vast areas of land pixel by pixel, analysts can monitor changes and manage resources like never before.
For instance, in agriculture, models can tell the difference between crops, weeds, and bare soil. This allows for the targeted application of herbicides and fertilizers, which reduces costs and environmental impact. You can learn more about how Prudent Partners supports these applications through our specialized satellite object annotation services.
In environmental monitoring, segmentation is used to track deforestation, map flood plains, and monitor the health of ecosystems. The ability to quantify land use changes over time provides critical data for conservation efforts and policymaking. These capabilities are fundamental to massive global markets, with the AI in medical imaging market alone projected to reach $10 billion by 2030.
The Critical Role of High-Quality Data Annotation
Even the most powerful semantic image segmentation model is only as good as the data it is trained on. While sophisticated architectures like U-Net and DeepLab get a lot of attention, their success comes down to one thing: meticulous data annotation.
High-quality data is not just a box to check; it is the strategic core that determines your model’s performance, reliability, and real-world value.
Creating the high-resolution, pixel-perfect masks required for training is a tough, labor-intensive job. It demands incredible precision, deep domain knowledge, and a relentless focus on consistency. This is where the theory of AI smacks right into the messy reality of implementation.
Navigating Annotation Challenges
The annotation process is riddled with traps that can sink your model’s accuracy if you are not careful. Even with the best tools, human judgment is still at the center of it all, and with that comes subjectivity and the risk of error. A successful project needs a solid plan to tackle these common hurdles head-on.
Key challenges in semantic image segmentation annotation include:
- Defining Ambiguous Boundaries: How do you draw a perfect line around a cloud, wisps of hair, or the leaves on a tree? These objects do not have hard edges, forcing annotators to make consistent judgment calls across thousands of images.
- Maintaining Absolute Consistency: Every single person on your annotation team must follow the exact same rules. If one person labels a shadow as part of a car while another does not, you are just injecting noise and confusion into your model.
- Managing Labor Intensity: Pixel-perfect annotation is slow work. It requires intense focus. For a large dataset with thousands of high-resolution images, the sheer volume can be overwhelming, leading to fatigue and a drop in quality.
These factors make it clear why data quality is the real competitive edge in AI. An annotation process without rigorous oversight and a multi-layered quality assurance system will inevitably produce a weak model, no matter how clever the algorithm is.
The Strategic Value of a QA Pipeline
To get ahead of these issues, building a strong quality assurance (QA) pipeline is not just a good idea; it is essential. This is much more than a quick final review. It is a system woven into the entire annotation workflow, designed to systematically catch and fix errors before they can poison your training data.
Think of high-quality data as the clean, refined fuel for your AI engine. Poorly labeled or inconsistent data is like contaminated fuel; it will cause the engine to sputter, underperform, and eventually fail when it matters most. The investment in data purity pays dividends in model reliability.
A truly effective pipeline needs several layers of verification. This often kicks off with automated checks for common mistakes, followed by peer reviews where annotators check each other’s work against the project guidelines. The final layer usually involves a senior or expert review, especially for tricky or ambiguous images. This structured approach creates a culture of precision and accountability.
Efficient and scalable annotation workflows are the backbone of any serious AI initiative. By treating data annotation as a critical, ongoing process, not a one-off task, you can ensure your semantic segmentation models are built on a foundation of trust and accuracy, ready to deliver real impact.
Measuring Success and Overcoming Common Hurdles
Building a great semantic segmentation model is not just about the algorithm. It is about knowing how to measure what “good” looks like and being ready for the inevitable curveballs the real world will throw at your model. Without a clear way to grade performance and a plan to fix common failures, even the most promising model will stumble once it leaves the lab.
The real test is not just high scores on a benchmark dataset; it is reliable performance in the wild. That means getting comfortable with key metrics and knowing how to tackle messy, unpredictable scenarios before they become a problem.
Defining and Measuring Model Accuracy
So, how do you actually know if your model is working? The industry standard is a metric called Intersection over Union (IoU), sometimes known as the Jaccard Index. Think of it as a simple grading system for how well your model’s prediction overlaps with the “ground truth” mask created by a human.
It is a straightforward concept. IoU takes the area where the predicted mask and the ground truth mask overlap, then divides it by the total area covered by both masks combined. A perfect score is 1.0 (a perfect match), while 0.0 means the model completely missed the object.
To get a single, powerful number representing your model’s overall performance, we use mean IoU (mIoU). This is just the average IoU score across all the different object classes in your dataset. In the competitive world of AI research, an mIoU of 85% or higher is often what top-tier models achieve.
Navigating Common Failure Points
Here is the thing: even a model with a stellar mIoU score can fail spectacularly in specific, crucial situations. Figuring out these potential weak spots early is the key to building a system you can actually trust. Unsurprisingly, most of these problems trace right back to the data you trained it on.
Common challenges that trip up even the best models include:
- Rare Object Recognition: Models are lazy learners. If they only see an ambulance or a specific type of construction vehicle a few times in training, they will struggle to identify it later.
- Adverse Conditions: Performance often nosedives in bad weather. Heavy rain, dense fog, snow, or even just poor lighting can make familiar objects look alien to the model.
- Inconsistent Object Appearances: A “truck” can be anything from a small pickup to a massive semi-trailer. Models can have a hard time generalizing when an object category includes a wide variety of shapes, sizes, and colors.
Getting past these issues means going beyond a standard training loop. It requires a more strategic approach to make your model truly resilient.
Proven Solutions for Robust Models
Successfully deploying a segmentation model means you have to plan for these failures from day one. The fix almost always comes down to smarter data strategy, improving the quality and diversity of your training set and locking in a rock-solid validation process.
A model’s real-world performance is a direct reflection of the diversity and quality of its training data. Simply collecting more data is not enough; the key is to strategically address gaps and imbalances to prepare the model for the complexities it will face after deployment.
Here are three battle-tested strategies for building more reliable models:
- Strategic Dataset Balancing: If your model is failing on rare classes, the answer is to balance your dataset. You can either go out and collect more examples of those underrepresented objects or use techniques like oversampling, where you intentionally show the model more images of rare classes to give them more importance during training.
- Aggressive Data Augmentation: To prep your model for messy, real-world conditions, data augmentation is your best friend. This technique programmatically creates new training images by altering the ones you already have. You can simulate rain or fog, tweak the brightness and contrast to mimic different lighting, or rotate and scale objects. It is a powerful way to build a more diverse dataset without having to manually label thousands of new images.
- Rigorous Quality Assurance (QA): This is the most critical step. Implementing a multi-layered AI quality assurance pipeline is non-negotiable. This process ensures that annotation mistakes, inconsistencies, and class imbalances are caught before they poison your model. A strong QA workflow is your safety net, guaranteeing the data you are using is accurate and aligned with your goals. As the experts at Lightly AI point out, annotation consistency is a massive challenge, which makes a structured QA process absolutely essential.
Partnering for Enterprise-Grade Segmentation
Getting semantic segmentation right at an enterprise scale is a serious puzzle. It is not just about picking a fancy AI model; it is about weaving together state-of-the-art algorithms, streamlined operational workflows, and exceptionally high-quality annotated data into a system that actually works in the real world.
Without a holistic approach, even promising projects hit walls. They run over budget, miss deadlines, and end up with underperforming models that fail when it matters most. This is where a strategic partnership can make all the difference, bridging the gap between a cool prototype and a reliable, production-ready system.
Building Your Scalable Annotation Engine
At the end of the day, a great segmentation model is only as good as the data it is trained on. This is our bread and butter. At Prudent Partners, we specialize in building and managing the large-scale data annotation pipelines that enterprise AI depends on. We combine advanced tools with highly trained analysts to produce the pixel-perfect masks your models need, ensuring every label is consistent and accurate across massive datasets.
Our process is built on a few key pillars:
- Customized Guideline Development: We sit down with your team to create crystal-clear annotation rules. The goal is to eliminate ambiguity so that every label meets your exact specifications, every single time.
- Multi-Layered Quality Control: No annotation gets a pass without going through our rigorous AI quality assurance workflow. This includes peer reviews and expert validation to catch errors long before they have a chance to compromise your model.
- Scalable Workforce Management: Whether you have a small pilot or a massive production pipeline, we can handle it. Our skilled teams, supported by our BPM and virtual assistant services, can manage projects of any size, letting you scale your data operations without the headache of building an in-house team.
A successful enterprise AI initiative is built on a partnership that understands both the technical and operational demands of high-quality data. The goal is to create a predictable, scalable, and accurate data engine that fuels continuous model improvement and delivers a clear return on investment.
From Data Quality to Business Value
Our job is to help you mitigate risks, ensure your projects can scale, and unlock a clear, measurable return on your AI investments. We provide the expertise and infrastructure needed to turn raw, messy data into a strategic asset.
By handling the complexities of data preparation and quality assurance, we free up your technical teams to do what they do best: developing and deploying groundbreaking models.
If you are ready to see how a customized data solution can fuel your semantic segmentation projects, connect with our team for a personalized consultation.
Got Questions? We’ve Got Answers.
Here are a few common questions that come up when teams start digging into semantic segmentation. We will give you the straight-up, practical answers you need.
What’s the Real Difference Between Semantic and Instance Segmentation?
Think of it this way. Semantic segmentation is all about categories. It looks at an image and paints every pixel belonging to the same class with the same color. So, all cars become one big “car” blob, and all pedestrians are part of a single “person” blob. It is great for knowing what’s in the scene.
Instance segmentation takes it a step further. It does not just see “car,” it sees “car 1,” “car 2,” and “car 3” as separate, distinct objects. It tells you what’s in the scene and counts each individual one.
How Much Labeled Data Do I Actually Need to Train a Model?
There is no magic number, and anyone who gives you one is guessing. The amount of data you need is tied directly to your project’s complexity and how accurate you need the model to be.
That said, for a production-ready model that performs reliably in the real world, you should be thinking in terms of thousands to tens of thousands of perfectly annotated images. Anything less is likely just for a proof-of-concept.
The good news is that techniques like data augmentation (creating new image variations) and transfer learning (starting with a pre-trained model) can help you get more mileage out of a smaller dataset.
What Are the Biggest Headaches in a Segmentation Project?
Honestly, it almost always comes back to the data. Building the model is often the easier part; getting the right training data is where the real work happens.
Here are the hurdles you will almost certainly face:
- The Sheer Cost and Time of Annotation: High-quality, pixel-perfect annotation is incredibly time-consuming and expensive. This is usually the biggest bottleneck for any team.
- Fuzzy Boundaries: How do you consistently label things with unclear edges, like wisps of hair, tree foliage, or reflections? You need rock-solid annotation guidelines to avoid confusing your model.
- Class Imbalance: It is easy to end up with a dataset that is 95% sky and road but only 5% pedestrians. This imbalance will train your model to be great at recognizing the common stuff but terrible at spotting the rare (and often most important) objects.
- Nailing Rare Objects: Getting a model to perform well on objects it has rarely seen is a constant battle. This requires a very deliberate and strategic approach to curating your data.
Navigating these challenges is exactly why a bulletproof AI quality assurance process is not just a nice-to-have; it is essential for getting a model that actually works.
Ready to build a reliable, scalable semantic segmentation pipeline? The expert team at Prudent Partners can help you navigate the complexities of data annotation and quality assurance to achieve your project goals. Connect with us today for a customized solution.