
Data annotation is the meticulous process of labeling raw data, transforming it into a format that machine learning models can comprehend. The primary types of annotation are tailored for distinct data formats, including images, video, text, audio, and 3D point clouds. Each format requires a specific labeling technique to effectively train a high-performing AI model.
The Blueprint for AI: How Annotation Teaches Machines to See and Understand
Before an AI can detect a defect on a manufacturing line, interpret the sentiment of a customer review, or guide a vehicle through a busy intersection, it requires a teacher. Data annotation serves as this fundamental teaching process.
Think of it as showing a child a picture book. You point to an image of a dog and say "dog," creating a direct link between the visual and the label. This simple action transforms an abstract image into structured, useful information. Annotation performs this exact function for machine learning (ML) models.
The quality of this labeling is the single most critical factor in building a reliable AI system. If the labels are inconsistent or inaccurate, the model becomes confused and delivers poor predictions. This is the classic "garbage in, garbage out" problem that can derail an entire project.
The Core Data Categories for AI
To build a high-performing AI, your annotation strategy must align with the type of raw data you are working with. Every data format presents unique challenges and demands a specialized approach. The main categories are:
- Image Data: This is the fuel for computer vision. It encompasses everything from everyday photographs and satellite imagery to highly specialized medical scans like MRIs.
- Text Data: This includes documents, social media posts, and customer feedback, all of which are essential for Natural Language Processing (NLP).
- Audio Data: Recorded speech, environmental sounds, and music fall into this category, used to train technologies like voice assistants and sound recognition systems.
This chart illustrates how raw, unstructured data is categorized into these primary formats before any AI development can begin.
This initial step of sorting your information is foundational. You cannot begin labeling until you have a clear understanding of the data you possess.
From Raw Data to Actionable Insights
The journey from a collection of raw files to a functional AI model is built upon precise, consistent labels. Each of the data types mentioned requires a different annotation method to become useful. For instance, labeling a street scene for a self-driving car is vastly different from the data tagging needed to analyze the tone of customer support communications.
The accuracy and scalability of your data annotation process directly determine the reliability and performance of your final AI model. It is the critical first step that dictates the ceiling for your model's potential.
Different business challenges demand different types of annotation. A project’s success hinges on selecting the right technique and executing it with meticulous attention to detail. This ensures the final dataset is a trustworthy source of truth for the machine, empowering it to make dependable decisions in real-world scenarios.
Annotating the Visual World: Image and Video Labeling
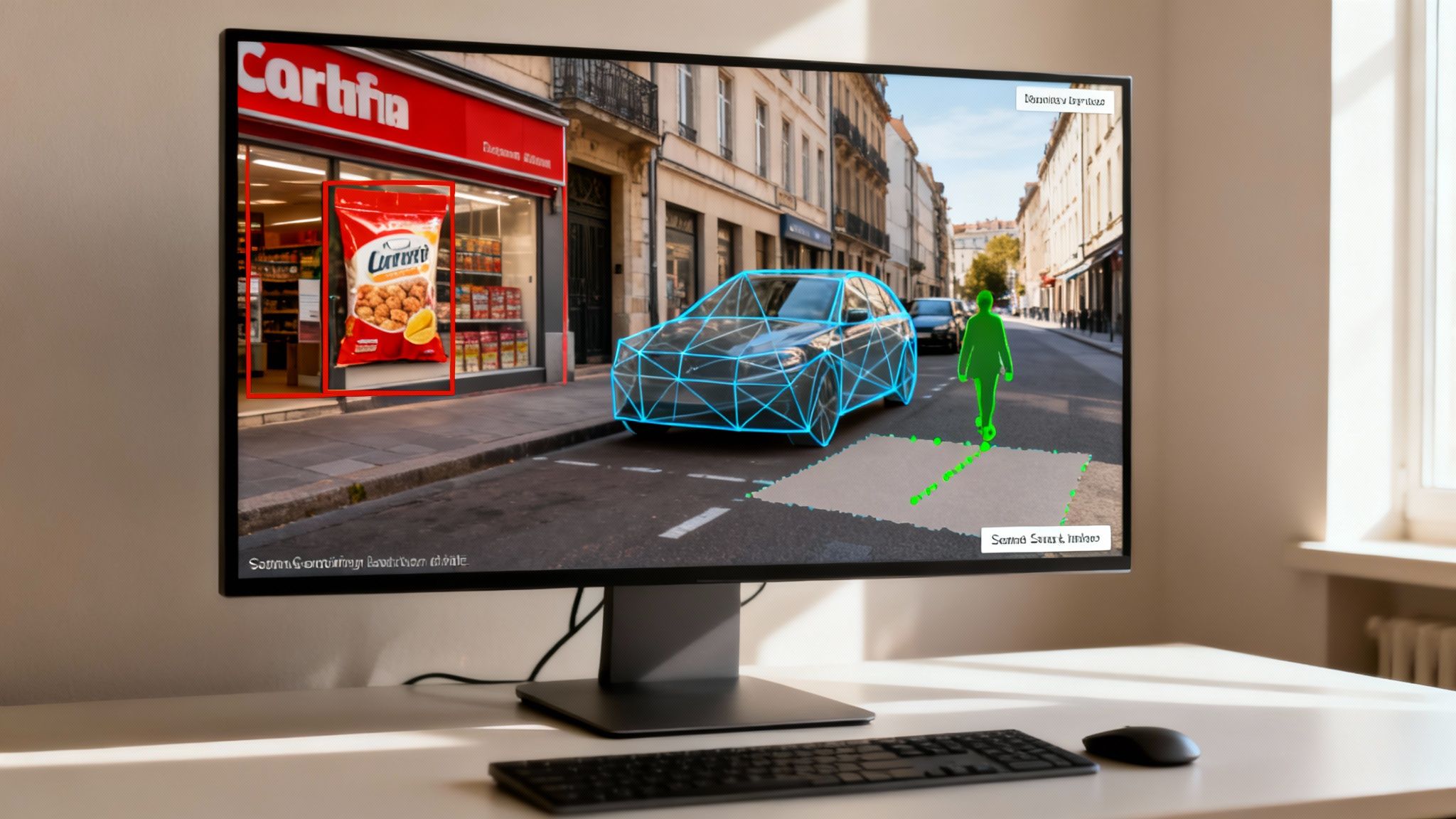
Visual data fuels countless AI innovations, from medical imaging systems that identify diseases early to retail platforms that manage inventory using cameras. However, for an AI to interpret a picture or video, it must first be taught what to look for. This is where image and video annotation provides the critical instructions.
Each labeling technique serves a distinct purpose and offers a different level of detail. The choice is not arbitrary; it directly shapes an AI's capabilities and its real-world performance. The required precision of the annotation directly impacts the model's final accuracy and reliability.
Bounding Boxes: The Workhorse of Object Detection
The most common and straightforward type of annotation is the bounding box. Imagine an e-commerce company training an AI to automatically identify every product in a user's uploaded photo. An annotator simply draws a rectangle around each item, like a pair of shoes or a handbag, and assigns a corresponding label.
This method is efficient and scalable, making it ideal for projects where the goal is to locate objects without needing to know their exact shape. It answers the fundamental question: "What is this, and where is it?"
Common applications include:
- Retail and E-commerce: Automatically detecting products in images for inventory management.
- Security: Identifying vehicles or individuals in surveillance footage.
- Manufacturing: Spotting products on a conveyor belt for quality control.
While fast, bounding boxes represent a trade-off. They are less precise because they include background pixels, which can be problematic when an AI needs to understand an object’s exact boundaries.
Polygons: Capturing Irregular Shapes with Precision
When an object's precise shape is critical, polygons are the preferred method. Instead of a simple rectangle, annotators use a series of connected points to trace the exact outline of an object. Consider an autonomous vehicle that must distinguish a pedestrian from a bicycle; those irregular shapes must be captured perfectly.
This technique requires more time and skill than drawing bounding boxes but provides a much higher level of detail. The AI learns the true contours of each object, leading to more accurate performance in complex environments where an object's specific form is non-negotiable.
The rise of image annotation for computer vision has been driven by large-scale labeled datasets and market investments. By 2023, the global data labeling market was estimated at roughly USD 3.2 billion and is projected to grow significantly, reflecting the massive demand in autonomous driving, retail, and medical imaging. For instance, datasets for autonomous vehicles often contain millions of annotated frames with accuracy targets exceeding 95% for critical objects like pedestrians, as model safety depends on it. Discover more about the growth of the data annotation market and its quality standards in this detailed analysis.
Semantic Segmentation: Pixel-Perfect Understanding
For the highest level of granularity, we use semantic segmentation. This advanced technique involves assigning a class label to every single pixel in an image. Instead of just outlining an object, it creates a complete map, differentiating between "road," "sky," "building," and "car" at the pixel level.
This type of annotation is incredibly powerful but also the most labor-intensive. It is essential for use cases where the AI must understand the entire context of a scene. Medical AI, for example, relies on segmentation to identify the precise boundaries of tumors or organs in MRI scans. You can explore our guide to understand more about how semantic image segmentation powers advanced AI.
Keypoint Annotation: Tracking Motion and Form
Finally, keypoint annotation, or landmark annotation, focuses on identifying specific points of interest on an object. This is not about the object's outline but its key features. In sports analytics, for instance, an AI might track an athlete's movement by annotating joints like elbows, knees, and hips.
Similarly, in facial recognition, keypoints mark the corners of the eyes, the tip of the nose, and the edges of the mouth. This annotation type enables AI to understand posture, movement, and facial expressions. The accuracy of these points is vital for building reliable systems that can interpret human behavior.
To help visualize how these methods compare, here is a quick breakdown of their strengths and best-fit applications.
Comparing Common Image Annotation Types
| Annotation Type | Primary Use Case | Complexity Level | Level of Precision |
|---|---|---|---|
| Bounding Boxes | General object detection (e.g., cars, products) | Low | Low |
| Polygons | Irregularly shaped objects (e.g., pedestrians, trees) | Medium | High |
| Semantic Segmentation | Scene understanding (e.g., autonomous driving, medical imaging) | High | Pixel-perfect |
| Keypoint Annotation | Pose and motion tracking (e.g., human joints, facial features) | Medium | High (point-specific) |
Choosing the right technique is the first step toward building a reliable computer vision model. Each method offers a unique balance of speed, cost, and detail, directly influencing how well your AI will perform its intended task.
Teaching AI to Read: Unlocking Insights with Text Annotation

How do chatbots seem to understand your questions correctly? Or how does your email platform identify which messages are spam? The technology behind these capabilities is text annotation, the process of labeling language to teach Natural Language Processing (NLP) models.
While image annotation teaches AI to see, text annotation teaches it to read and understand human language. The process transforms messy, unstructured text into a clean, structured dataset that machines can learn from. The goal is to decode the meaning, intent, and relationships hidden within the words.
However, human language is complex. It is full of ambiguity and context. A single word can have multiple meanings, and sarcasm can completely reverse the meaning of a sentence. This is why expert human judgment is absolutely essential for building NLP systems that can handle these nuances.
Identifying Key Information with Named Entity Recognition
One of the most foundational tasks in text annotation is Named Entity Recognition (NER). Think of it as a digital highlighter. Annotators scan through documents and tag important nouns with predefined labels, extracting the "who," "what," and "where."
These labels typically include:
- People: Tagging names of individuals.
- Organizations: Identifying companies, institutions, or government bodies.
- Locations: Highlighting cities, countries, or addresses.
- Dates and Times: Marking specific points in time.
- Products: Labeling brand names or models.
Imagine a financial firm using NER to automatically scan thousands of news articles. The AI could instantly extract company names and executive titles to flag market-moving events. This is how raw text becomes structured, actionable intelligence.
Classifying Content and Understanding Emotion
Beyond just identifying entities, text annotation helps AI understand the broader context and tone of a document. Two core techniques here are text classification and sentiment analysis.
Text classification is about assigning a category to a piece of text. For example, a customer support system could use it to automatically sort incoming tickets into categories like "Billing," "Technical Issue," or "Account Inquiry," routing them to the right person faster. A crucial first step in many classification workflows is turning scanned paper into digital text, a process you can learn more about in our guide to software optical character recognition.
Sentiment analysis takes this a step further, determining the emotional tone behind the words. Is a customer review positive, negative, or neutral? By labeling feedback and social media posts, businesses can gain a real-time pulse on public opinion and identify issues before they escalate.
The quality of text annotation directly dictates how well an NLP model performs. For complex tasks like NER and sentiment analysis, even human experts can disagree due to linguistic ambiguity. It is common to see inter-annotator agreement scores in the 0.6–0.75 range. Pushing past this to achieve gold-standard quality requires multiple layers of review and expert adjudication.
Uncovering Deeper Connections in Text
While NER identifies what is in the text, more advanced annotation reveals how those things are connected. Relationship extraction does exactly that, identifying the semantic links between different entities.
For instance, after NER has tagged "Apple Inc." and "Tim Cook," relationship extraction would establish their connection as "CEO of." This allows an AI to build a knowledge graph, understanding not just the players but the roles they play.
Another critical technique is coreference resolution. This involves linking all the words in a text that refer to the same person or thing. In the sentence, "Steve Jobs co-founded Apple. He was a visionary," coreference resolution connects "Steve Jobs" and "He" as the same entity. This is vital for helping an AI maintain context over long documents.
These more advanced annotation types require deep linguistic skills and often domain expertise, reinforcing why skilled human annotators are the key to building truly intelligent systems.
Exploring the Next Frontiers in Audio and 3D Annotation

As AI becomes more sophisticated, the data it needs to understand grows far more complex. We are moving beyond just images and text. The next frontiers are about teaching machines to hear the world through audio and perceive it in three dimensions. These advanced types of annotation require specialized tools and highly skilled teams to translate raw sensory data into a language machines can process.
This is the kind of data that powers some of today's most sophisticated AI, from conversational assistants that understand nuance to autonomous cars that navigate busy streets. The margin for error is razor-thin, and precision is paramount. Let us explore the key techniques pushing the boundaries of what AI can achieve.
Decoding Sound: Audio Annotation
Audio annotation is the foundation for any AI that needs to listen and respond. While transcription is the most common form, true auditory understanding goes far beyond just converting speech to text. It demands a deeper, more contextual level of labeling.
This is where more advanced tasks come into play.
- Speaker Diarization: This technique answers a simple but critical question: "Who spoke, and when?" Annotators go through an audio file, segmenting it and assigning a unique ID to each speaker. It is essential for creating clean transcripts of meetings with multiple people or for analyzing customer service calls to track the dialogue between an agent and a customer.
- Sound Event Detection: This involves identifying and timestamping specific non-speech sounds. For a home security system, this might mean labeling the sound of a "dog barking" or "glass breaking." It is how you teach an AI to react to its environment, not just to spoken commands.
These methods give AI a much richer understanding of the auditory world, requiring a keen ear and a meticulous approach to ensure every sound and timestamp is accurate.
Perceiving Depth: 3D Point Cloud Annotation
For technologies like self-driving cars and robotics, a flat, two-dimensional view of the world is insufficient. They need to see in 3D to understand depth, volume, and how objects are oriented. This is where point cloud annotation is indispensable.
Generated by LiDAR (Light Detection and Ranging) sensors, a point cloud is a massive collection of millions of individual data points that form a 3D map of an environment. Annotating this data is a highly specialized skill. Using sophisticated software, experts group these points together and label them as distinct objects.
This process is much like digital sculpting. Annotators must meticulously carve out every car, pedestrian, and traffic sign from a dense cloud of points to give an autonomous vehicle true three-dimensional awareness of its surroundings.
Defining Volume and Orientation with 3D Cuboids
Once objects are identified in the point cloud, the next step is often to enclose them in 3D cuboids. Think of these as three-dimensional bounding boxes that define an object’s length, width, height, and orientation in space.
Unlike a simple 2D box, a cuboid tells the AI not just where an object is, but its size, position, and the direction it is facing. This detail is absolutely non-negotiable for safe navigation. A self-driving car needs to know if the vehicle ahead is parallel or perpendicular to predict its next move. The accuracy of these 3D cuboids directly shapes the reliability and safety of the AI's decisions, making it a critical skill in building next-generation systems.
Finding the Right Partner for Your Data Annotation Needs
Understanding the different types of annotation is the first hurdle. The next, and often more significant, challenge is executing that annotation flawlessly and at scale. This is where many promising AI projects encounter difficulties. Deciding whether to build an in-house team or collaborate with a specialized partner is a strategic move that defines your project's timeline, budget, and ultimate success.
This decision extends beyond hiring people. It involves securing deep expertise, guaranteeing data security, and embedding a robust quality assurance framework from day one. Getting this right is how you transform raw, unstructured data into a high-performing AI model you can trust.
In-House Teams vs Specialized Partners
Building an in-house annotation team provides complete control. Your annotators can work closely with your data scientists, creating tight feedback loops and accumulating valuable institutional knowledge. However, this path comes with significant overhead, including recruitment, training, management, and the high cost of specialized software.
Scalability is another major challenge. For most companies, project demands fluctuate. Hiring a large team for a short-term project is impractical, and maintaining a full-time team during slower periods is inefficient.
Partnering with a specialist like Prudent Partners changes the dynamic. You gain instant access to a trained workforce, proven quality control systems, and the flexibility to scale up or down as needed. This approach converts a substantial capital expense into a predictable operational cost. A good partner also brings experience from dozens of other projects, offering insights that help you avoid costly mistakes.
Key Factors for Your Decision
When weighing your options, a few core business factors should guide your thinking. An honest assessment of these areas will quickly lead you to the right solution for your goals.
- Scalability: How quickly will your data volume grow? An external partner is structured to handle large datasets and can reallocate resources dynamically, a capability that is expensive and difficult to build internally.
- Cost Efficiency: Consider the total cost of ownership. An in-house team means salaries, benefits, office space, and software licenses. Outsourcing provides a clear, project-based cost that is almost always more economical at scale.
- Access to Domain Expertise: Does your project require niche knowledge, like interpreting medical scans or legal contracts? Partners often maintain teams with specific domain expertise, ensuring your data is labeled with the correct context and precision.
- Quality Assurance (QA): A rock-solid QA process is non-negotiable. Experienced partners have layered QA systems, such as consensus scoring, expert reviews, and performance analytics, to guarantee accuracy. At Prudent Partners, our approach to AI quality assurance is built around this very principle of meticulous, multi-stage verification.
A critical mistake many teams make is underestimating the sheer complexity of quality control. The best annotation services consistently achieve accuracy rates of 99% or higher. They do this by combining automated checks with multiple rounds of human review. That level of precision is what separates a model that works in a lab from one that performs reliably in the real world.
Essential Questions for Any Annotation Provider
If you decide to explore an external partnership, the vetting process must be rigorous. The right partner will be transparent, secure, and focused on delivering measurable results.
Here is a checklist of must-ask questions for any provider you consider:
- How do you measure and guarantee accuracy? Do not settle for vague answers. Look for clear metrics like Inter-Annotator Agreement (IAA) and a multi-stage QA process.
- What is your process for handling edge cases and ambiguous data? A great partner has a clear workflow for escalating confusing instructions back to your team for clarification, not just guessing.
- How do you ensure our data remains secure and confidential? Ask about certifications like ISO 27001, their NDA policies, and the physical and digital security measures they have in place.
- Can you provide annotators with specific domain expertise? For specialized projects, this is non-negotiable. It is the key to maintaining context and quality.
- What tools and platforms do you use? Ensure their technology stack is compatible with your data formats and internal workflows.
- How do you handle project communication and reporting? You should expect a dedicated project manager and regular performance reports that provide a transparent view of the work.
Getting solid answers to these questions will help you find a partner who acts as a true extension of your team, dedicated to turning your data into a powerful, dependable asset.
Common Questions About Data Annotation
As you begin to map out your AI project, questions will naturally arise. Teams often wonder about the practical differences between annotation types and how those choices impact their goals, budget, and timelines. Getting clear answers is key to making informed decisions.
This section addresses the most common questions we hear from teams navigating the world of data labeling. Each answer is designed to provide practical, real-world insights to help you build a solid data annotation pipeline.
What Is the Most Common Type of Data Annotation?
This question comes up frequently, but the answer depends entirely on your industry and the problem you are trying to solve. For years, bounding boxes were the undisputed workhorse of computer vision, powering countless applications in retail, manufacturing, and security. Their simplicity and speed made them the go-to choice for general object detection.
However, the landscape is shifting. With the incredible rise of large language models (LLMs) and conversational AI, text annotation is rapidly gaining prominence. Tasks like sentiment analysis and named entity recognition (NER) are now mission-critical for any business trying to understand customer feedback or automate document workflows. Therefore, the "most common" type is not a single industry standard; it is about selecting the right tool for your specific job.
How Does Annotation Quality Affect AI Model Performance?
Annotation quality is not just important; it is the absolute foundation of your AI model. The old saying "garbage in, garbage out" is the unbreakable law of machine learning. If your labels are inaccurate, inconsistent, or confusing, you are teaching your model the wrong lessons from the very beginning.
Think of it like building a house on a shaky foundation. It does not matter how brilliant the architecture is on top; the entire structure is compromised and will eventually fail.
It is no coincidence that a staggering 80% of AI projects never make it out of the pilot phase, and poor data quality is a primary culprit. Investing in a robust quality assurance process is not just an expense; it is a direct investment in your model's success and your project's ROI.
High-quality annotation creates a trustworthy "ground truth," which translates directly to higher accuracy, better performance on new data, and a model you can rely on in the real world. This is where meticulous oversight, like our virtual assistant services, can be invaluable for maintaining precision.
Can Data Annotation Be Fully Automated?
The dream of a fully automated, "push-button" annotation process is appealing, but for high-stakes, production-grade AI, we are not there yet. Automation is a fantastic accelerator, but it cannot replace the nuanced judgment and contextual understanding of a human expert. The data annotation market, as confirmed by reports from Grand View Research, still depends heavily on people to achieve the accuracy levels required for complex systems.
The most effective approach today is a human-in-the-loop (HITL) model. This hybrid workflow combines the best of both worlds:
- An AI model performs the first pass of "pre-labeling," quickly handling the easy, repetitive work.
- Human annotators then review, correct, and validate everything the AI did.
- This frees up your experts to focus their cognitive energy on the tricky edge cases and ambiguous examples that an automated system would almost certainly get wrong.
The HITL model perfectly blends the raw speed of a machine with the critical thinking and domain knowledge that only skilled humans can bring. It represents the right balance of efficiency and the uncompromising accuracy needed to build AI you can trust.
Ready to turn your raw data into a high-performance AI asset? The experts at Prudent Partners LLP are here to help. We provide precision data annotation services with a relentless focus on accuracy, scalability, and security. Connect with us today for a customized consultation and see how our tailored solutions can accelerate your AI initiatives.