
Think of data annotations as the lessons that teach an AI how to make sense of the world. Without these crucial labels, all that raw data, images, text, audio, is just digital noise. This makes high quality annotation the single most important step in building an AI you can actually trust.
The Hidden Teacher Behind Every Smart AI
Ever wonder how your smart speaker understands your commands or how a self driving car knows a stop sign from a speed limit sign? It's not magic. Behind every intelligent AI model is a hidden teacher: a meticulously annotated dataset.
Raw, unlabeled data is a language an AI cannot speak. It sees pixels in a photo or characters on a page, but it has no context to understand what any of it means.
The process is a lot like teaching a child to read. You do not just hand them a book and expect them to get it. You point to the letter 'A' and say "A," connecting the symbol to its meaning. Data annotation does the exact same thing for a machine, providing the contextual understanding necessary for learning.
- An image of a cat is just a jumble of pixels until a human annotator draws a box around it and labels it "cat."
- A customer review is just a string of words until it’s tagged with a sentiment like "positive" or "negative."
- A snippet of audio is just a waveform until a person transcribes the spoken words and identifies who is talking.
An AI's intelligence is a direct reflection of its education. The better the annotations, the smarter and more reliable the model becomes. This isn’t just a step in the process; it’s the foundation of the entire project.
This concept map shows just how central annotations are to turning raw data into a functional AI.
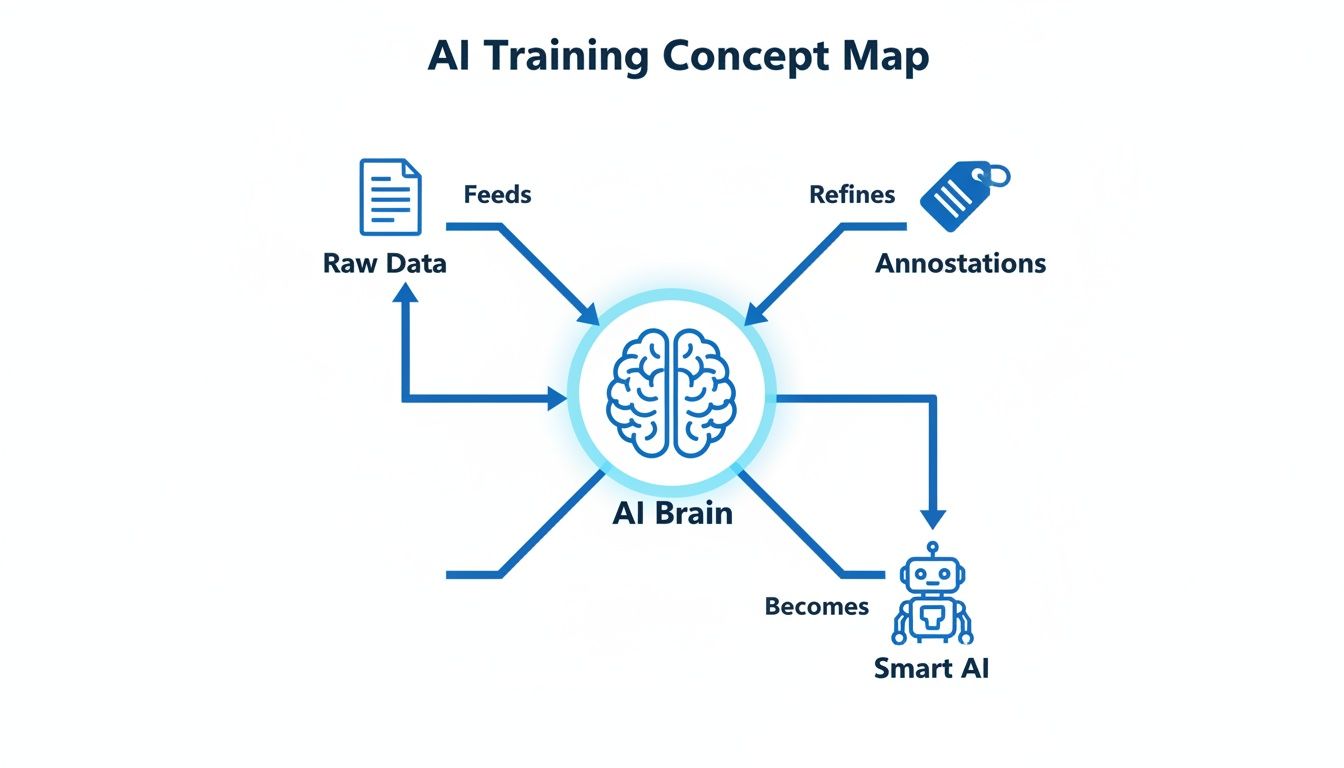
As you can see, annotations are the bridge. They provide the context that lets an AI "brain" process raw information and develop what we perceive as intelligence. This is why annotations are so critical; they turn abstract data into actionable knowledge, forming the bedrock of all machine learning.
How Quality Annotations Drive AI Accuracy
You have probably heard the old programming saying, "garbage in, garbage out." It perfectly captures the risk of using bad data to train an AI. But the real goal is not just avoiding garbage, it is about achieving quality in, intelligence out. High quality annotations are what turn raw, messy data into a reliable, high performing AI model. This is where the measurable impact of precision becomes clear.

Consider an autonomous vehicle. Its AI needs to distinguish a pedestrian stepping into a crosswalk from a shadow cast by a lamppost. Even a tiny mistake in labeling a few training images, for example misidentifying a person, can teach the model a fatal flaw. In this high stakes environment, precision is everything.
The same principle applies in medical AI. An algorithm designed to spot malignant cells on a pathology slide is only as good as the expert annotations it was trained on. If the boundaries of a cancerous region are drawn just slightly off, the model might learn to ignore subtle but critical warning signs, leading to a missed diagnosis.
The Real Cost of Inaccuracy
Small annotation errors do not just lower a model's performance score on a spreadsheet; they cause real, tangible failures in the world. Inaccuracy introduces risk and destroys the user trust you have worked so hard to build, which is why meticulous data annotation services are a critical investment, not a cost center.
It is no surprise that North America commands a leading 38.20% share of the AI annotation market in 2024. The world’s biggest tech hub understands how vital this process is. Annotated datasets have been shown to help AI models automate up to 70% of routine tasks in sectors like retail, directly connecting the dots between labeling accuracy and massive efficiency gains. Without precise annotations, models misclassify, make bizarre mistakes, and create huge operational headaches. You can read the full research about the AI annotation market to see its global impact.
From Consistency to Reliability
Building an AI you can count on boils down to two core principles in annotation: accuracy and consistency. They are the foundation of any system that needs to perform predictably, every single time.
- Accuracy: This is simple: are the labels correct? Is the object labeled "pedestrian" actually a person? Is the tumor boundary drawn precisely around the malignant cells?
- Consistency: This ensures the same rules are applied everywhere. If one annotator labels a partially hidden person but another ignores them, the model gets mixed signals and becomes confused.
Quality is not a one and done action; it is a continuous process. It demands clear guidelines, tough quality assurance, and expert annotators who get the nuances of the data. This commitment is what transforms a promising AI prototype into a dependable solution you can take to production.
Building Fairer AI by Mitigating Human Bias
An AI model can be technically perfect and still be dangerously biased. This paradox happens when the training data itself is a mirror of historical or societal prejudices, which teaches the AI to make discriminatory decisions. This is one of the most critical reasons why annotations are important: they are your first, and best, line of defense against baking bias into your algorithms.

When an AI learns from biased data, it does not just replicate those biases; it often amplifies them at a massive scale. The fallout can be devastating, impacting lives and reinforcing systemic inequity.
Think about a hiring algorithm trained on decades of résumés from a male dominated field. It might learn to systematically penalize applications from women, regardless of their qualifications. We have seen similar issues with facial recognition systems that historically show lower accuracy for women and people of color, simply because their training datasets lacked diversity. These are not just technical bugs; they are failures that start with the data.
Designing Annotation Guidelines for Fairness
The good news is that the annotation process gives you a direct way to intervene. It is your chance to consciously build fairness into the model’s DNA from day one. This goes beyond just labeling what is in the data; it requires a deliberate strategy to ensure your labels are equitable and context aware.
A few powerful strategies include:
- Diverse Annotator Teams: Bringing together annotators from different demographic backgrounds is huge. A diverse team can spot and challenge subtle biases that a more uniform group might completely miss.
- Bias Audits of Source Data: Before a single label is applied, take a hard look at your raw data. Are certain groups underrepresented? If so, you need a plan to source more inclusive data to balance things out.
- Context Rich Instructions: Your guidelines should explicitly tell annotators how to handle sensitive attributes. Instruct them to avoid making assumptions based on stereotypes.
The goal is to create a dataset that reflects the world you want your AI to operate in, not just the one that already exists. A thoughtful annotation strategy is how you steer your model toward fair and equitable outcomes.
Building fair AI is a tough but non negotiable task. It all starts with creating clear, thoughtful, and bias aware instructions for your annotation team. You can dive deeper by exploring best practices for developing comprehensive annotation guidelines that act as the ethical blueprint for your model.
By taking these deliberate steps during data labeling, you build an AI that works for everyone, not just a select few. This commitment is not just an ethical nice to have; it is a core part of building user trust and achieving long term success.
Meeting Compliance in Highly Regulated Industries
For companies in healthcare, finance, or aerospace, “good enough” is a recipe for disaster. In these highly regulated fields, one of the most compelling reasons why annotations are important is their non negotiable role in meeting strict legal and regulatory standards. Data annotation is not just a technical step; it is the creation of a verifiable, auditable trail that proves an AI model's decision making is sound, safe, and compliant.
This level of traceability is everything. Imagine a medical device company seeking FDA approval for an AI that analyzes MRI scans. Regulators will demand hard proof that the model was trained on accurately and consistently labeled data. Each annotation acts as a piece of evidence, showing the algorithm learned to spot tumors from expert verified examples, not from random chance or flawed inputs.
The Annotation Paper Trail
High quality, meticulously documented annotations are the very bedrock of transparent and trustworthy AI. They provide the clear "paper trail" that auditors and regulators need to validate a system's logic. Without it, an AI is essentially a black box, making it impossible to defend its conclusions or navigate legal challenges.
This accountability is just as crucial in finance, where an AI model for credit scoring or fraud detection must operate without bias and within tight regulatory frameworks. If the model denies a loan, the institution has to be able to explain why. Detailed annotations on the training data provide that explanation, showing how the model learned to weigh risk factors based on validated, compliant information.
The Soaring Demand for Compliant Data
The explosive growth of the global data annotation tools market shows just how urgent this need has become. In 2024, the market was valued at $1.9 billion and is projected to skyrocket to $6.2 billion by 2030. This surge is fueled by an insatiable demand for high quality labeled data, especially in regulated sectors.
In healthcare, where annotated datasets are pivotal for AI driven disease detection, the U.S. market alone hit $474.1 million in 2024. This growth makes one thing clear: precise, compliant annotation is no longer a nice to have; it is a core business necessity. Discover more insights about the global market for data annotation tools and its impact.
In high stakes environments, partnering with an annotation expert is a strategic business decision. It ensures that your AI is not only intelligent but also defensible, transparent, and ready for regulatory scrutiny.
This commitment to meticulous, auditable data labeling is what separates successful AI initiatives from those that crumble under regulatory pressure. It is about building systems that regulators, and ultimately your customers, can trust.
How to Scale Your Annotation Efforts Effectively
Labeling a few thousand images for a proof of concept is one thing. But scaling that up to annotate millions of data points without quality taking a nosedive? That is an entirely different beast. This is exactly where many promising AI projects hit a wall, stalling out long before they ever make it to production.
Successfully scaling your annotation is not just about hiring more people; it is a strategic decision. The big question is whether you should build your own in house team or partner with a managed service provider. Going it alone can seem appealing at first, but the hidden costs and complexities, recruitment, training, QA, and workforce management, add up fast.
Choosing Your Scaling Strategy
Building an in house team demands a huge upfront investment of both time and money. For most companies, those are resources better spent on core model development and R&D. That is why partnering with a specialized annotation service is often the smarter, more efficient path to getting the scale and accuracy you need.
Scaling annotation is not just about adding more people; it is about implementing a robust, repeatable system. This system must blend human expertise with smart technology to deliver consistent quality at high volume.
This is where human-in-the-loop (HITL) workflows really shine. In a HITL system, an AI model takes the first pass at labeling the data, and then human experts step in to review, correct, and validate its work. You get the speed of automation combined with the nuance and critical thinking that only a trained professional can provide. Our work with AI training datasets shows just how vital this synergy is for complex projects.
The Global Advantage of Outsourcing
Working with a managed partner also gives you access to a global talent pool. The Asia Pacific region is a great example; its data annotation market is projected to grow at an 18.5% CAGR through 2030, highlighting its central role in handling the world’s data explosion. India, in particular, stands out with its deep bench of cost effective, highly skilled labor. This allows companies to tap into top tier NLP and computer vision expertise at a fraction of what it would cost to build a similar team at home.
Choosing the right path to scale is a make or break moment in your AI journey. It is what determines whether your data pipeline can keep up with your goals or if it becomes the bottleneck that holds you back.
Choosing the Right Strategic Annotation Partner
Picking an annotation provider is not like buying a commodity. It is about finding a strategic partner who will directly influence your AI model's success, accuracy, and fairness. You have to look past the price tag and really dig into a partner’s technical skills, operational integrity, and how well you can work together.
The right partner gets it; they are not just labeling data. They are an extension of your AI development team. Their ability to give you clear, actionable feedback can improve your entire workflow, from data collection all the way through model training.
Key Evaluation Criteria
When you are vetting potential partners, zoom in on a few core areas. First, deep domain expertise is non negotiable, especially in tricky fields like healthcare or finance. In these areas, subject matter knowledge is everything. You need a partner who speaks your language and truly understands the subtle details in your data.
Next up is rigorous quality control. This is where many providers fall short. Ask them direct questions about their QA process:
- Multi Layered Review: Do they use a multi step verification process? This should include peer reviews and validation by experts to catch errors and keep the labeling consistent.
- Performance Metrics: How do they track annotator accuracy and efficiency? Look for transparent reporting and solid metrics like inter annotator agreement (IAA).
- Continuous Feedback Loops: Is there a formal system in place for annotators to ask questions? And just as important, for your team to provide clarifications? This ensures the guidelines are always getting better.
More Than Just a Service Provider
Ultimately, the best partnerships are built on strong communication and a shared commitment to your project's goals. Your provider should be a proactive problem solver, one who can scale up operations without letting the meticulous quality your model depends on slip through the cracks.
A true strategic partner does not just hand over labeled datasets. They provide the quality, security, and scalability you need to turn ambitious AI ideas into real world successes. They act as a trusted advisor, helping you navigate challenges and unlock the full potential of your data.
Finding a provider with a proven track record in high accuracy data annotation services is the final, crucial step. This ensures you are not just buying a service but investing in a partnership that will accelerate your journey to building a reliable and impactful AI system.
A Few Common Questions About Data Annotation
As you start planning your AI initiatives, a few key questions always seem to pop up. Let us tackle them head on to clear up any confusion and help you build a smarter data strategy.
What Is The Difference Between Data Labeling and Data Annotation?
People often use these terms interchangeably, but there is a subtle and important difference.
Think of data labeling as the simpler task. It is about applying a single, straightforward tag. For instance, classifying a customer review as "positive" or "negative" is a classic example of labeling.
Data annotation, on the other hand, adds much richer, more granular context. Instead of just flagging an MRI as "cancerous," an annotator might use semantic segmentation to trace the exact outline of a tumor. It is this high fidelity detail that complex models, especially in fields like medical imaging or autonomous driving, absolutely depend on.
How Is Annotation Quality Measured?
Great question. High quality is not just a gut feeling; it is measured with proven processes and metrics. The two most common methods are Inter Annotator Agreement (IAA) and Gold Standard Datasets.
- Inter Annotator Agreement (IAA): This is all about consensus. You have multiple human experts label the same piece of data independently. If they all arrive at the same conclusion, you know your guidelines are clear and your results are consistent. It is a powerful sign of reliability.
- Gold Standard Datasets: This involves creating a small, perfectly annotated set of data, often reviewed and signed off on by your absolute top experts. This "gold set" then becomes the benchmark you use to test the rest of the annotation team, quickly flagging anyone who needs more training.
Can AI Automate The Annotation Process?
Yes, but it is not a fully hands off process. AI assisted tools are fantastic for speeding things up by creating initial "pre labels" on raw data.
This is usually part of a human-in-the-loop (HITL) workflow. The AI does the heavy lifting, and then a human expert steps in to review, correct, and validate its work. This approach gives you the best of both worlds: the speed of a machine and the critical judgment of a person. For high stakes applications, that human oversight is non negotiable.
How Much Does Data Annotation Cost?
There is no single price tag. The cost comes down to a few key variables: how complex the data is, the accuracy you need, and the level of domain expertise required. Labeling simple product images for e-commerce is worlds away from annotating complex 3D medical scans, which requires a board certified radiologist.
The best way to think about it is not as a cost, but as an investment. Spending money on high quality annotation upfront is always cheaper than cleaning up the mess from a failed model, dealing with expensive rework, and losing the trust of your users.
Ready to build a robust foundation for your AI with high quality, scalable data annotation? Prudent Partners delivers precision driven solutions with verifiable quality assurance. Connect with our experts today for a customized consultation.